
Insights from recent episode analysis
Audience Interest
Podcast Focus
Publishing Consistency
Platform Reach
Insights are generated by CastFox AI using publicly available data, episode content, and proprietary models.
Most discussed topics
Brands & references
Total monthly reach
Estimated from 6 chart positions in 6 markets.
By chart position
- 🇳🇱NL · Technology#1811K to 10K
- 🇪🇸ES · Technology#1901K to 10K
- 🇨🇿CZ · Technology#623K to 10K
- 🇦🇷AR · Technology#873K to 10K
- 🇭🇺HU · Technology#155500 to 3K
- Per-Episode Audience
Est. listeners per new episode within ~30 days
2.7K to 14K🎙 Daily cadence·145 episodes·Last published 1w ago - Monthly Reach
Unique listeners across all episodes (30 days)
9K to 46K🇳🇱22%🇪🇸22%🇨🇿22%+3 more - Active Followers
Loyal subscribers who consistently listen
3.6K to 18K
Market Insights
Platform Distribution
Reach across major podcast platforms, updated hourly
Total Followers
—
Total Plays
—
Total Reviews
—
* Data sourced directly from platform APIs and aggregated hourly across all major podcast directories.
On the show
From 16 epsHost
Recent guests
Recent episodes
GLM-5.2 is the step change for open agents
Jun 22, 2026
9m 27s
Banning Open Source AI Would Be A Mistake
Jun 19, 2026
6m 50s
State of the blog, mid-2026
Jun 17, 2026
6m 19s
Frontier post-training recipe review with Finbarr Timbers
Jun 16, 2026
56m 36s
Claude Fable 5 and new AI safety fables
Jun 9, 2026
12m 11s
Social Links & Contact
Official channels & resources
Official Website
Login
RSS Feed
Login
| Date | Episode | Topics | Guests | Brands | Places | Keywords | Sponsor | Length | |
|---|---|---|---|---|---|---|---|---|---|
| 6/22/26 |  GLM-5.2 is the step change for open agents | Housekeeping: Following my “State of the blog” post last week, noting a slight increase in paid features, it’s a good time to remind folks that I offer group subscriptions with larger discounts proportional to the number of seats. I also released a new paper today on open RL recipes for terminal agents, read more here.A bit over a week ago, when the AI world was still reeling from the shocking export restriction, and effective banning, of Claude Fable 5, Z.ai released their latest model, GLM-5.2. This model was rolled out unusually on a Saturday, June 13th, to GLM Coding Plan members. This is an unusual release practice, normally when an AI model is released on a weekend it’s for a weird reason (most famously, Llama 4). In this case, it seemed like Z.ai was excited to capitalize on the zeitgeist of “Anthropic being anti open-science” with their silent safeguards on AI researchers. For the past year or two, the Chinese open-weight labs have taken every opportunity they have for easy marketing wins like this.GLM-5.2, in a common naming convention across the industry, looked potentially like an incremental update following the popular GLM-5.1 model. At this point, Moonshot AI, makers of the Kimi models, and Z.ai, makers of the GLM models, have consolidated the top of the reputational market with the most beloved open-weight models among AI researchers. What unfolded is a common lesson in tracking AI models that often minor version numbers can have AI models crossing meaningful user experience thresholds. A small change in benchmarks and training can open a wide range of new use-cases.What has followed is a slow, groundswell of hype for GLM-5.2. The official, MIT-licensed model weights and release blog dropped three days after the initial rollout, on June 16th. One could ramble many technical details, such as the strong benchmark scores, the very popular RL framework that Z.ai uses (SLIME), the recommendation of always using the model on Max thinking effort, and so on, but the initial release blogs usually aren’t the thing to focus on. You can wait and read the ecosystem reaction to know if it’s the real deal. Benchmarks are half dead these days, anyways.What followed on the 16th was a slew of community benchmarks showing better-than-expected results for GLM-5.2. Arena’s agent leaderboard had it as the only open model mixing it up with OpenAI and Anthropic’s latest models (notably matching Opus 4.8’s no-thinking effort to GLM-5.2’s max mode). This is one of many evals GLM-5.2 is crushing Gemini on, but that’s a topic for another time. A benchmark that has mixed perception in the community (particularly among actual designers), Design Arena even had GLM-5.2 besting Claude Fable itself — the recently banned hype machine!Pretty much everyone I respect among the AI commentariat and researcher class has praised the model after using it personally. Such a focal point of discussion among the community has only been so clear with an open model release once before — DeepSeek R1. This is not a comparison I make lightly, and when I compared Kimi K2’s release to a “DeepSeek Moment,” GLM-5.2 has well exceeded that. What made Kimi K2 impressive was that big steps in open model performance could seemingly come from anywhere in China. The step that GLM-5.2 has taken is more of a one way door for AI progress.Anthropic’s record revenue growth rate on the back of Claude Code is heavily driven by being the best model, and the only model that can really do this. GLM-5.2 is the first of many (coming soon) open weight models to offer credible alternatives. The parallel is very clear, to when DeepSeek R1 showed that open-weight labs, with far fewer resources, could also replicate the chain-of-thought reasoning models that OpenAI championed with o1. As AI systems get more complex and far more expensive to build, with tools, integrated harnesses, and scaled model weights, it was not a given that this GLM-5.2 moment would happen at all.The key point is that GLM-5.2 is the open weight model that feels right in coding harnesses as a general agent. It’s the first one. I was personally overdue in trying some of the recent peer models, such as Kimi K2.7 or GLM-5.1, but the hype was too much for me to ignore. I put it to work helping make content for my post-training course with Fireworks’ API in Claude Code (setting this up was very easy). There were some minor knife cuts, such as the Claude Code harness / my repo documentation trying to send images to the model, which would brick Fireworks API for the session — forcing a manual context clear. Overall, the model capabilities immediately felt right, and I still have some tinkering to do in which harness and inference provider to use. For more hype, you can sample the Z.ai founder telling Elon that “open-weight Fable capabilities will be here sooner than Q1 2027,” the CEO of Vercel saying “Genuinely impressed, almost shocked, at how good GLM-5.2 by @zai_org is at coding. This changes things,” and much more from a mix of people whose opinions I deeply respect and others I’m new to.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.So, this is a good model, where does this leave us?There are many trends at play. To start, let’s ground things in the open-closed capabilities gap. I’ve written how I expect an “explosion in usage” if open models crossed the Opus 4.5 in Claude Code threshold from around the start of 2026. Here we are. With Claude Opus 4.5’s release on November 24th, 2025, the gap in time to GLM-5.2’s release on June 16th, 2026 is 204 days — or about 6.8 months. This puts us square in the 6-9 month time gap that many people claim as the performance lag between the U.S.’s closed labs and China’s open counterparts.Upon writing this, I’m surprised. As the U.S. labs have so rapidly ramped compute in the last ~year, I’ve expected the gap in performance to grow in time. A very meaningful step in this trajectory will also be Claude Fable 5’s release — which was more reliant on scale, and therefore the most advanced GPUs, relative to the Claude Opus models. Still, that’s not a satisfactory answer. Continuing to unpack the trajectory here involves more nuance than I can afford to fit in a signposting article.The most immediate meaning of this is far more serious pricing pressure within the organizations tokenmaxxing, sending Anthropic’s revenue to the moon. Some would predict Anthropic doesn’t realize its forecasted ARR numbers, but I don’t think that prices in the true demand for these models and the inevitable growth. This model existing is a huge boon for the open model economy. All the likes of Fireworks, Together, Thinky (via Tinker), Prime Intellect, and whoever else sells open model inference or finetuning just hit another inflection point. It’ll take a long time for the effects here to diffuse into the broader economy (and use-cases). Workflows are becoming more complex, with people using different models for planning, primary coding, and subagent dispatch. I expect the hype to continue to grow, and heck, as I’m writing this on a Sunday evening, I could see the media and market reaction on the Monday being a thing just like the DeepSeek R1 release. This diffusion happening while Anthropic’s, and by extension the U.S.’s flagship model, is still banned is a severe economic dagger. GLM-5.2 is being given time to carve out the economic underbelly of the frontier labs when they want to be pushing forward into higher margin, higher revenue domains enabled only by the absolute frontier models.The economic concern mirrors a story that has been told many times in AI, so it’s unclear when it’ll stick.The conversation that feels more core to the trajectory of AI is that of regulation and control of open models. I think it is an economic good for cheap intelligence to diffuse widely, and our default position should be to cheer for open models, but this model’s release date will have it be permanently associated with Claude Fable — and therefore Claude Mythos — in the mental map of AI power structures. We are at a point where Mythos-class model capabilities are deemed not safe for release by the U.S. Government and the Chinese model makers are charging forward in capabilities available to all. These trend lines aren’t necessarily causally linked, as we don’t know the cyber performance of GLM-5.2 versus its predecessors, but the capabilities are definitely correlated. Without anything changing, this points to a potentiality where the U.S. Government decides a certain open-weights Chinese model is not safe for the public. There are many other potential scenarios here too, but what is clear is that we have a lot of work to do in mapping them out, preparing our infrastructure, and messaging to society. It’ll take a lot more people than just me to imagine and communicate a world to decision makers for how to manage evermore capable open models. We have years more of AI progress to come, with Nvidia’s next generation chips already in production and a constant stream of algorithmic advancements. It feels like a narrow path for open model advocates to take, but we need to figure out how to make them viable so the massive leaps in performance don’t only go to closed models. I totally see why it is scary to imagine an openly accessible Mythos class model, but if open models get banned now and only closed models get 10 or 100X better in 2 years in the hands of one or two companies, I think we will have bigger problems on our hands. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 9m 27s | ||||||
| 6/19/26 |  Banning Open Source AI Would Be A Mistake | This post was originally an op-ed co-authored with Kevin Xu of Interconnected for a general, non-technical audience. The gatekeepers — the many media outlets we pitched it to — passed on publishing it. Luckily, we have our own platforms to get the message out. Please help us forward this op-ed to any one you know who is on the fence about open source AI or new to the topic and want to learn more. Thank you.The energy to regulate AI is in the air in Washington. With the recently signed executive order to review AI models, a congressional proposal to legislate AI further, the government possibly taking shares of frontier AI labs, and last Friday’s action prohibiting foreign nationals anywhere from accessing Anthropic’s most advanced models, this may be the opening salvo of more AI regulation to come.We are afraid future actions could inadvertently or intentionally regulate or even ban open source, a much maligned and misunderstood topic in AI. That would be a grave mistake.Open source – simply a process that allows technology to be shared, built, and distributed publicly and transparently – is safe, secure, and drives economic growth. More than 90% of the world’s software was already built on open source and produced more than 8 trillion dollars worth of economic benefits, long before AI entered the picture. Today, open source technology is quietly training, improving, deploying, and securing AI everywhere.For more than three decades, open source has been powering three trends, and upholding three values, which the American society holds dear – education, competition, and innovation.Open source is pro-education because its origin was rooted in academic institutions trying to make technology free and open, not held hostage to the profit-maximizing zeal or the menacing lawyers of large corporations.The precursor of open source is the free software movement, which started in 1983 on the campus of MIT. It was a time when every small act of using software, whether it was teaching students or doing research or improving a printer’s performance, meant paying or dealing with big corporations like AT&T or Xerox. After this struggle gave birth to open source, every student in every university, community college, and coding bootcamp in America now taps into the freedom that open source enables to learn how to program, engineer, and build. Open source is at the heart of technical education everywhere.Open source is pro-innovation because it essentially provides a set of tools plus a community of other users to help anyone turn an idea into reality, for free. Combined with its role in education, it has watered most of the seeds of innovation in recent memory. Some of these seeds stayed as hobbies that brought joy and personal learning to the hobbyists. Others blossomed into huge companies, like Meta, where the initial version of Facebook was built entirely on a stack of open source software.Every day, new ideas or solutions are being coded up in a dorm room, garage, or basement, all because open source lets innovators create without fear of a lawsuit or an expensive bill.Open source is pro-competition because it helps the underdogs challenge and compete with the large incumbents, keeping monopolistic threats at bay. Linux, the open source operating system that now runs more than 90% of the world’s cloud computing infrastructure, was the antidote to the Windows monopoly (so much so that former Microsoft CEO, Steve Ballmer, called Linux “cancer”). Android, the open source mobile system, fostered a long string of competitive smartphones before Apple’s iPhone could control the market. Many other examples exist in the more niche, but no less important, segments of self-driving, databases, and semiconductor design.Without the equalizing and democratizing nature of open source, we would all be living with the rent-seeking consequences of more monopolies and less free market competition.Does AI change any of this? No.The duopoly of Anthropic and OpenAI are rapidly concentrating power between them with their closed, proprietary models. Anthropic, in particular, has flexed its monopolistic muscle recently by reducing its most advanced model’s capability when it is being used to improve someone else’s model. While the capabilities of their models are undeniable, so are their price tags and market concentration. Open source AI, mostly in the form of open weight models, has been the only counterweight for startups, educational institutions, and enterprises looking for alternatives.Does open source lead to more safety or security concerns? Not quite.We acknowledge it is worth monitoring the security implications of open source models that may reach frontier capabilities. But for the most part, the transparency that is inherent to open source makes them safer and more secure, because more engineers and researchers can tune out unwanted model behaviors, like censorship, or fix bugs in the software that runs these models. As one popular saying goes, “given enough eyeballs, all bugs are shallow.” An open source model also does not transfer data, when installed on your own company’s infrastructure as Airbnb CEO, Brian Chesky, explained. Open source AI is the most secure and privacy friendly path.What about China? Beware of unintended consequences.China is certainly a fierce competitor with the US on many dimensions – economically, militarily, diplomatically – but using this dynamic as a pretext to regulate open source will backfire.Open source models are actually improving the efficiency and profitability of many American startups, who cannot afford to pay the monopoly-level premium to Anthropic or OpenAI. AI companies working in coding, legal, and other domains are using open source models, including ones from China, every day. The fact that these models are made by Chinese labs should be a wake-up call that open source is under-invested and under-appreciated in America! The response should be more support for open source at home. Regulating or limiting open source because of China would achieve the opposite: putting a chilling effect on education, innovation, and competition, while pushing the rest of the world – much of which wants open source’s benefits as much as we do – to adopt China’s.Former Supreme Court Justice Louis Brandeis, famously said, “sunlight is said to be the best of disinfectants,” when it comes to removing corporate or societal misconduct. Open source is that “sunlight” in technology and AI. America should always be on the side of light. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 6m 50s | ||||||
| 6/17/26 |  State of the blog, mid-2026 | As I navigate my career change after Ai2, I wanted to share my views of how this blog relates to my missions and broader work. In my farewell post, I summarized my three goals right now as:* Provide clarity in the evolution of frontier models. * Create a vibrant and diverse open (model) ecosystem.* To build institutions that make these goals possible.Within this, Interconnects is at its core a bit different than many of the highly-polished, professional newsletters on this platform – and this is becoming intentional.How Interconnects fits into my career goalsInterconnects is the tip of the spear of all of my missions in AI. It is meant to start a conversation and to let the reader into the mind of someone at the frontier. This insight makes the writing sometimes a bit raw, sometimes a bit too technical, but it is the map of how I progress my thinking in the ever changing world. This style of writing has helped me create very strong relationships with the core group of readers, many of who listen to the voiceovers I do for these posts. The plan is to keep operating and refining the Interconnects experience around those loyal fans. These are to a large part people building the frontier AI ecosystem — researchers at labs, top investors, policymakers obsessed with the frontier, and students aspiring to have one of those roles.I’m very happy with this sort of raw, high-voice outcome for the blog. It is not something I sought out, but rather accepted as I saw it coming and realized it would be disproportionately successful in a near-future of vast AI slop media. With years of trying to squeeze writing into a busy schedule, the only sort of writing I had time for was that which had a style very closely matching how I think.I’m also very happy to be an independent voice. As a person I don’t do well with some power structures like having a boss, and I think there are very few people without extreme financial conflicts of interest that are willing and allowed to write. Through a wide job search, few companies were genuinely excited about me continuing writing.Over the past few months, I considered taking Interconnects in more of a direction like SemiAnalysis or Stratechery, where it is my full-time gig and number one priority, but it didn’t seem like the right fit for what I am trying to achieve. I’m trying to build an open ecosystem and a movement for true open-science at the frontier of AI. These areas are very narrowly populated and trying to influence them with only commentary, analysis, and related research products wouldn’t work for me.These sorts of full-time outcomes are definitely still one of my dreams, and I will do it at some point. The dream of this is also one of the reasons I take conflicts of interest seriously. Though, in this era of AI I can’t be fully on the outside.In this vein, I wanted to disclose two advising agreements I recently signed. I don’t view them as a compromise of the above independence, as I’ll happily quit if I feel like I can’t speak my mind, but as a form of support in accomplishing my missions. If I want to make a true open-science ecosystem I have some catching up to do with how the frontier labs approach post-training. The two companies I’m advising, whose leadership I’ve become friends with, are Arcee AI and Mercor. Arcee should be fairly obvious as the no-nonsense player building open-weight models. Mercor will make more sense over time, but they’re a close ally to a lot of my goals in transparent evaluations, open post-training, and neutrality with respect to the leading labs. These advising agreements are based on me wanting to learn more, and I don’t suspect I will ever engage in the very cursory advising roles that are more of name-stamping.I keep an up-to-date disclosures statement at the end of the Interconnects about page: https://www.interconnects.ai/about.Otherwise, my full-time job should still be in the non-profit sector as long as I get the next few months of logistics right.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.Some operations & audience notesInterconnects has cultivated an excellent, niche, and largely technical audience with representatives of all the top companies and labs (recently crossed 70K subscribers). I intend to protect this niche audience rather than trying to expand to bigger pastures. I think this success in audience alignment is reflected in my ~900 paid subscribers supporting it with infrequent paywalled content. I appreciate the support greatly, as the money has let me expand Interconnects operations and quality over the last 18 months.I created Interconnects AI, LLC last January along with business bank accounts. Since then I’ve made some money, but I’ve reinvested it (and more) back into the business and the various AI services I need to try to write these articles. So, at this moment going full-time on Interconnects is a pretty risky financial proposition for me. In fact the Interconnects bank account has hovered around $0 for months (I’m personally fine having another job). This made me hesitate in going all-in on it, but in reflections I concluded that I would have more impact in AI by building these systems than focusing on commentary. Second, as AI services get more expensive (e.g. Fable becoming API only), I’m going to need to spend more out of pocket to make this happen. I’m happy to do this in the near term, but I’m starting to optimize the blog to have more consistent financial growth, so when I want to go all in on writing in a few years I have a safety net.I don’t do special offers, free trials, etc. for Interconnects paid subscribers (mostly to mitigate noise in the Discord community), but if you have the means to support this project it would mean a lot to me as I center my career around it. Joining a lab or a well-paying startup would be a much simpler path for me and my family but it’s never felt like the right thing to do. I have a very arbitrary goal of reaching the 1000 paid subscribers orange checkmark on Substack this summer. So you can help and/or just watch my attempts to make it happen.In this vein, I wanted to be direct in sharing how I view a few core operational components of Interconnects, and what you can expect going forward.* All comments will be paywalled. Whenever I have a popular post without paywalled comments I get a flood of low-quality posts — many of which are obviously AI generated. This is a detriment of the highly selective audience we’ve built. If Substack supports a feature like “only users with a paid subscription somewhere on the platform can engage,” I’d implement it. The blog comments, Substack chat, and Discord will be spaces where I perform active curation to maintain a 0% AI slop rate.* Slightly more articles will be paywalled. I want to keep experimenting with what is the right way to do this, but the only metric I can rely on for increasing influence of the blog is revenue. Views, likes, etc. are all vanity metrics which don’t reliably measure this type of content. Cultivating a highly engaged audience is existential to me in attempting to maintain an AGI-proof expertise.* Slightly more in-person events. With a small community that I respect, I have to opportunity to translate that to excellent real-world experiences. I expect to keep these small, but I want to be more proactive at organizing them so loyal readers know what to expect. The few coming soonest will be for my book launch, which should be in the next month or two. Plus, I know people always want to meet likeminded folks in AI!Together these should make it easier and more enjoyable to be a loyal fan for Interconnects. I’m looking forward to continuing convincing my fans that the support is worthwhile.Thanks for reading! My career wouldn’t be possible without all of the support. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 6m 19s | ||||||
| 6/16/26 |  Frontier post-training recipe review with Finbarr Timbers | As I’ve been recapping fundamentals of post-training to wrap up my RLHF / Post-training book I knew I needed to get Finbarr Timbers back on the podcast to talk about the state of play. Over the last few months we’ve had many discussions on what we’d need to do to take an Olmo-style recipe to the frontier, supported by Finbarr’s extensive reading of recent model technical reports.To prepare for this, I put together a summary slide deck on the key post-training recipes historically — the path from InstructGPT to today — and today — the key open frontier models. This deck is summarized below as the technical summary, but we do spend 20-35 minutes on it in the podcast, so watching on YouTube is likely the best experience for this one.I previously interviewed Finbarr in December of 2024, shortly after the release of o1 and Tülu 3 (and before he joined Ai2) on the “We are so back” era of RL.Chapters:* 00:00 Introduction & Olmo reflections* 06:28 Post-train recipes review (history)* 23:00 2026’s model recipes (MiMo Flash, DeepSeek V4, GLM 5, Kimi K2.6, etc.)* 39:05 Open-ended post-training discussions* 48:22 Career advice in the LLM raceListen on Apple Podcasts, Spotify, and where ever you get your podcasts. For other Interconnects interviews, go here.For more educational post-training videos, see the course I’m putting together.Technical SummaryThese are notes cleaned up from a slide-deck created with AI assistance — mostly useful as a discussion topic and reference.The shape of a post-training recipe has changed more in the last year than in the prior three.* 2022–2023 (InstructGPT): one pipeline — SFT → reward model → RL.* 2024 (Llama 3, Tülu 3, etc.): open recipes formalize SFT → DPO → RL with verifiable rewards. Closed recipes use many stages of RLHF.* 2025 (DeepSeek R1): reasoning RL (R1) makes large-scale RL the centerpiece.* 2026 (MiMo Flash V2): recipes fragment into many specialist models that are merged back into one.The new thing: MOPDMulti-teacher On-Policy Distillation (MOPD) is the pattern showing up across the 2026 frontier.* Train N domain-specialist teachers (each: SFT, then RL on the relevant domains).* Train one general student by sampling its own trajectories (this is the final post-trained model).* On each rollout, minimize reverse-KL to the relevant teacher’s output distribution, token by token.Lineage: MiMo Flash v2 introduced it → DeepSeek V4 & Nemotron 3 Ultra scale it to >10 teachers.Why did MOPD emerge?* RL got expensive and conflict-prone. Mixing math, code, and agentic RL in one run eventually trades capabilities off against each other.* Specialists are cheap to make / organizationally scalable. SFT-then-RL on a single domain is well understood and parallelizable. As post-training becomes more complex, scaling it across organizations is a big win.* On-policy distillation matured. Literature and know-how continued to emerge through the RLVR renaissance.Sources: DeepSeek V4 §5.1, MiMo-V2-FlashKey historical recipesInstructGPT (Mar. 2022) — the canonical 3 steps · paper* SFT on human demonstrations* Reward model trained on human comparisons* PPO against the reward modelLlama 2 (Jul. 2023) — multi-stage RLHF · paper · interconnects recap* SFT, then iterative RLHF over multiple rounds* Each round: rejection sampling → PPO* Two reward models — separate helpfulness and safetyLlama 3 (Jul. 2024) — a complex multi-stage recipe with simpler optimizers · paper · interconnects recap* Per round: reward model → sample K per prompt → rejection sampling → SFT → DPO* No online RL — the RM only filters; run over 6 rounds, best models seed the nextTülu 3 (Nov. 2024) — simple three-stage post-training · paper · interconnects recapCurated prompts → SFT → DPO → RLVR (RL with verifiable rewards — the acronym was coined in this paper).OLMo 3 (Dec. 2025) — a reasoning update to the Tülu 3 recipe · paper · interconnects recapDeepSeek R1 (Jan. 2025) — RL as the centerpiece · paper · interconnects recapThe recipe:* R1-Zero — pure RL (GRPO) on the base, no SFT; used to seed reasoning behaviors for the full run, not a separate product* R1 — cold-start SFT → reasoning RL → rejection-sampling SFT → final RL → distill to dense* A big change in recipes: Large-scale RLVR as the primary driver, SFT to distill and refine RL behaviorsDeepSeek evolution after V3* V3 · Dec ‘24 — SFT + GRPO RL.* R1 · Jan ‘25 — multi-stage RL; reasoning emerges.* V3.1 · Aug ‘25 — hybrid think / non-think in one model.* V3.2 · Dec ‘25 — 6 specialists via RL → SFT distillation → one mixed GRPO.* V4 · Apr ‘26 — 10+ domain experts → MOPD.2026 style recipes!MiMo Flash v2 (Jan. 2026) — where MOPD started · paperStages: Stage 1 SFT → Stage 2 train ~6 domain-specialist teachers (with older style post-training recipes) → Stage 3 MOPD into a single student.First clean articulation of multi-teacher on-policy distillation as the consolidation step — replaces a single monolithic RL stage with distill-from-specialists.Nemotron 3 Ultra (Jun. 2026) — two rounds, many teachers · paperStages: SFT → multi-teacher on-policy distillation, run over two iterations, with >10 teachers spanning reasoning, code, math, and agentic domains.Novel: multi-round MOPD across different domains — distill, then re-distill from refreshed teachers.MAI-Thinking-1 (Jun. 2026) — closer to R1 than V4 · announcementStages: mid-trained base → 3 specialist RL “climbs” (e.g. STEM) → trace-distillation SFT to consolidate the climbs → a final RL climb → MAI-Thinking-1.Closer to DeepSeek R1 than to V4 — multi-stage RL with trace-distillation SFT to consolidate, not on-policy MOPD. Not the only lab without MOPD!Kimi K2.5 (Jan. 2026) — agentic, multimodal · paper · blogStages: text-only SFT → joint text–vision RL across coding, vision, reasoning, agentic tasks. (No mention of MOPD.)GLM-5 (Feb. 2026) — staged RL by capability · paperStages: Base → SFT → Reasoning RL → Agentic RL → General RL.Transcript00:00:00 Nathan Lambert: Hello, we are back on a Interconnects conversation. I don’t really say I do interviews. People criticize me ‘cause I interrupt the guests too much. ‘Cause I’m not a good interviewer, but I’m here to entertain people. Um, this is also fun for me because I’m trying to make, like, a post-training course, and it kind of fits as, uh, in the advanced end of this.So it’s kind of a crossover between Interconnects content and other stuff that I’ve been spending my time on this summer. So I’m happy to welcome Finbarr back. I think... Are you the first return guest? I haven’t checked.00:00:37 Finbarr Timbers: Oh, wow.00:00:37 Nathan Lambert: Um, Finbarr and I worked on this sort of post-training recipe stuff for a while at AI2. Um, I left recently. This is one of Finbarr’s last days at AI2. It’s already been announced. It’s not a spoiler here. So we’re gonna kind of reflect on some things on building post-training recipes for OLMO. Um, then we have a little, like, review slide deck and notes on the kind of state and evolution of frontier post-training recipes over time, which is pretty interesting because there’s, what is it, like two to four kind of canonical recipes that there has been.So it’s kind of interesting when you see the field converge on something new, which it’s doing right now with multi-teacher on policy distillation. For some reason, that’s a bit of a mouthful. It is a long acronym. And then we’ll just kind of end with various discussion points on post-training and what we’re up to. So, happy to give you the floor if you have any hot takes you wanna start with to get people to, draw people in. Otherwise, I think, uh, I’m excited to kind of reflect on this, ‘cause I know you’ve been reading a ton of papers recently and kind of prep, laying some of this groundwork.00:01:43 Finbarr Timbers: Well, yeah. I mean, today is my last day at AI2, so it- it’s ki- it feels very appropriate to be, to be talking to you as you’re the one who recruited me to AI2. So, uh, yeah, that’s pretty special, and it’s great to be, uh, yeah, the, the first repeat guest. I feel honored, uh, to be back on. So yeah, thanks, uh, for having me.00:02:03 Nathan Lambert: Yeah. Do we wanna start with OLMO? I think that-00:02:05 Finbarr Timbers: Sure00:02:06 Nathan Lambert: ... people... I think I, uh, need to do this carefully, but I’ve talked about OLMO-3’s post-training many times to people. I haven’t done this in a very direct way on the podcast, but I would say that post-training OLMO-3 to make this reasoning model was a major accomplishment for many individuals to do this. But also, the complexity of what we were doing was pushing against the limits of AI2’s organizational capacity, and a lot of modern post-training is, like, your ability to wrangle compute data into a work stream.And in order to do that in a complicated way, you really are wrangling an org chart. And that’s like part of why it’s like OLMO-3 was, by its nature, pretty late as a reasoning model. It was, like, a pretty rigid reasoning model, and that’s, like, partially reflected in the recipe being pretty simple. But then when you, like, compare it to all these new recipes with tool use and multi-teacher distillation and all of this, it’s just like a, a, a fork in the road where it’s like you could do this very simple thing and make a strong recipe, but it is not representative of what all the frontier labs are doing.And I think that that kind of fork in being able to say that things are similar happened kind of after Tulou-3, where Tulou-3, I think, was also much simpler with this three-stage SFT-DPO RL recipe. But that simpler recipe was probably closer in outcome to what the labs are doing, but now doing that sort of three-stage recipe for a reasoning model, and especially a tool use, like, agent model, just doesn’t really apply. And that’s the point. That’s why I think the point of this podcast is to be like, what are the, what are the way, what are they doing to make these, like, true frontier models, and then shed some light on how it contrasts to the more a- like, open academic ones.00:03:56 Finbarr Timbers: Well, actually, I think that’s interesting. What was the proce- so, you know, I, I only, um, came around for OLMO-3. I wasn’t around for the earlier, um, versions. What was the process like to go from Tulou-3 to OLMO-2? Because, like, y- just looking on, on Archive, um, I think Tulou-3 came out in November of ‘24, and then OLMO-2 came out in December of, of ‘24.00:04:22 Nathan Lambert: We just applied the recipe.00:04:24 Finbarr Timbers: Yeah. I, I mean, so, so I think that actually, like, yeah, and then, you know, um, DeepSeeker-1 came out in January, end of January ‘25, and, you know, OLMO-3 was then released in October. Was it October or November of ‘25? Like, I think-00:04:39 Nathan Lambert: I think November.00:04:41 Finbarr Timbers: Yeah, November. Yeah, right. It was November. So it’s-00:04:43 Nathan Lambert: It was like do or die with Thanksgiving.00:04:45 Finbarr Timbers: I remember that. Uh, yeah, ‘cause Canadian Thanksgiving had, had already happened-00:04:50 Nathan Lambert: Yeah00:04:50 Finbarr Timbers: ... which, yeah, I was happy. Um, but, uh, like, like I think it was, sure, maybe it was late, but I think it was only late by a few months. Like, it’s, it’s actually, like, you know, if I think of my past experience with model turnaround times, like a nine-month model turnaround, you know, from R1 coming out, like that’s actually, that’s not bad. I think, you know, something like six months would’ve been nicer, but-00:05:12 Nathan Lambert: I, I think it’s slow ‘cause we didn’t re- it would be fast if we had rebuilt the R1 recipe. But what we did was we, like, ported reasoning into our existing recipe-00:05:21 Finbarr Timbers: Yeah. Okay00:05:22 Nathan Lambert: ... which is a simpler task, but has, like, a lower ceiling, in my opinion. Where it’s like the DeepSeek and the newer style recipes, which we’ll talk about, I think they just have a much higher ceiling in how much you can keep hill climbing them. Or they’re just, like, more prescri- more pedagogical of what the frontier is doing. Like, for the size models that OLMO was, which was like 7 to 30B, I’m not sure that doing this DeepSeek style RL first recipe is actually useful.00:05:52 Finbarr Timbers: Uh, well, I, yeah, I think that’s a good point. And I mean, I think that’s really reflected in what we see in the research where you s- you know, you obviously you see the big, uh, the step change and you know how quickly things are improving When, you know, R1 comes out. So, like, I think that a great point, and it really does seem to saturate, or to, to not saturate, sorry, with, with compute. Um-00:06:11 Nathan Lambert: Yeah. Um, shall we just do the slide deck? We’re throwing around, like, recipe-00:06:15 Finbarr Timbers: Sure. Yeah, let’s do it00:06:16 Nathan Lambert: ... names. Like, I feel like it might be useful to just do it because a lot of people probably want to follow but don’t exactly know. I’m, I’m gonna share, I’m gonna share a screen. So people listening, it might be useful to either, you can pull this slide deck up on your phone and click through it. It’s not super information dense, but you can also just watch it on YouTube. All of this will be linked.Generally, this is just like a quick survey on how frontier recipes have evolved. We’ll go through the history quickly and then talk about what is currently happening and kind of probably interleave the old mode discussion we were having. Uh, okay. There’s a bunch of canonical recipes we’ll talk about. This is where I got the two to four number. I think the recipes are like InstructGPT, which is what coined the initial RLHF with this like three-stage idea, which took a while to get people to move on from, which was like SFT reward model and RL.And I see as like Llama 3 and 2.3 as kind of practical implementations of that with, with other tricks of the trade. So those two could potentially be merged together. It’s just like kind of pre- and post-ChatGPT moment. And then the two most recent canonical recipes that we’ll cover in this I would say are like DeepSeek-R1, which is the shift to doing like reasoning focused and bigger RL stages than this kind of SFT focus from before, and then NeMo Flash and some of the new models from 2026 which add this distillation element.00:07:42 Finbarr Timbers: Well, and, and I think it’s worth pointing out too that it’s not just NeMo Flash, like it was kind of a consistent theme. Like you saw this with DeepSeek, th-they referenced it in, uh, the V3 paper and then it’s, you know, it’s Qemi K 2.5, it’s GLM 5. Like it’s all of these papers, you know, start talking about this specialist, um, RL stage.00:08:03 Nathan Lambert: Yeah. I think there’s a debate on how we draw it and whether or not distillation is... If you’re, if you have distillation as a technique, as a key milestone, then they were, the Xiaomi was the first and, but it’s kind of a march over time where you kind of see them change, and we’ll, we’ll go through this. I don’t, I don’t need to interrupt.00:08:23 Finbarr Timbers: When you say distillation, I do think it’s important to distinguish between the straight up like, you know, distillation of the leading closed models and, you know, distillation of these domain specific models where, you know, I, I, I suspect that the, you know, the, the Chinese labs are doing both.00:08:41 Nathan Lambert: Yeah.00:08:41 Finbarr Timbers: But, you know, a lot of what they’re do, you know, but a, a lot of what they’re doing is this, um, training these domain specific models like, you know, a math model, a coding model, uh, you know, logic model, whatever, and then distilling those models back in and not just distilling from... So when we’re talking about distillation, it’s not just distilling from the leading closed models.00:09:01 Nathan Lambert: Yeah. It’s a pain. I agree. The distillation term is horribly overloaded. Um, there’s a review slide. Do we need to review multi-teacher on policy distillation? It might be too complicated to need to do it. We could come back to it. I think I kind of want to just go through the actual models, and then we could use the supporting slides as needed. Um, this famous InstructGPT three-step thing, I think many people have heard of it, but this is what constituted post-training at the time of ChatGPT coming out, so it’s kind of important grounding of this human supervised SFT data, mostly human supervised preference rankings to make a reward model and then do RL on that, and the model gets better.And it’s pretty interesting how all of these have been kind of phased out, at least in terms of what we know openly, where they’re, we don’t use that much human demonstration data for SFT. There’s likely some human preference data still in the loop, but I would guess that synthetic has a much bigger role, and there are reward models, but they’re like not the cl- key RL target anymore. So in four years, most, almost all the canonical pieces have been moved on. And like this evolution is kind of within there. I think the early models after InstructGPT, like Llama 2, um, even Llama 3, these are pretty similar, which is like you’re starting to break down this recipe with different tools like projection sampling, DPO, some increased iterations. I think increased iterations is just that there was more incentive to squeeze more out of the models, and they just like broke things down more, where InstructGPT seemed like a bit more open-ended research where this kind of cleanness was fine. So-00:10:48 Finbarr Timbers: Well, I think that’s interesting, uh, with respect to how much everything has scaled, uh, right? Because, you know, InstructGPT was before ChatGPT was, was released, and so, you know, it’s something, like just the complexity of what was done is that which a small team or even a single team could do. But then when you start looking at, you know, Llama 3, like it just starts to be a more complicated process and, you know, where you start to have a lot more, you know, specialized data and there’s, you know, a lot more, you know, room for scale and for kind of money and complexity be poured in.00:11:25 Nathan Lambert: Yeah. It’s like, uh, both for-profit and nonprofit efforts to do post-training want me to advise them, and I’m like, “I don’t really know how I’m gonna give you advice unless I’m spending twenty hours a week look, understanding the details of your recipe,” ‘cause it’s like, well, I can’t really give you a one sentence thing of do X without understanding all the complexities of the model and the post-training process that go into it. Which makes it, like makes it hard from kind of like a transparency point of view. Even if it’s fully detailed, it’s definitely still hard to modify and study.00:12:00 Finbarr Timbers: Absolutely.00:12:02 Nathan Lambert: So then like two through three in AI2, a lot of this was we’re trying to beat the results of this Llama 3 post-training, which is pretty complicated, but we don’t have the ability to scale the organization as far. So I, I, I think that’s a big reason why the actual workflow is a lot simpler, where we have three clear stages that are doing slightly different things, and they build on each other. And that’s like... It’s never stated very explicitly in these papers on like how the org chart impacts the recipe, but I would, I, I think it’s a very strong signal within the, at least the delta between the fully open work and the kind of partially open work that you get from industry.00:12:43 Finbarr Timbers: Yeah, absolutely. And, and I think especially as we’ll see with the domain-specific models, like that’s like really clear, like something where you could really easily scale up your org chart to-00:12:54 Nathan Lambert: Yeah00:12:54 Finbarr Timbers: ... build that up.00:12:56 Nathan Lambert: Yeah. And I threw Olmo 3 in after this, after the two through three slide, mostly just to show that the recipe was so similar to two through three, and the org chart hadn’t really changed. Like we didn’t have more ability to scale, and like there was a, a little bit of separation between the model types, between like the think and the instruct models. But like without a major reinvent- like a major org change, it was just kind of stuck in this and do the best you can with it.00:13:22 Finbarr Timbers: Yeah. Absolutely.00:13:23 Nathan Lambert: Be- because like the real big change was this with DeepSeeker-one. They, I had never seen this plot before, but they had this plot, maybe they added it for the nature version of the paper, where they kind of show their recipe, where they like take the base model, they do RL zero, and then they sample from the RL zero to like filter prompts, and then they use that as SFT. This is like going through this. They use that as SFT for the next version of the model to create like a development internal RL DeepSeek-R1, and then they do this like repeated sampling to train multiple RL versions and kind of distill, distill in the sense of, of clarify and refine the reasoning behavior of the model before going through the final pipeline, which again is a mix of, um, reasoning and non-reasoning SFT into a bigger RL run. And-00:14:11 Finbarr Timbers: Well, and I think this is really interesting because it starts to show, I mean, first of all, the, the complexity here. We’re starting to use, um, yeah, like synthetic data as this primary input here, but it’s not just like, you know, it’s trying to elicit, you know, specific behaviors, and it’s this kind of like industrial process, um, instead of like this, you know, it’s not as much of an elegant research recipe. It’s more like, you know, we train a model, and then we use it as best we can, and we keep iterating. Um, but I think the other thing that’s interesting is, is we’re starting to see here the SFT serving as the cold start. First of all, where, where that’s, you know, I think before SFT was more of like a generally useful stage, whereas here its, its primary purpose is this, this cold start for RL.And then the other interesting bit is, you know, DPO, uh, starts to disappear at this point from the leading recipes. I mean, Olmo 3 still does it, but you know, basically everyone else does away with it and just, you know, has the preferences included, um, as in, as a reward model or, you know, at so- at some way, um, in the reward bit of the RL stage. And so that’s a really interesting change, where the, the supervised part of post-training is just, you know, massively deprioritized.00:15:27 Nathan Lambert: Yeah. So my hypothesis for the dropping of DPO on these models is that, uh, as, as you’re doing like a cleaner recipe, essentially the need falls away. Versus if you look at Olmo, which is taking tons of potential gains by refining your model on outputs of strong open weight models, like largely Qwen and DeepSeek is the training data for the SFT of Olmo 3. Uh, and like the delta between that SFT data and the base model is still pretty big in the probability distributions. So DPO kind of helps further refine and clean up that distribution in a way that kind of has very rough edges. And but when you have a more refined, like industrial process on post-training, th-that will, that potential benefit will be harder to gain. Something interesting that I didn’t fully con-confirm before this is, for example, NVIDIA used to also be on this DPO train with their smaller Nemotron models.And, and I would guess that potentially like D- Nemotron Ultra would not. But it’s, and, and that’s because they’re at much further down this development tree and using on pol- like these more on policy methods for creating the SFT data. And their model, I would guess, will become kind of more robust out of distribution and like have weird, less weird rough edges before because of it. So that’s kind of my hypothesis on DPO, and people that use DPO will be looked down upon. But it’s like if you’re trying to bootstrap a recipe off the ground and just take gains where you can, I still think it’ll work for a lot of people in a kind of compute efficiency standpoint.00:17:05 Finbarr Timbers: Yeah. I mean, I think generally, uh, there’s something interesting with the, the preference tuning that, yeah, like maybe, um, it isn’t being given the proper, um, respect that it deserves. ‘Cause o-one of the interesting bits about the Nemotron 3 super paper was that they saw pr- they, they do a, a traditional RLHF stage in their RL, which has also, you know, fallen with fashion and development, and they see pretty massive gains with it. So I think some of these changes are more, you know, driven by what’s in fashion rather than perhaps like a fully rigorous, you know, set of ablations.00:17:41 Nathan Lambert: It’s very remarkable to me that the preferences loss function can do so much for these models. Like the models have so much potential there, and it’s just, it’s really a contrastive loss on pretty granular feedback. And they learn all sorts of things. Like they’ll, they’ll get better at math and code, or their reasoning strategies will be refined. And so I, I... That’s remarkable to me. I think there will still be funny research on like using preference- Base losses with verifiable outputs. Like, I, I think all this would work. Like DPO on verifiable rewards and stuff like this, it’s just kind of intellectually less appealing.00:18:19 Finbarr Timbers: Yeah. Well, I think that’s, uh, you know, that’s where I thought that the, uh, delta learning, um, hypothesis style, uh, DPO, like what Olmo-3 did, where you, um, where the, the preference, you create these synthetic preferences by having like strong, by like bigger and smaller models of the same family, like is where you get your preferences from. I thought that was a really interesting signal because it, it seems really analogous to some of the work, some of the guidance stuff that we see in diffusion models, like how you have the classifier-free guidance, which has something similar, and there, there were very similar results there, which showed that you could have the--But like one signal they used was further along in training versus earlier in training models as like, uh, a source of, of signal that you could guide along. And, and that worked quite well. And so I suspect that these signals, um, for, for preferences in that way, like that they could actually be more robust, but because, you know, some of the largest labs don’t have to do that, perhaps we’re not citing them as much.00:19:18 Nathan Lambert: Yeah. Or they don’t tell us. Like, to continue this, it’s kind of cool to look at-- So the DeepSeek models have kind of gone through this, what I would call like l- closer to Llama recipes to DeepSeek-R1, which is d- like most definitively the canonical recipe for reasoning models, and then continue to change closer to this multi-teacher format. So if you look at the VC-3.3 paper, um, before R1, they do something remarkably similar to two to three type thing, where they have a mix of SFT and then they use it ver-- like this RL on verifiable rewards. They didn’t call it that, or their paper wasn’t out at the time. And so they did this before R1 came out, which was just kind of a less reasoning-focused models and used the same tools but with a different ratio of implementation weight.00:20:07 Finbarr Timbers: And, and what’s interesting is that this comes out basically at the same time as two to three, and it’s a very similar two to three and Olmo-2. It’s a very similar recipe, just done with more complete.00:20:16 Nathan Lambert: Yeah. Yeah. And then we have this R1, which we’ve just talked about at length in January, which is a month later. They have a few more releases through this. They have some updates to their V3 and R1 models, which have dates, which are largely the same recipe. And then the next documented change in their recipe was V3.1, which is when they merged this thinking and non-thinking into one model, which everybody that does this says, has said that it has been hell to train in. But you kind of need it from a serving perspective, and it’s obvious that long term, at least obvi- it’s obvious to me that long term all the models will be reasoning models, and you’ll just have reasoning models that are very efficient based on the gains that are there.So this is kind of a needed change that they made. And then in December of 2025, they released V3.2, which is when there’s kind of meaningful changes to their recipe, and they’re talking about this expert creation with separate mini recipes, and then using that within their kind of R1 data process to do SFT data and then like a big RL run at the end with GRPO. So it took about a year for this, uh, like kind of evolution of the R1 style recipe to land in their models. And I think this, this is like a very big complexity step that isn’t represented in something like Olmo-3, and it’s kind of where you can see a fork in the recipes over time as like they, it, they become way more industrial and scaled at these frontier labs.00:21:46 Finbarr Timbers: Yeah. And I think, you know, another one good thing here, just from a historical note, is that I think it was with the O3-24 release where they updated the original V3 paper. So, you know, V3 comes out before R1, then R1 comes out, and then after R1 comes out, they actually go back and update the V3 paper, maybe getting ready for the nature submission or, or, or something.00:22:07 Nathan Lambert: Yeah.00:22:07 Finbarr Timbers: Um, and they make a reference there to say like, “Oh, you know, something you could do is you could train these domain specialist models and then combine them.” Uh, and then, you know, that later becomes kind of what, you know, the more of a priority as they talk about in V3.2.00:22:21 Nathan Lambert: That’s a fun note. Yeah. And then most recently in April 26th is this V4 model, which has even more experts. They add this new loss function for multi-teacher on policy distillation, which I said follow Jiaoli. And this is kind of a microcosm of the arc that the whole industry went through, at least the people who share what their post-training details are, of realizing how core RL is, changing the recipe around scaled RL, and then figuring out how to kind of scale to more domains in the scaled RL format without just like grinding to a halt in operational complexity.00:22:58 Finbarr Timbers: Yeah.00:23:00 Nathan Lambert: So then kind of the next stage of this is these, what I call twenty twenty-six style recipes, which are all these models that are doing this multi-teacher, um, infusion of knowledge. And then some of them are using on-policy distillation and some are not. It’ll be one of the key things to see is like how crucial is this on-policy distillation to really keeping up at the frontier. So the paper that kind of, that named this term was the MimoFlash V2 paper. I think the model was released in December and the paper in January, which a lot of things will look similar to this, um, kind of RL, large RL style recipe. But with this large RL run is more, is where the on-policy distillation comes in. So for, I c- this is probably a better time to explain. I have this great, great little feature.So this is like the summary of what multi-teacher on policy distillation is. Generally, it fits within an RL framework where you have the model you are training, the, like the general model, sample its own trajectories, and then you route the trajectories to various expert models you have trained. And each kind of sample is trained with this distillation KL loss to match the tokens of that expert. And People have, multiple models have shown that this type of supervision is really useful for the models. You could combine it with other RL losses, such as verifiable rewards, which for example, Sasha Rush gave a good mini spiel on that and how they use that with Composer, which is a, a video that I really recommend people watching as well. But the, the key of it is that it is a different loss function, but it plays very nicely in the RL frameworks that people are already using. So they use these teachers-00:24:45 Finbarr Timbers: Just RL, like it’s, it’s, like if you-00:24:47 Nathan Lambert: Yeah00:24:47 Finbarr Timbers: ... actually implement it, you know, I’m talking with some of the people at AI2 about implementing it now. And it’s like you take your RL setup, and then you just, you know, you, you have some very, your, uh, set of tweaks on the, the learner to actually implement this. So it’s quite straightforward.00:25:02 Nathan Lambert: Yeah, so this is a fancy diagram that makes it more complicated than it needs to be, but it also a very nice diagram, which shows the various, um, domain teachers that they have, search agent, code agent, math, reasoning, safety, and how they put these together. And the, the experts are used both for SFT data and then this final supervision. And the recipe for the experts would look something like this DeepSeek recipe, which is complicated on its own, which is like make a very good reasoning model that is good at one thing.00:25:29 Finbarr Timbers: Well, and I think it is complicated, but it’s also like if you, if you think about being the actual researcher like working on it, it’s like, you know, you have a base model, and then you have an RL set up, and you know, you’re just constantly updating both and then rerunning RL. So, you know, the, the most complicated like, uh, part of it is just, you know, writing down the history and tracing everything. But it’s kind of like a very natural, organic way, uh, for the r- the RL to evolve through, you know, iterative experimentation.00:25:57 Nathan Lambert: Yeah. So like once you have a recipe, you’re progressively tinkering with each part, and it’s, it’s fairly stable, but it’s hard to rebuild from scratch. So like we’ll see how, see how long the recipe shape lasts, but it’ll probably be order of years. Um, another big one in this like also shared a lot of details on this on policy distillation approach was Nemotron-3 Ultra, which is obviously exciting to me to have a, like a US-made model that is very strong performance, and NVIDIA released a lot of datasets with it.But they, they also talked about a lot of their very n- n- like implementation details of what was hard with on policy distillation. I, like I have notes somewhere on this. They do this thing where they have two rounds of on policy distillation, as they found it to be better to integrate some teachers one after another. And the paper has a lot more details. I’ve, I, I don’t wanna go scroll through the paper, but we could also do this. Did you have any o- other impressions? Like I have the, we have this other doc we can pull up that-00:27:01 Finbarr Timbers: Oh00:27:01 Nathan Lambert: ... also you might have had other details on it.00:27:03 Finbarr Timbers: Yeah. Well, I think something else, um, that, that is worth, um, you know, contrasting the, the paper to is the Nemotron-3 super paper. ‘Cause in the Nemotron-3 super paper, they had a similar complicated recipe, but they did multiple rounds of RL. Like there they had three rounds of RLVR, followed by a round of, um, software engineering RL, and then followed by an RLHF stage. So it was, it, it was really interesting to see them go from doing that, like, you know, one of the most complicated, um, RL setups or in terms of, you know, successive stages, uh, that I’ve seen. To then, you know, you know this setup where it’s still complicated, but it’s a lot, um, you know, it’s a lot con- conceptually a lot simpler.00:27:54 Nathan Lambert: Yeah. I, I pocket the paper up. It’s gonna be hard for me to... I, like I had highlighted a few details. The, the interesting parts are kind of around the, um, various NVIDIA details on all the teachers. There’s just so many details in their paper on training-00:28:10 Finbarr Timbers: Yeah00:28:10 Nathan Lambert: ... all the teachers. I think, okay, so I have some of it. I have some of this up. It’s like I have an interesting quote that’s like, “One key finding from our trials of doing on policy, multi-teacher on policy distillation is that teacher models trained with substantially different training pipelines cannot be effectively combined through a straightforward on policy distillation merge, resulting in suboptimal performance.” So it’s like they’d have to do some cross teacher alignment, um, to make sure that they’re actually similar, which I feel like could become a whole, uh, organizational nightmare. It’s like they say, “We hypothesize that when the teacher and student are trained on different SFT data, they acquire different reasoning behaviors and induce different output distributions. This distribution mismatch can cause student-generated trajectories to be out of distribution for the teacher, result- reducing the quality and reliability of the supervision- supervision signals provided by the teacher.”00:29:00 Finbarr Timbers: Yeah, that’s interesting actually because there was a paper, uh, I, I can’t remember the name of it, but there was a paper that I read, um, recently which claimed that what you need to do is constantly... So, so you know, you know, one thing you could do, which was kind of the, the obvious thing to do, is you, you take your base model, right? You do, um, whatever general SFT that you’re doing, and then you take, you do, you know, a bunch of RL, you train domain-specific agents, you train them, you know, all the way until they’ve converged or until you’ve run out of money.Uh, and then you take these final experts, and then you do some sort of, you know, on policy distillation to combine them into your, your final model. Um, but with the paper, and I’ll, I’ll try to find it and then give it to you, um, see if we can share it. What they claimed was that you need to, um, instead of using the converged model, you need to do it in like successive stages with like the in-progress model. So if, you know, you train your RL for like a thousand steps, you need to, you can’t use the, you know, the thousand step checkpoint to, for the on policy distillation. You have to do it in stages, and first use the, you know, two hundred and fifty step checkpoint and the five hundred checkpoint and, you know, gradually bring that base model like up to speed or else there’s gonna be too much divergence, and the, the KL divergence will just be like too, um, too distinct-00:30:17 Nathan Lambert: Yeah00:30:18 Finbarr Timbers: ... to learn from.00:30:19 Nathan Lambert: Yeah. So essentially the last state-- sentence in this paragraph I had read most of is literally like, “We encountered this issue in practice because the teacher and student models were developed in parallel.”00:30:29 Finbarr Timbers: Yeah.00:30:29 Nathan Lambert: It’s like they’re like, “This is a problem because of it’s, like, hard to do everything at once.” Which is w- this is the type of thing where having research in it would be so great, and I think NVIDIA could release some of the teachers so that people could just like-00:30:45 Finbarr Timbers: Yeah. That’d be great00:30:45 Nathan Lambert: ... if you have the teachers and you have the intermediate model stage, you could do the problem of, like, just studying multi-teacher on policy distillation from the starting point and understanding the training dynamics.00:30:57 Finbarr Timbers: Yeah.00:30:57 Nathan Lambert: Which is the type of thing we would want to do at Oldo. We just haven’t scaled our recipe to this point yet.00:31:03 Finbarr Timbers: Yeah, absolutely.00:31:04 Nathan Lambert: So I will keep encouraging NVIDIA to do this.00:31:07 Finbarr Timbers: That’d be great. NVIDIA-00:31:08 Nathan Lambert: I think, uh-00:31:08 Finbarr Timbers: ... listen.00:31:10 Nathan Lambert: They, they listen. The other side of things is a bunch of models released in 2026 that do not do this multi-teacher on policy distillation, and they also don’t do nearly as many teachers. So I would say that this, like, Microsoft model, which I don’t say this as a diss, it’s, like, hard to get a new team off the ground, is they went for a simpler approach to try to get a solid model, and it has three more general experts combined w- via SFT and then, like, a longer RL run. So it looks a lot more like DeepSeeker one, but I suspect that what they will do next is make finer grain teachers and see if they need to switch to on policy distillation.00:31:48 Finbarr Timbers: Yeah. And I think, you know, in one of our, um, group chats, you described the MAI thinking model as a conservative recipe. A-and I think that’s a really good description of it. Like they, you know, the, the team came up with this conservative recipe, and then I think that they did a really great job of actually executing on it. ‘Cause I think, you know, if you try to make too many changes at once, it’s really easy for the recipe to collapse under its own complexity, and I’ve seen that a bunch of times, you know, across my career.Try to make too many changes and, you know, it all goes poorly. So I thought that was, um, a really good choice on their part. I, I also think that, uh, it’s not super clear to me, may-maybe you’ve seen some papers on this that I haven’t seen, but it’s not super clear to me how well the trace distillation SFT does or, you know, h- how much better on pols- online policy distillation is versus the trace distillation SFT.00:32:41 Nathan Lambert: Yeah. It’s like what’s, what is the relative magnitude in the final performance?00:32:45 Finbarr Timbers: Yeah.00:32:45 Nathan Lambert: So the Nemotron Ultra paper has a table on how far the on policy distillation goes relative to the teacher, and they also have the starting point. So I guess that’s a potential way to do this. Here, I could, I could just pull this up. Let me switch.00:33:00 Finbarr Timbers: Oh, sure.00:33:04 Nathan Lambert: So I, I had this open, but in a different tab. Okay. Here’s, here’s this paper. This is page twenty-seven is which the paragraph I just read, and then it also has this kind of-00:33:17 Finbarr Timbers: Oh, fascinating00:33:18 Nathan Lambert: ... is it a great table. I spent a while looking at this earlier. So essentially, it’s like where they get after SFT-00:33:24 Finbarr Timbers: Wow00:33:24 Nathan Lambert: ... on each of the benchmarks on the general model. And then I think... Okay, so the sort of gains over the RLVR student recovery of the specialty student. So I need to make sure... Okay, so it denotes the initial student checkpoint, where RLVR denotes the s- initial student checkpoint, and then the multi-teacher on policy distillation. So I’m not sure what this SFT column can figure out, but you could see the kind of like where the teacher is relative to on policy distillation. I think this is like the closest information we have on the relative performance gains.00:33:59 Finbarr Timbers: Yeah. That’s fascinating because the DeepSeek, I forget which one, maybe it was V3.2 paper claims or, or maybe it was, um, R1 actually claims that you can domain-specific... That, that, you know, doing the general stage, uh, captures the performance, uh, of it. But, you know, that, that doesn’t really seem to be... A-a-and yeah, a-a-and then so, you know, doing the domain-specific distilling in, and then doing a general stage on top of that captures the original performance. But that doesn’t seem to be the case here. Like, you know, the, the gap maybe isn’t huge, but there is still, most of the time, there’s a pretty big... There, there’s like, you know, a significant gap, even if it’s not huge. So that’s really interesting.00:34:42 Nathan Lambert: Yeah. I wish this table and text was clearer. It’s like I literally can’t fully parse it. It’s like RLVR denotes the initial student checkpoint, and then OPD denotes the checkpoint after first and second iterations. It’s like, what is the checkpoint that was used at the start of on policy distillation?00:35:01 Finbarr Timbers: I think it was the RLVR one, so that they do a general SFT stage, and then they do an RLVR stage that covers the non-teacher, the, the areas that where they don’t have specialized models. Then they do MOPD.00:35:15 Nathan Lambert: Yeah. And then that makes sense with this recovery rate, which is like final model minus RLVR, which would be like the gains for the OPD relative to the teacher minus RLVR, which would be like what gains you needed to still cover.00:35:31 Finbarr Timbers: Yeah.00:35:32 Nathan Lambert: And like what, what gains the teacher could potentially give you. So more research like this. Happy to see some of it a- out there. I’m gonna switch back.00:35:43 Finbarr Timbers: Yeah. Something I found interesting about the, um, the, uh, both the Nemotron papers and then the MAI thinking paper is that they don’t talk as much about some of the more detailed, um, post-training decisions that have shown some pretty strong gains in, um, some of the other papers. Like I, I believe it was GLM five where they talk about doing a difficulty curriculum and a difficulty filtering stage.00:36:11 Nathan Lambert: Yeah.00:36:12 Finbarr Timbers: And that’s just not something that’s really talked about in these other papers. They’re saying they, they don’t, you know, uh, I think it was QEM 2.5 used a temperature. It’s kind of funny. So QEM K 2.5 and GLM five both have temperature schedules, uh, and they both claim the exact opposite thing. So one of them says you have to start with a high temperature and go low. The other one says you have to have a low temperature and go high. And, uh, y- I don’t know. And then so, you know, you don’t see that discussion, uh, I, I don’t think in Some of the other papers, which is kind of interesting00:36:40 Nathan Lambert: Yeah. I, I still think the Chinese labs are much more willing to share, like really, really nitty-gritty tech details. The NVIDIA paper is like mostly a list of like methods to create a teacher or like-00:36:51 Finbarr Timbers: Yeah00:36:51 Nathan Lambert: ... domain-specific teachers, which is useful, but I think like I was less... It’s like less of a fun read. They’re like, there’s 15 pages of different domains, so I’m like, “Okay, I don’t, like I don’t need this.” Yeah, like KBK 2.5 and, uh, GLM 5 actually have like more similar recipes, which are also on the simpler side, which is like you create this SFT stage, and then you do RL. The RL might be staged. Um, there’s not this on-policy distillation. There’s a bit less talk on how many experts they have and what their domains of expert-s are. I think it, it’s obvious, like you have to take all this with a grain of salt, and it’s like what, how they decided to present the information is like a big factor in this. And then like they might actually be closer in reality and then it just wasn’t described in a certain way.00:37:44 Finbarr Timbers: I, I think another interesting bit is that you see the Chinese labs, uh, all seem to be converging towards sparse attention, whereas, uh, we don’t see the, you know, where was the American labs, at least NVIDIA and, you know, AI2 seem to be more converging towards hybrid attention. Uh, like N- uh, the NVIDIA Ne- Nemotron Ultra used the Mamba, um, attention, whereas, you know, we see, you know, DeepSeek sparse attention and then the Mimo, eh, MSA, whatever that stands for, Mimo Sparse Attention. So I, I think that’s, uh, an interesting divergence.00:38:20 Nathan Lambert: Yeah. I am not the person to ask, but I agree.00:38:23 Finbarr Timbers: [laughs]00:38:23 Nathan Lambert: It’s like I... Like I, I often get asked of like, this is to, to... Don’t, we’ll avoid the full rabbit hole, but I often get asked like, “Are the Chinese labs more efficient?” And I’m like, “I don’t really know how I’m gonna give you advice unless I’m spending twenty hours a week look, understanding the details of your recipe,” ‘cause it’s like, well, I can’t really give you a one sentence thing of do X without understanding all the complexities of the model and the post-training process that go into it. Which makes it, like makes it hard from kind of like a transparency point of view. Even if it’s fully detailed, it’s definitely still hard to modify and study.00:38:42 Finbarr Timbers: Yeah00:38:42 Nathan Lambert: ... like if you make a GPT model 1% more efficient, you’re making like fat stacks of profit. Like, I think that’s like a more effective market mechanism, but-00:38:53 Finbarr Timbers: And then-00:38:53 Nathan Lambert: The Chinese lab-00:38:54 Finbarr Timbers: You know-00:38:54 Nathan Lambert: Yeah00:38:55 Finbarr Timbers: ... if you make, you know, serving ChatGPT more efficient, Sam Altman can say, “Hey, here’s a bunch of stock.” Like, so yeah.00:39:02 Nathan Lambert: Yeah. But, uh-00:39:03 Finbarr Timbers: Um00:39:03 Nathan Lambert: ... they do great, like the Chinese labs do great research.00:39:05 Finbarr Timbers: Absolutely.00:39:05 Nathan Lambert: I just think it’s kind of a bit different. Okay, we can move into more open-ended stuff here.00:39:12 Finbarr Timbers: Sure.00:39:12 Nathan Lambert: I think that we have like a bunch of docu... We have th- a bunch of things in a document here. I’m sure more will come up. How do you think about open models and kind ‘cause i- it just doesn’t strike me that there’s this, like, you know, I think that there’s a large business to providing... Well, actually that’s not even super clear. There’s, you know, we’ve seen a number of companies providing, you know, RL fine-tuning services, you know, RL as a service. We’ve seen a lot of companies try to provide fine-tuning as a service, and, you know, none of them have really taken off. Like, I think OpenAI has started to shut down, I think they shut down their RL fine-tuning. I think they might be shutting down their fine-tuning. May be wrong about that.00:45:51 Nathan Lambert: Well, it’s like Cursor used Fireworks for their actual training run, and I’m like, I don’t really know all the details of this, but Cursor does something for fat- I think like fast weight tran- or Fireworks does-00:46:01 Finbarr Timbers: Yeah00:46:01 Nathan Lambert: ... a fast weight transfer and other things to make it so that they can scale their RL inference compute very nicely. So that’s one type of it. I don’t know how big of a long tail that business is, but also I think Tinker is a better business than most people expected. It makes some real amount of money. It’s like in the hierarchy, I think selling compute, not the best business.00:46:23 Finbarr Timbers: Yeah.00:46:23 Nathan Lambert: Selling inference, great business. And Tinker-like APIs, if you can’t transition it into selling tokens, is somewhere in between the two, where they could take some amount of margin that’ll be slightly higher than just selling the compute. And they obviously get a margin by having, like, they get compute at a cheaper rate than their customers-00:46:43 Finbarr Timbers: Yeah00:46:43 Nathan Lambert: ... and that’s like part of the margin they’re taking. But I don’t see it being as nice as inference, so it’s kind of existential for them to make it so that these fine-tuning APIs feed into a inference business pretty nicely.00:46:56 Finbarr Timbers: Yeah.00:46:56 Nathan Lambert: Because then you can be somewhat locked in on you train the model on our infrastructure. You actually can own the model weights, but the training dynamics to inference mismatch is perfect because you trained exactly on our inference engine, and are gonna get what you want out of it.00:47:11 Finbarr Timbers: Yeah. And it also helps a lot with utilization because you can then, you know, utilize it. You, you can share that utilization across a lot of clients. So I think it makes a lot of sense. I think it’s probably a better model for a lot of, um, users. Like, I think of academic users, like it probably makes way more sense to do this. Or, you know, for that matter, if you’re, you know, as, uh, uh, starting a new, um, ar- you know, post-training lab now, as you know, I, I know a few people, um, who are. Like, I think that’s where it, it probably makes a lot of sense to start with something like the Tinker API, and then, you know, at some point if you wanna try and capture that margin, maybe then you try to do something more custom. But if you, if you can use something like that, like that’s great, and the economics are just, you know, fundamentally more sustainable. I or, you know, they’re better for you rather than trying to, you know, g- go to CoreWeave or whoever and say, or Serv scale and say, “Hey, I need, you know, 10,000 networked, uh, DB200s,” you know? That’s just a very expensive, um, thing to do, especially if you can’t keep it running all the time.00:48:14 Nathan Lambert: Yeah. Do you have a, do you have any more hot takes on post-training before I ask you some more general things?00:48:22 Finbarr Timbers: Uh, well, something I’m, I’m generally interested in and, you know, I, I’m the wrong person to, to speak to about it. I’d love to talk to someone who’s maybe a, a, a capital allocator, like who’s, you know, deciding or a compute allocator who’s deciding where to put, uh, compute or, you know, where to hire team members. Um, because I’m kind of curious how Uh, the high level decisions are made allocating resources between pre-training and post-training. Uh, ‘cause, you know, what I kind of have seen as, as a general trend is, is that you see a lot of papers where there’s, you know, more focus put on one or the other. Uh, like I think... So, so yeah, so that’s something kind of interesting to me is how people who are, you know, making this decision, how, how they’re making that decision and how they’re thinking about it.00:49:10 Nathan Lambert: Yeah. It’s like the hardest decision to get out of labs. I’ve like, I used to spend time trying to get them to share more, but I, I think it’s like such a sensitive decision to where they see progress coming. Like they’re making that decision ba- allocating compute based on where they think the most progress is and what the like return on investment is. So if you go to Anthropic and they’re like, “Here’s where our percent, here’s our distributions,” it’s like, okay, that’s where labs see their bets and/or where they see they are weak.And it’s like you invest more compute in the pro- to make progress in the area that you are interested in, which I always think makes a lot of the open research kind of boring right now, is like the people that get compute are just way more likely to succeed as academics and researchers, which is a horrible equilibrium for the world, but kind of realistically true. I, I, I don’t know how to make a lot of that. I wanted to ask you how you feel about the craze that people have to cash in on making money and join a lab before the ladder gets pulled up, and what people should be optimizing for in their careers in face of meaningful opportunity costs.00:50:18 Finbarr Timbers: Yeah. I think it’s, well, that’s actually very, very timely. Uh, but yeah, no, I, I think that that’s, um, really important to, to talk about. I mean, I think it’s always worth focusing on whether what you’re doing and spending time on is gonna be generally valuable or if it, if it’s like a really short-term exploitation type thing in, in the, you know, RL like explore versus exploit setup. I, I mean, something that I’ve seen throughout my career has been often the places that pay the most, um, are also the places where you’re doing the most interesting work, right? Like, you know, if, if you’re gonna go work at OpenAI, OpenAI or, you know, Anthropic or the Frontier Lab, like they pay a lot of money. They also have a lot of resources, so you’re gonna make a lot of money and learn a lot.Um, uh, so I think it’s worth trying to decide i- is that the, is the opportunity that you’re doing that or is the, is the opportunity like, you know, in 2021 or 2022 or whatever, where you might say, you know, I was at DeepMind at the time and it’s like, okay, do I work at DeepMind, which paid a lot less than like crypto? Should I go just, you know, work in crypto and try to, you know, mint NFTs or whatever? I think that would’ve been a mistake, but, you know, trying to figure out, um, if you’re gonna be able to do interesting work is really important and also, you know, try to figure out if you’re going to be able to, you know, push forward science. You know, if, if what you’re doing is more just saying, going to, you know, data vendors and saying, you know, “Okay, you know, we, I need a bunch of data to do whatever.” And then, you know, they, they give you a bunch of data, you train a model, you say it’s good or bad or whatever.You know, I don’t think that’s as interesting and, and I don’t think you’re gonna learn a lot even though that’s, you know, work that would probably drive model progress for it. I think if you’re able to, you know, make, focus more on the science and make more scientific conclusions, I think that can be, you know, a lot better for your long-term career. And I think that’s where places like AI2 and the other, um, academic research labs, you know, Marin is doing a really great job of this. Um, I think that’s where you can have a lot of impact in that they don’t have the budget to go and buy a lot of data, and so that leverage just really isn’t, um, open to them to pull. And so they have to focus on science and driving innovation, and that’s where you can see things like the Almix, uh, paper, which I thought was a really excellent, uh, sc- you know, scientific paper, but also, you know, meaningfully, I think, advanced, uh, the state of the art.00:52:32 Nathan Lambert: Yeah. No, mostly this is grounded in visiting the Bay Area, and every time I go I’m like, “Holy s**t, what is going on here?” Like all these very junior people are like have way too much dread about their, uh, opportunity cost and both of us aren’t based in the Bay Area, so I feel-00:52:46 Finbarr Timbers: No00:52:46 Nathan Lambert: ... somewhat removed from it, which gives me a little bit more time to pause and be like, what exactly is the right thing to optimize for? I per- I-- it’s easy for me to say as somebody that’s established, but I think there’s opportunity for a lot of people to just, if they have conviction on something, to try to go and do it and not just follow everybody that goes down the funnel of joining one of the established labs or the Neo labs where I don’t hear from many people that join as a junior person at these places and end up with very high responsibility. Like they’re contributing to something that matters or they’re around a cool group of people, but I don’t hear from that many people that are like, “Wow, I am doing the highest leverage stuff and the most interesting things.”00:53:30 Finbarr Timbers: Well, I think that, you know, it’s kind of funny for, for me to say this as I, my career has been more on, on the opportunistic, uh, side of things. Um, but you know, twice now, uh, I’ve been at organizations where, um, I, I’ve been working... So, you know, at, at DeepMind, uh, I, I was part of the Alberta office where DeepMind had, you know, aqua hired the, uh, computer poker research group from the University of Alberta. And so, you know, this was a group of people who were really invested in, uh, computational game theory and g- you know, poker playing, um, algorithms. And they were all in on that and, you know, they, they were all in on that to the point that, you know, they were one of the two leading, uh, labs in the field and, um, were, you know, b-because they were so strong at this, they were then, you know,DeepMind came and, you know, acquihired them and, and they all joined and they, you know, did quite well from that, um, acquisition there. And then, you know, you know, I joined later because I was, uh, you know, interested in, in working with them and doing game theory and stuff. But you know, it was this group of people who had this conviction that what they were doing was really important and, you know, it worked out quite well for them. And then, you know, the same thing at AI2, where at AI2, you know, there was all of these people who were really interested in, uh, NLP research, you know, even before language models. Like we see people like, you know, like Kyle a-and Dirk I think were both at AI2 for like almost a, a decade.Like they had these really long tenures, um, and then they did really well and then, you know, they’ve, they’ve since had some, you know, strong, um, opportunities, uh, coming out of that with, with, um, yeah, some of the opportunities that have been available to them. And I, and I think that the consistent theme there has been that, you know, if you have high conviction that what you’re doing is important and interesting, then like it, it’s not a mistake to follow that and to, you know, try to become really strong, um, in that area.00:55:15 Nathan Lambert: Yeah. I mostly think it’s good for the world to have a di- more diverse set of approaches.00:55:19 Finbarr Timbers: Yeah.00:55:19 Nathan Lambert: It’ll be interesting to see what the deal labs actually produce if, if they can manage to do things that are diverse. My personal idea is that they’re so big now that most of them need to end up doing something that is somewhat similar, which is-00:55:33 Finbarr Timbers: Yeah00:55:34 Nathan Lambert: ... hard, but like they need to keep risking the comp- they effectively need to risk their $20 billion valuations to do something interesting that’s not just gonna be like squashed by an OpenAI or Anthropic side project.00:55:48 Finbarr Timbers: Yeah, absolutely. And I think it’s tough because when you’re raising, when you’re, you know, you have these huge seed rounds and you’re raising, you know, 200 million or, you know, a billion dollars or whatever, then it’s like you have to pretty quickly show results to be able to-00:56:01 Nathan Lambert: Yeah00:56:01 Finbarr Timbers: ... you know, grow off of that.00:56:04 Nathan Lambert: Yeah. So a to-be continued conversation.00:56:11 Nathan Lambert: Any last words? I don’t, I don’t need to stretch it on if we don’t have anything to add to our conversation.00:56:16 Finbarr Timbers: No, I, I think this was pretty good. I think it was really great, uh, getting a chance to catch up and talk about some of this stuff. You know, I, I’ve been reading all of these papers and thinking about all the different recipes, so it’s great to get to, um, to chat about it and put it out into the ether. So yeah, thanks for having me on.00:56:31 Nathan Lambert: Yeah, thanks for coming back. We’ll talk soon.00:56:33 Finbarr Timbers: Sounds good. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 56m 36s | ||||||
| 6/9/26 |  Claude Fable 5 and new AI safety fables✨ | AI safetyClaude Fable 5+3 | — | Claude Fable 5Anthropic+1 | — | AIsafety measures+4 | — | 12m 11s | |
| 6/2/26 |  Farewell Ai2✨ | AIcareer transition+3 | — | Allen Institute for AI | — | Allen Institute for AIAI models+3 | — | 15m 51s | |
| 6/1/26 |  Open and closed models are on different exponentials✨ | AI modelseconomic debate+3 | — | Opus 4.5Codex 5.2 | — | AI modelseconomic debate+3 | — | 7m 21s | |
| 5/26/26 | 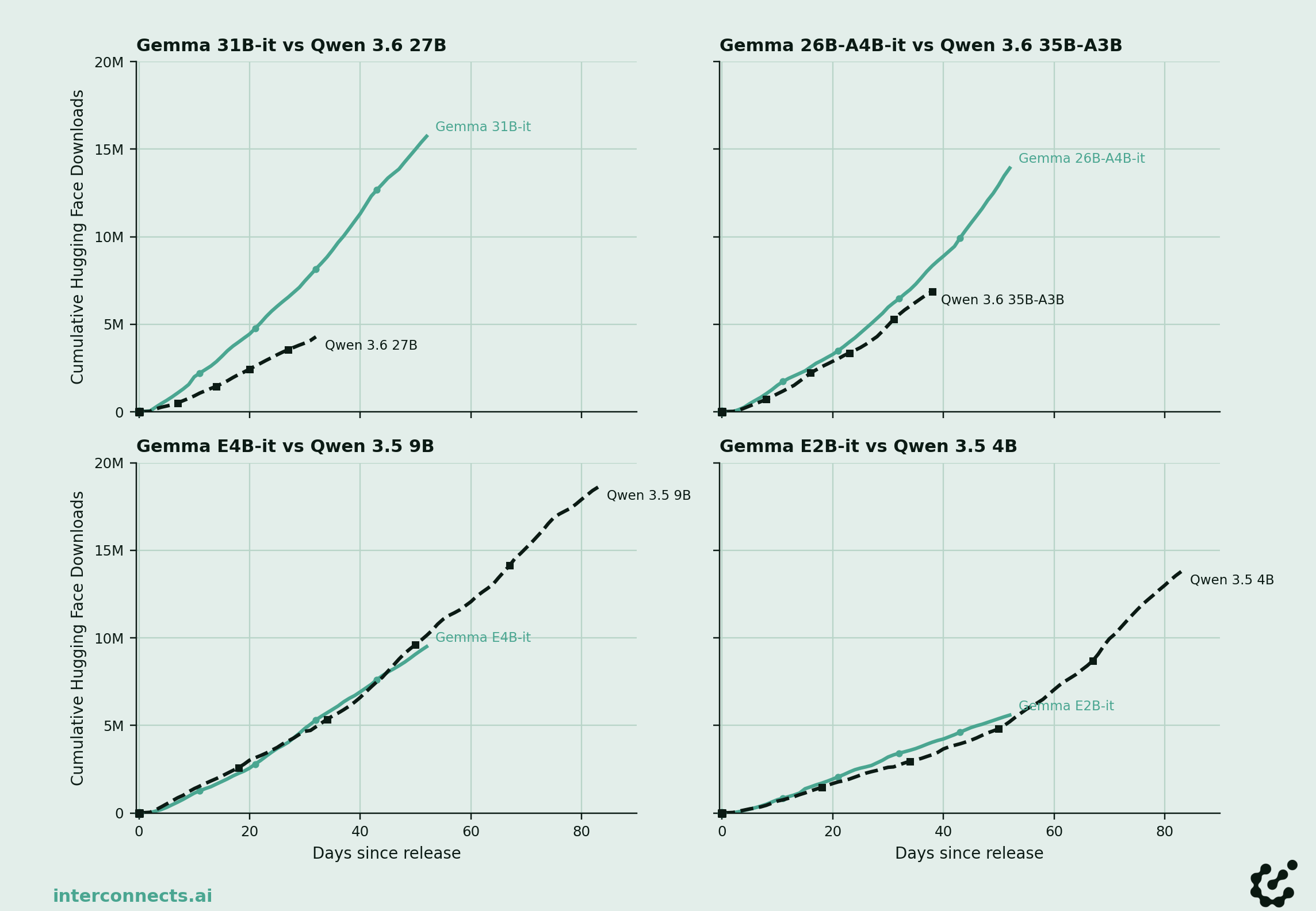 Some ideas for what comes next, May 2026✨ | AI progresseconomic implications of AI+3 | — | Opus 4.5Claude Code | — | AIOpus 4.5+5 | — | 9m 37s | |
| 5/7/26 |  Notes from inside China's AI labs✨ | AI researchChinese technology+3 | — | Interconnects AI | ChinaHangzhou+1 | AIChina+5 | — | 16m 35s | |
| 5/4/26 |  The distillation panic✨ | distillation attacksAI capabilities+3 | — | AnthropicChinese labs | ChinaU.S. | distillation attacksAI+5 | — | 8m 52s | |
Want analysis for the episodes below?Free for Pro Submit a request, we'll have your selected episodes analyzed within an hour. Free, at no cost to you, for Pro users. | |||||||||
| 4/15/26 |  My bets on open models, mid-2026✨ | open modelsAI capabilities+3 | — | — | — | open modelsclosed labs+3 | — | 6m 57s | |
| 4/11/26 |  The inevitable need for an open model consortium✨ | open modelsAI consortium+4 | Percy Liang | StanfordNemotron+7 | — | open modelsAI consortium+6 | — | 5m 45s | |
| 4/9/26 |  Claude Mythos and misguided open-weight fearmongering✨ | AI modelscybersecurity+3 | — | Claude MythosOpenAI | — | Claude Mythosopen-weight models+5 | — | 8m 36s | |
| 4/3/26 |  Gemma 4 and what makes an open model succeed✨ | open modelsAI development+4 | — | Gemma 4Llama 3+16 | — | open modelsAI+6 | — | 8m 55s | |
| 3/22/26 |  Lossy self-improvement✨ | AI developmentrecursive self-improvement+4 | — | AIAI industry+5 | — | AIrecursive self-improvement+5 | — | 13m 23s | |
| 3/18/26 | 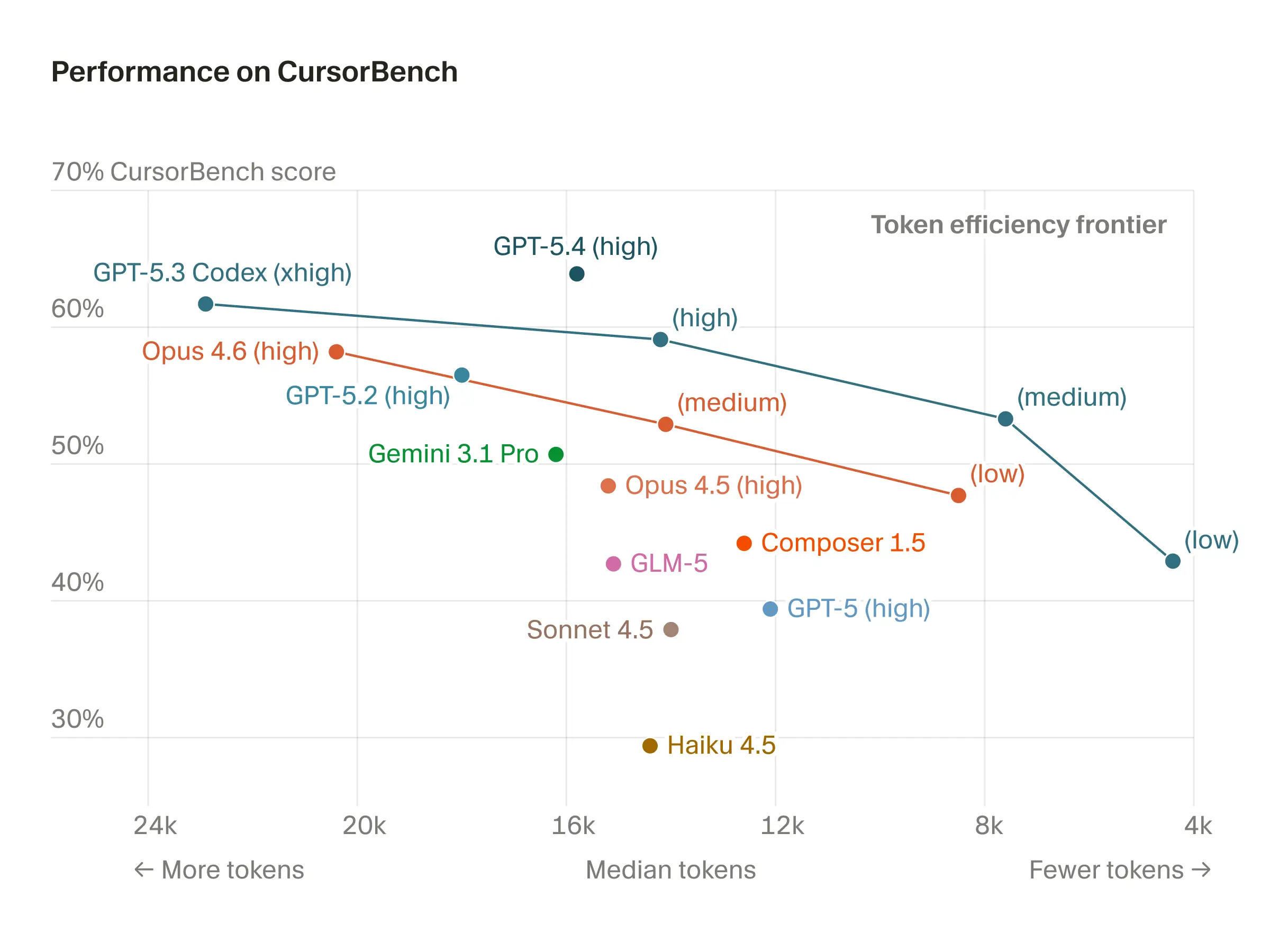 GPT 5.4 is a big step for Codex✨ | AImodel review+3 | — | GPT 5.4Codex+1 | — | GPT 5.4Codex+4 | — | 6m 49s | |
| 3/16/26 |  What comes next with open models✨ | open modelsAI ecosystem+3 | — | LlamaDeepSeek | — | open modelsAI+5 | — | 18m 08s | |
| 3/6/26 |  Dean Ball on open models and government control✨ | open modelsgovernment control+3 | Dean W. Ball | AnthropicDepartment of War+2 | — | open modelsAI+5 | — | 35m 36s | |
| 3/5/26 | 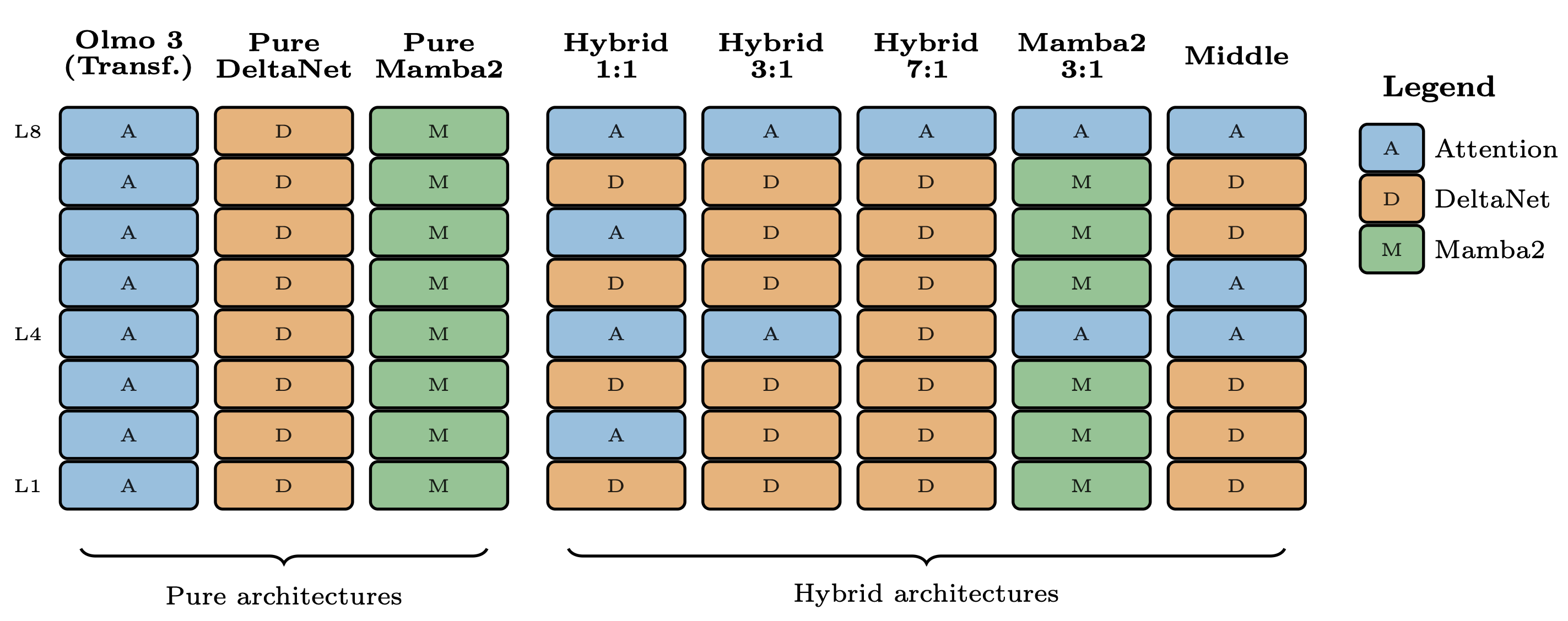 Olmo Hybrid and future LLM architectures✨ | hybrid architecturesopen-weight models+4 | — | Qwen 3.5Kimi Linear+9 | — | hybrid modelsRNN+6 | — | 11m 21s | |
| 2/24/26 |  How much does distillation really matter for Chinese LLMs?✨ | distillationAI+4 | — | Chinese labsAmerican API-based counterparts | — | distillationsynthetic data+4 | — | 11m 20s | |
| 2/9/26 |  Opus 4.6, Codex 5.3, and the post-benchmark era | Last Thursday, February 5th, both OpenAI and Anthropic unveiled the next iterations of their models designed as coding assistants, GPT-5.3-Codex and Claude Opus 4.6, respectively. Ahead of this, Anthropic had a firm grasp of the mindshare as everyone collectively grappled with the new world of agents, primarily driven by a Claude Code with Opus 4.5-induced step change in performance. This post doesn’t unpack how software is changing forever, Moltbook is showcasing the future, ML research is accelerating, and the many broader implications, but rather how to assess, live with, and prepare for new models. The fine margins between Opus 4.6 and Codex 5.3 will be felt in many model versions this year, with Opus ahead in this matchup on usability.Going into these releases I’d been using Claude Code extensively as a general computer agent, with some software engineering and a lot of data analysis, automation, etc. I had dabbled with Codex 5.2 (usually on xhigh, maximum thinking effort), but found it not to quite work for me among my broad, horizontal set of tasks.For the last few days, I’ve been using both of the models much more evenly. I mean this as a great compliment, but Codex 5.3 feels much more Claude-like, where it’s much faster in its feedback and much more capable in a broad suite of tasks from git to data analysis (previous versions of Codex, including up to 5.2, regularly failed basic git operations like creating a fresh branch). Codex 5.3 takes a very important step towards Claude’s territory by having better product-market fit. This is a very important move for OpenAI and between the two models, Codex 5.3 feels far more different than its predecessors.OpenAI’s latest GPT, with this context, keeps an edge as a better coding model. It’s hard to describe this general statement precisely, and a lot of it is based on reading others’ work, but it seems to be a bit better at finding bugs and fixing things in codebases, such as the minimal algorithmic examples for my RLHF Book. In my experience, this is a minor edge, and the community thinks that this is most apparent in complex situations (i.e. not most vibe-coded apps). As users become better at supervising these new agents, having the best top-end ability in software understanding and creation could become a meaningful edge for Codex 5.3, but it is not an obvious advantage today. Many of my most trusted friends in the AI space swear by Codex because it can be just this tiny bit better. I haven’t been able to unlock it.Switching from Opus 4.6 to Codex 5.3 feels like I need to babysit the model in terms of more detailed descriptions when doing somewhat mundane tasks like “clean up this branch and push the PR.” I can trust Claude to understand the context of the fix and generally get it right, where Codex can skip files, put stuff in weird places, etc.Both of these releases feel like the companies pushing for capabilities and speed of execution in the models, but at the cost of some ease of use. I’ve found both Opus 4.6 and Codex 5.3 ignoring an instruction if I queue up multiple things to do — they’re really best when given well-scoped, clear problems (especially Codex). Claude Code’s harness has a terrible bug that makes subagents brick the terminal, where new messages say you must compact or clear, but compaction fails. Despite the massive step by Codex, they still have a large gap to close to Claude on the product side. Opus 4.6 is another step in the right direction, where Claude Code feels like a great experience. It’s approachable, it tends to work in the wide range of tasks I throw at it, and this’ll help them gain much broader adoption than Codex. If I’m going to recommend a coding agent to an audience who has limited-to-no software experience, it’s certainly going to be Claude. At a time when agents are just emerging into general use, this is a massive advantage, both in mindshare and feedback in terms of usage data.In the meantime, there’s no cut-and-dried guideline on which agent you need to use for any use-case, you need to use multiple models all the time and keep up with the skill that is managing agents. Interconnects AI is a reader-supported publication. Consider becoming a subscriber.Assessing models in 2026There have been many hints through 2025 that we were heading toward an AI world where benchmarks associated with model releases no longer convey meaningful signal to users. Back in the time of the GPT-4 or Gemini 2.5 Pro releases, the benchmark deltas could be easily felt within the chatbot form factor of the day — models were more reliable, could do more tasks, etc. This continued through models like OpenAI’s o3. During this phase of AI’s buildout, roughly from 2023 to 2025, we were assembling the core functionality of modern language models: tool-use, extended reasoning, basic scaling, etc. The gains were obvious.It should be clear with the releases of both Opus 4.6 and Codex 5.3 that benchmark-based release reactions barely matter. For this release, I barely looked at the evaluation scores. I saw that Opus 4.6 had a bit better search scores and Codex 5.3 used far fewer tokens per answer, but neither of these were going to make me sure they were much better models. Each of the AI laboratories, and the media ecosystems covering them, have been on this transition away from standard evaluations at their own pace. The most telling example is the Gemini 3 Pro release in November of 2025. The collective vibe was Google is back in the lead. Kevin Roose, self-proclaimed “AGI-pilled” NYTimes reporter in SF said:There's sort of this feeling that Google, which kind of struggled in AI for a couple of years there — they had the launch of Bard and the first versions of Gemini, which had some issues — and I think they were seen as sort of catching up to the state of the art. And now the question is: is this them taking their crown back?We don’t need to dwell on the depths of Gemini’s current crisis, but they have effectively no impact at the frontier of coding agents, which as an area feels the most likely for dramatic strides in performance — dare I say, even many commonly accepted definitions of AGI that center around the notion of a “remote worker?” The timeline has left them behind 2 months after their coronation, showing Gemini 3 was hailed as a false king.On the other end of the spectrum is Anthropic. With Anthropic’s release of Claude 4 in May of 2025, I was skeptical of their bet on code — I was distracted by the glitz of OpenAI and Gemini trading blows with announcements like models achieving IMO Gold medals in mathematics or other evaluation breakthroughs.Anthropic deserves serious credit for the focus of its vision. They were likely not the only AI lab to note the coming role of agents, but they were by far the first to shift their messaging and prioritization towards this. In my post in June of 2025, a month after Claude 4 was released, I was coming around to them being right to deprioritize standard benchmarks:This is a different path for the industry and will take a different form of messaging than we’re used to. More releases are going to look like Anthropic’s Claude 4, where the benchmark gains are minor and the real world gains are a big step. There are plenty of more implications for policy, evaluation, and transparency that come with this. It is going to take much more nuance to understand if the pace of progress is continuing, especially as critics of AI are going to seize the opportunity of evaluations flatlining to say that AI is no longer working.This leaves me reflecting on the role of Interconnects’ model reviews in 2026. 2025 was characterized by many dramatic, day-of model release blog posts, with the entry of many new Chinese open model builders, OpenAI’s first open language model since GPT-2, and of course the infinitely hyped GPT-5. These timely release posts still have great value — they center the conversation around the current snapshot of a company vis-a-vis the broader industry, but if models remain similar, they’ll do little to disentangle the complexity in mapping the current frontier of AI. In order to serve my role as an independent voice tracking the frontier models, I need to keep providing regular updates on how I’m using models, why, and why not. Over time, the industry is going to develop better ways of articulating the differences in agentic models. For the next few months, maybe even years, I expect the pace of progress to be so fast and uneven in agentic capabilities, that consistent testing and clear articulation will be the only way to monitor it. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 8m 09s | ||||||
| 2/4/26 |  Why Nvidia builds open models with Bryan Catanzaro | One of the big stories of 2025 for me was how Nvidia massively stepped up their open model program — more releases, higher quality models, joining a small handful of companies releasing datasets, etc. In this interview, I sat down with one of the 3 VP’s leading the effort of 500+ technical staff, Bryan Catanzaro, to discuss:* Their very impressive Nemotron 3 Nano model released in Dec. 2025, and the bigger Super and Ultra variants coming soon,* Why Nvidia’s business clearly benefits from them building open models,* How the Nemotron team culture was crafted in pursuit of better models,* Megatron-LM and the current state of open-source training software,* Career reflections and paths into AI research,* And other topics.The biggest takeaway I had from this interview is how Nvidia understands their unique roll as a company that and both build and directly capture the value they get from building open language models, giving them a uniquely sustainable advantage. Bryan has a beautiful analogy for open models this early in AI’s development, and how they are a process of creating “potential energy” for AI’s future applications.I hope you enjoy it!Guest: Bryan Catanzaro, VP Applied Deep Learning Research (ADLR), NVIDIA. X: @ctnzr, LinkedIn, Google Scholar.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Nemotron Model Timeline2019–2022 — Foundational Work* Megatron-LM (model parallelism framework that has become very popular again recently; alternatives: DeepSpeed, PyTorch FSDP). * NeMo Framework (NVIDIA’s end-to-end LLM stack: training recipes, data pipelines, evaluation, deployment).Nov 2023 — Nemotron-3 8B: Enterprise-ready NeMo models. Models: base, chat-sft, chat-rlhf, collection. Blog.Feb 2024 — Nemotron-4 15B: Multilingual LLM trained to 8T tokens. Paper.Jun 2024 — Nemotron-4 340B: Major open release detailing their synthetic data pipeline. Paper, blog. Models: Instruct, Reward. Jul–Sep 2024 — Minitron / Nemotron-Mini: First of their pruned models, pruned from 15B. Minitron-4B (base model), Nemotron-Mini-4B-Instruct. Paper, code.Oct 2024 — Llama-3.1-Nemotron-70B: Strong post-training on Llama 3.1 70B. Model, collection. Key dataset — HelpSteer2, paper.Mar–Jun 2025 — Nemotron-H: First hybrid Mamba-Transformer models for inference efficiency. Paper, research page, blog. Models: 8B, 47B, 4B-128K.May 2025 — Llama-Nemotron: Efficient reasoning models built ontop of Llama (still!). Paper.Sep 2025 — Nemotron Nano 2: 9B hybrid for reasoning, continuing to improve in performance. 12B base on 20T tokens (FP8 training) pruned to 9B for post-training. Report, V2 collection.Nov 2025 — Nemotron Nano V2 VL: 12B VLM. Report.Dec 2025 — Nemotron 3: Nano/Super/Ultra family, hybrid MoE, up to 1M context. Super/Ultra H1 2026. Nano: 25T tokens, 31.6B total / ~3.2B active, releases recipes + code + datasets. Papers: White Paper, Technical Report. Models: Nano-30B-BF16, Base, FP8.Nemotron’s Recent DatasetsNVIDIA began releasing substantially more data in 2025, including pretraining datasets — making them one of few organizations releasing high-quality pretraining data at scale (which comes with non-negligible legal risk).Pretraining DataCollection — CC-v2, CC-v2.1, CC-Code-v1, Code-v2, Specialized-v1, CC-Math-v1. Math paper: arXiv:2508.15096.Post-Training DataCore post-training dumps (SFT/RL blends):* Llama Nemotron Post-Training v1.1 (Apr 2025)* Nemotron Post-Training v1 (Jul 2025)* Nemotron Post-Training v2 (Aug 2025)2025 reasoning/code SFT corpora:* OpenMathReasoning (Apr 2025)* OpenCodeReasoning (Apr 2025), OpenCodeReasoning-2 (May 2025)* AceReason-1.1-SFT (Jun 2025)* Nemotron-Math-HumanReasoning (Jun 2025), Nemotron-PrismMath (Apr 2025)NeMo Gym RLVR datasets: CollectionNemotron v3 post-training (Dec 2025): CollectionHelpSteer (human feedback/preference):* HelpSteer (Nov 2023)* HelpSteer2 (Jun 2024)* HelpSteer3 (Mar 2025)And others, not linked here.Chapters* 00:00:00 Intro & Why NVIDIA Releases Open Models* 00:05:17 Nemotron’s two jobs: systems R&D + ecosystem support* 00:15:23 Releasing datasets, not just models* 00:22:25 Organizing 500+ people with “invitation, not control”* 0:37:29 Scaling Nemotron & The Evolution of Megatron* 00:48:26 Career Reflections: From SVMs to DLSS* 00:54:12 Lessons from the Baidu Silicon Valley AI Lab* 00:57:25 Building an Applied Research Lab with Jensen Huang * 01:00:44 Advice for Researchers & Predictions for 2026Transcript00:00:06 Nathan Lambert: Okay. Hey, Bryan. I’m very excited to talk about Nemotron. I think low-key, one of the biggest evolving stories in twenty-five of open models, outside the obvious things in China that everybody talks about, that gets a ton of attention. So th- thanks for coming on the pod.00:00:22 Bryan Catanzaro: Oh, yeah, it’s my honor.00:00:23 Nathan Lambert: So I wanted to start, and some of these questions are honestly fulfilling my curiosity as a fan. As like, why does NVIDIA, at a basic level, release Nemotron as open models?00:00:39 Bryan Catanzaro: Well, we know that it’s an opportunity for NVIDIA to grow our market whenever AI grows, and we know that having access to open AI models is really important for a lot of developers and researchers that are trying to push AI forward. you know, we were really excited by efforts from some other companies around the industry to push openly developed AI forward. You know, Meta did some amazing work, obviously, with Llama and you know OpenAI released GPT OSS, which was exciting. And the Allen Institute, of course, has been, you know, really leading the charge for research, open research and, you know, also things like the Marin Project and OpenAthena. You know, like there’s, there’s a bunch of things that we’re always excited to see develop.And, you know, as we think about where AI is gonna go, you know, NVIDIA believes that AI is a form of infrastructure. it’s.. AI is a very useful technology when it’s applied, but on its own you know, it’s kind of a foundation and infrastructure. We think that technology generally works better when there’s openness to the infrastructure so that people can build things in different ways. You know, you think about the way that the internet transformed every aspect of the world economy is pretty profound, and we’re not done yet.But the way that, for example, retail uses the internet is different from the way that healthcare uses the internet. And the fact that you know, different sectors of the economy were able to figure out how to incorporate the internet into the beating heart of their businesses in different ways was possible because the internet was built on open technologies that, you know, allowed people to try different things. And we think AI is gonna evolve in a similar way, that organizations across every sector of the world economy are gonna find new and surprising and fun, and important things to do with AI, and they’ll be able to do that better if they have the ability to customize AI and incorporate it directly into the work that they do. and so -- and by the way, this is not to detract from any of the you know, more closed approaches to AI, you know, the APIs that we see from a number of leading labs that, you know, are just extraordinary and have amazing capabilities. We’re excited about those, too.You know, NVIDIA loves to support AI in all of its manifestations, but we feel like right now the sort of closed approaches to deploying AI are doing pretty well but we, you know, could use some more energy in the openly developed AI ecosystem, and so that’s why we’ve been putting more effort into it this past year.00:03:42 Nathan Lambert: Yeah. So I’m definitely gonna dig into this a lot ‘cause I have seen this. We’re sitting here recording in January twenty-six, which is in the midst of the rollout of these Nemotron three models. There’s the-- I think the Nano has released in the fall, which was probably one of the biggest splashes the org has made, and everybody’s eagerly awaiting these super and ultra-larger variants.And it’s like how far are you, how far are you willing to push this Nemotron platform? Like, is it just depending on the users and the uptake and the ecosystem? Like, like, what is the-- is there a North Star in this? Or you hear a lot of.. if you listen to a lot of other open labs, they’re like: “We want to build open AGI,” which is like, I don’t necessarily think grounded, but there’s like a very unifying vision.Is there something that you try to set the tone for it that goes through the organization? I mean, AI too, it’s like-00:04:31 Bryan Catanzaro: You know, my North-00:04:32 Nathan Lambert: .. academics is so-00:04:34 Bryan Catanzaro: For Nemotron.00:04:36 Nathan Lambert: Okay, go ahead.00:04:37 Bryan Catanzaro: Oh, sorry. Go ahead.00:04:39 Nathan Lambert: I was just, like, gonna compare to, like, AI too, where we can have such a-- like, we have a very specific vision, being so open that it’s like, I think, like, research is so needed, and there’s so little recipes to build on, like, with really credible research. So there’s, like, a research infrastructure, and then when you have something like Llama, it was, like, built on Zuckerberg’s vision, and he changed his mind, which I actually thought his vision was ex- was excellent, the way he articulated the need for open models, and it kind of faded. So it’s like, is there a way to set a vision for an org that, like, permeates every- everyone and is really compelling and exciting?00:05:17 Bryan Catanzaro: Right. Well, we built Nemotron for two main reasons. The first is because we need to for our main product line. So what I mean by that?Well, accelerated computing, what NVIDIA does, we build fast computers, right? But the point of building fast computers is to help people do new things. and actually every fast computer is also a slow computer. you know, the observation that it would be nice if computers were faster and could do more things isn’t new. that’s been around since the beginning of computing. So what makes accelerated computing different from standard computing is that we’re prioritizing, you know, we’re focusing, we’re deciding we’re gonna accelerate this workload. This other workload, which is like ninety-nine percent of all of the workloads, we’re gonna let somebody else do that, right?So, like, you do not buy NVIDIA systems to do any general purpose computation. You buy them for a purpose, right? Which is these days, all about AI. But when you think about the workload, the compute workloads involved in AI there’s a, there’s a lot of diversity and there’s a lot of really important -.. parameters, hyperparameters, or algorithmic approaches that all have enormous imp- impacts on the systems that we need to build for AI.So things like numeric precision MoE architecture, which of course, influence net-- it influences network design. you know, we’re dreaming about sparsity. We, you know, we’ve had, we’ve had sparse neural network acceleration in the GPU since Ampere. I don’t think that it’s being used enough. you know, so how do we, how do we figure out how to use that? These, these sorts of things have an enormous impact on the future of NVIDIA’s main product line, and we have to understand the answers to those questions deeply ourselves in order to know what we’re going to build.We can’t just go to our customers and do a survey and say, “Hey “ you know, Meta, for example, since we were just talking about them, “what would you like to see in a future product line from NVIDIA?” Of course, Meta’s always trying to help us as much as they can, but there’s limits to what they can tell us because, you know a lot of the information that influences the design of these systems, it’s very expensive to derive, and so therefore, it’s, it’s very closely held. And so we need to be able to understand these questions very deeply in order to understand what kind of systems to build, in order to understand what we’re accelerating in AI and what we’re not gonna worry about. and so that’s kind of the first job for Nemotron models, is to make it possible for NVIDIA to continue to exist as a company. And I think it’s important that the community knows that because that’s the reason why NVIDIA is making the investments in Nemotron, is because we believe it’s essential for the future of our company. and so this isn’t-- and although as much, as much as it feels good to say, you know, NVIDIA believes in open openly developed AI because you know, we’re so charitable, but actually, that’s not the case. This is actually a business decision-00:08:34 Nathan Lambert: It’s smart00:08:34 Bryan Catanzaro: .. like, for NVIDIA, our business needs us to know about AI very deeply. And and so, you know, the amount of investment that is justified to carry on NVIDIA’s ongoing business, I think, is large. and so that’s that’s job number one for Nemotron. Now job number two for Nemotron is to support the ecosystem more broadly outside of NVIDIA. and, you know, NVIDIA has a special position in the AI landscape. of all of the big AI companies I think we’re the one that works with the most other companies. We support every company small and large, AI native company to old established enterprise.We work with hyperscalers, we work with tiny little startups, we work with countries around the world. so we have this unique position and I think also a uni- unique responsibility and al- maybe also a unique opportunity, that whenever AI is able to grow in any sort of direction, in any capability, then you know, that’s an opportunity for us to grow our business. Obviously, it’s not automatic, right? you know, the AI market is diverse, and it’s getting more diverse, and it should be, ‘cause it’s the most important market in the history of humanity. So so we acknowledge that, and at the same time, we know that it’s in our interest to develop the AI ecosystem. The more people that are building, inventing, and deploying AI, the more opportunity that we have as a company.So that’s job number two for Nemotron.00:10:17 Nathan Lambert: Yeah. I really appreciate you saying it so directly ‘cause it’s like we’ve worked.. We- I launched this thing, the Adam Project, last summer, which is trying to get more investment in the US open models, and it’s like the only company that has an obvious business model for open models is something like NVIDIA, where you need to make sure that the open models and the research ecosystem plays nicely on CUDA, because then you’re gonna be able to be one-- You’re so many steps closer to research that’s happening. If not, like, if it like- There’s such an advantage to have research happen mostly on GPUs relative to AMD or anything like this, so.00:10:49 Bryan Catanzaro: Well, you know, we are-- we’re, we’re not thinking about how to prevent competition. You know, we welcome competition. There’s lots of competition. There should be more competition in this space, but we are very self-interested in staying engaged with the community.You know, it’s very important. You know, CUDA not many people remember this because it happened so long ago, but you know, CUDA started out with a lot of outreach from NVIDIA to the academic and industrial community saying, “Hey, we have this new way of doing computing. we’d love to see what you can do with it.” In fact, you know, I started using CUDA in 2006 when I was a grad student at Berkeley because David Kirk, who was the chief scientist of NVIDIA at the time, came over to Berkeley and said, “Hey we just released this new GPU, and it has this new programming model called CUDA. You should give it a try.” And I was-- at the time, I was working on machine learning on FPGAs, and I had been working on this one particular piece of support vector machine training on the FPGA, and I decided to take that little piece and write it in CUDA, and it took me like fifteen minutes, and then I ran it, and it was like two hundred times faster than my single-threaded CPU code, and I was like: “Whoa, that was way easier than what I was doing before. I’m just gonna go do that,” right?So, like, my own personal involvement with CUDA and NVIDIA came about because of this outreach that NVIDIA conducted right from the beginning of CUDA. you know, of course, that led to a lot of great things for NVIDIA, including AlexNet, which was another academic project, you know, where Alex Krizhevsky and Ilya Sutskever were thinking about: “How do we train larger neural networks on more data? we’re gonna go write a bunch of GPU code that uses the GPU in a, in a kinda new and clever way, so that we can train a better image classification model.” And, you know, that had such astonishing results, it kicked off the deep learning era for the whole community. and again, not something that-.. could have been done top-down. That was a, that was a very much a result of NVIDIA supporting open development and re- research in parallel computing and artificial intelligence. And so we remember that, and we’re thinking about in twenty-six, what does it look like to help, you know, the Alex Krizhevsky of the future, who’s, who’s a grad student in a lab somewhere, invent the next technology that changes the world? It seems really difficult to do that without something like Nemotron or, or the other openly developed AI projects out there. yeah, I also wanna say in regards to this Nemotron is not trying to be the only project out there.We’re part of the community. We love other people doing great work in openly developed AI. We learn from things that other people do and you know, so we’re, we’re trying to support the community because it’s in our interest, but we you know, we’re very happy to see other people contributing as well.00:13:57 Nathan Lambert: Yeah, I mean, I can transition into something I wanted to ask about is like, I see multiple ways, twenty-five Nemotron mat-- in, I don’t wanna use the word maturing ‘cause I wanna ask you about how it feels in the org, but just like the output reached levels that were more noticed by the community and people building with models. And there’s a lot of ways that can happen, but one of them is like, in my niche community, I’ve been using Nemotron datasets a lot. Like we-- when we redo our post-training recipe, one of the only people we look at is like, okay, NVIDIA, Nemotron has released a lot of high-quality, openly licensed post-training data. this year, you also started releasing some pre-training data, which among AI2 got a lot of notice. Like, what is that? is that like a distinct shift within Nemotron?Is that something that you’ve wanted to do for a while and finally just did? But it’s ‘cause it’s like-- it is just like a zero to one moment where releasing pre-training data comes with legal risk for any company, but so few people do it, where on my side of the world, it’s like pretty easy to normally say what the best pre-training dataset is, and it had, for a long time, oscillated between like Hugging Face, AI2, DCLM, and there was like literally only two or three options. So in terms of fundamental research, like I think that’s a big step from an org to support the community and take on some risk. So if you have any story you can tell and or just say like, I appreciate it, that’s, that’s all.. that’s all I got.00:15:23 Bryan Catanzaro: Well, yeah. I mean, so I think it’d be great if more people could understand that Nemotron is not just a model, right? Like, what we’re trying to do with Nemotron is to support openly developed AI, because, again, that’s our big opportunity, right? Now, there’s a lot of organizations that are incentivized to build a model, and the model is maybe the thing that runs their business, right?But at NVIDIA, the model is not the thing that runs our business, it’s the systems. So when we’re thinking about how do we support the ecosystem, it’s clear to us that the ecosystem needs more than just a model. There’s a lot of models out there already, you know? And of course, we want Nemotron to be awesome, but you know, if Nemotron can convince other people to work on AI because of a dataset or a technique, you know, we’re, we’re trying to be very open with all of the things we learn, you know, including..I mean, we do a lot of expensive experiments in order to figure out how to do blending for our datasets or to figure out, you know, optimize our settings and, you know, these sorts of things. we’re very happy for other people to pick that up and run with it if it’s useful to them, you know. And so that makes Nemotron a different kind of AI effort. Of course, there is a model component, and that’s a tangible thing, and it’s, it’s easy to focus on that, but we see Nemotron as you know, an effort that includes models, but also includes datasets, techniques, all of all of the research that goes into Nemotron. And again we’re a unique kind of AI organization because of the way that we work with AI companies around the industry and because of the way that our business works, we can afford to be more open with some of these things than maybe some other organizations could be.Now to your question about, like, does it take some courage in order to be open? Yeah, absolutely it does. and you know, I think there’s been-- one of the things that’s happened in twenty-five is that there’s been an evolving understanding within NVIDIA about the benefits of openness, and that has really enabled the company to make some investments that perhaps it was a little gun-shy to make in the past. And so that’s really encouraging for me. it’s something that I’ve you know, advocated for a while, and so it’s, it’s great to see the company kind of lining up behind it. I also, you know, to your point about like twenty-five being a, a year where Nemotron really made some strides, I want to say thank you for noticing that, and then maybe tell you a little bit about how that happened, because I think it’s instructive for me about how I think the work is gonna go forward in the future.So you know, NVIDIA is a very decentralized company with a lot of volunteers. You know, everybody that works at NVIDIA is a volunteer. And what do I mean by that? Well, I mean, look, the industry is moving quick.You know, people can always move from one job to the next. So the way that we think about the work that we do is like, it’s very decentralized, it’s very much let smart people figure out what they should be doing and then kind of self-organize. Now one of the challenges of self-organization in a field that’s moving quickly is that sometimes a whole bunch of people decide to-.. do similar kind of overlapping things but aren’t really coordinated. and that’s okay at the beginning because, you know in a place like NVIDIA, it’s just great to have some energy. It, it took us a while, I think, as a company to figure out that Nemotron was better together.That rather than having, like, this group has a, has a model and that group has a dataset, and like, you know, then we end up publishing papers that kind of you know don’t really acknowledge each other and aren’t really coordinated. And then, of course along with that, we need to have k times the GPUs, where k is the number of independent efforts. we realized that, you know building AI, you really do need to figure out how to collaborate. the AI efforts that are built from teams of people focused on the overall effort succeeding rather than their own particular piece of the project succeeding, those are the ones that, you know, really change the world. And, you know, of course, NVIDIA works that way for the systems that we build, right? So, like, the people working on the memory controller on the GPU know that they also have to work with the people working on the SM that does the math, right?Like, you can’t, you can’t make a GPU where it’s just like, “Well, we’ve got an awesome memory controller,” if the math doesn’t work, right? It all has to, has to kinda work together. And so that coordination, I think in the field of AI, it took us a little bit longer to do maybe than you could imagine that it could have. and I think that slowed the progress for Nemotron. so I give a lot of credit to the Nemotron team for realizing over the past, I don’t know, year and a half or so, that it was really time to join up and build one thing and make it awesome, and deeply understand that the success of the Nemotron project was more important than the success of any individual piece of that project. And the reason why I’m telling you all of this is because I think that’s actually true more broadly than just inside NVIDIA, and I think it’s, it’s difficult. you know, researchers like those of us with PhDs, for example, we are taught how to be independent, you know, and how to, how to build up our Google Scholar profile, and there’s, like, an incentive to go ahead and focus on that.And a lot of successful academics and people researchers you know, they manage to push that pretty far and get some pretty amazing results. But, you know, I do believe that in 2020- in the 2020s you know, that the best research is done as part of a larger team. so how do we figure out how to work together? You know, how do we figure out how to put the success of the team first? That is a thing that is challenging to do but if we can achieve it, I think yield significant results.And, you know, to the extent that we made progress in that part of the organization, I think we also saw progress in the technology. and that’s.. That gives me great hope for 2026 for Nemotron because the way the team is working together, I think is you know, pretty extraordinary. There’s just an enormous number of brilliant people that have decided that they’re gonna volunteer to make Nemotron awesome, and we’re, we’re starting to see some pretty great things come together.00:22:25 Nathan Lambert: I agree with everything you said. Do you have any advice for making the orgs come together? I think we’ve seen big-- Wait, I’ve seen two class-- there’s two classes of AI companies right now. One is startup, does everything, and you have a model in six months, but you’re building from zero, and you have-- you p-- everybody agrees when they start that they do this. And then you have Google’s famous long-winded reorgs, which they actually eventually got right. Like, they got it very right with what’s going on with Gemini and Google DeepMind-.. right now. And it’s like, do you have any advice on doing this? I think, like, I’m, AI too, also advocating for this, but it’s very hard. I think personally-00:22:58 Bryan Catanzaro: It’s-00:22:58 Nathan Lambert: .. it’s like, I mean, I’m, I’m a special case ‘cause I’m also visible, where it’s e-- very easy for me to turn internet activity into, like, reputation points because of algorithms and size. But it’s very hard to do bottom-up technical work and get all of this and get all the culture alignment. So do you have any advice on actually, like, what works in this domain?00:23:20 Bryan Catanzaro: You know what’s worked for us is invitation and not control. so you know, one way that, like, for a while I kinda wanted to try to implement was, like, nobody gets to publish any papers in AI unless they’re clearly part of Nemotron. So this is kind of a top-down, like, we’re gonna make you do it, right? I came to the realization that which we never implemented this, by the way, but I came to realization that this was a bad idea because it would just breed resentment, and, you know, NVIDIA is a company of volunteers. Everybody here is a volunteer.So what we need to do is create the conditions by which it makes sense for people to volunteer to be part of Nemotron. And so the way that we went about doing that first of all it involved like, some top-level agreements between me and some of the other leaders of Nemotron, for example, John Cohen and Kerry Briski. I work very closely with the two of them. And you know, that hadn’t always been the case.Like, we kind of had all come to this place independently. but we realized, like, Nemotron, better together, all three of us, and then we started telling our teams that: “You know, we really think Nemotron is gonna be better together.” so that top-down alignment, I think was really helpful. We-- again, we weren’t telling people exactly what to do, but we were just sending a con constant message like, you know, “Nemotron’s better together.” And then we built some structures that facilitated collaboration. So in the past decisions in the Nemotron project tended to be made in kind of a an opaque way. and the reason for that is just, you know-.. it’s hard to tell everybody about the middle of the sausage-making process. You know, it’s, like, messy and dif- difficult, and so, like, you know, it’s natural.Like, researchers, we’re used to doing this, right? It’s a fait accompli. Like, “Here’s my ICML paper,” and like, you know, the fact that you spent, like, two years failing at that task before you finally succeeded, and then you tied a bow around it and gave it to the ICML committee, you don’t really talk about that, right? And so it’s difficult for researchers to, to be open about the middle of the process of research.There’s a lot of failure, and it’s hard for people to feel like they’re, they’re not looking amazing. But what we, what we decided to do is we structured the project with.. There’s about twenty different areas for the project. Each of them has a clear leader, what we call a pilot in command.Their job is to-- the job of the pilot in command is to land the airplane. You know, you just want the airplane to land, okay? So somebody, if you’re landing an airplane, there might be multiple pilots on board, but only one of them is gonna land the airplane at any time, right? Because it would be chaos if two of them tried to land at the same time, people would die.So so this is not a committee structure; it is a delineated responsibility structure. And then the purpose of that pilot in command for each of these sections is to gather together all the best ideas, help the group of people that are interested in working on that space to come up with data-driven answers to what we should do, what technical decisions we should make, and then document that, you know, in a, in a way that other people can review. and you know, the thing that’s been really great about that is that it is inviting to people because when they see, like, okay, here’s the group of volunteers that are working on this area of Nemotron and then they want to contribute, it’s much clearer about how they could go about doing that, and it’s also clearer what the group needs because you know, these meetings are being held in the open. and we have-- we actually have a website where all of the ideas are submitted. they each get, like, a unique identifier, and then they get engaged with, you know, the PIC is trying to understand what the implications are, what kinds of experiments need to be run in order to prove or disprove the idea? how do we do what I call integration studies? You know, I, integration studies are so key for bringing researchers together, and they’re so opposite of what we are taught when we’re learning how to do ablations as a graduate student. You know, rather than, like, isolating the particular contribution of one idea, integration studies are about putting a hundred ideas together and seeing if they’re better than what we had before. so this kind of thing, doing that in a structured way and in a, in an open way internally has then made it possible for more people to volunteer, and that has then generally raised the rigor of the experiments and also the I think the outcome of the work.00:28:15 Nathan Lambert: Yeah, this is great. I think that over the last few years, there’s been more consensus on things that work for research. And I think the- we also do integration tests very regularly of like, is this feature gonna land for the model? And that’s kind of a..It’s a good- it’s a nice mirror to ablations, where we know research is changing so much. There’s a lot of turmoil in the academic research community, and it’s nice to have things that are tangible as ways that are a little bit different when you’re doing these large-scale projects. So people that underst- like, you still need to do ablations. But then it needs to survive, like, an additional test in order to land into the model.So it’s like an additional type of work that needs to be done, and I just like to have words to describe what is actually happening. I think on the Nemotron-3 Nano front, I do a lot of analysis on just looking at basic adoption metrics and Nemotron we created this, what we called like a relative adoption metric, which is essentially looking at downloads over time for models, because it’s easy to know which models have a ton of downloads that are released a while ago. But to, like, look at the trajectory of downloads changing over time, this is a lot-- this is a mouthful. It’s kind of an aside, but, like, Nemotron Nano 3 was in the thirty B size range, like, on track to be one of the top ten models downloaded of all time.The point that I bring this up, other than to just flatter you, is like, do you think last mile adoption takes a substantial amount of work other than making, like, a very functional model? Or does adoption-- like, do you need to, like, change the recipe that you’re making and put a lot of focus and evaluation and, like, change this over time so that you actually get people to really use the model, rather than, like, “Oh, the benchmarks are good,” look at NVIDIA flying high?00:30:03 Bryan Catanzaro: Right. Yeah, I mean, wow, it has taken the whole company coming together in order to make Nano V3 have more of an impact than the models that we released before. and there’s so many different aspects to that. obviously, there’s a lot of technical aspects which frankly, I think we have more work to do. So, like you know, making sure that on day zero, when we release something, that the quantizations, all the quantizations, the best quantizations are out there, that the speed on all of the important inference frameworks is out there, that it runs on all of the edge devices that we care about fla- flawlessly, that the install experience is great. You know, this kind of work is extraordinarily important because you know, it’s a crowded world.There’s so many different things that people could choose to work with, and any amount of friction that gets in the way of people even evaluating something that you do is gonna blunt the results, no matter how good that technology is.. I don’t think that we’re amazing at this yet, so this is something that I anticipate we’re gonna see a lot more investment in as the, you know more people at NVIDIA from all over the company, from marketing, from developer relations, from software engineering, you know as they-- as we all come together in support of this effort. so yeah, so it does, it does take an enormous amount of work. and then, you know, something that I’m particularly interested in is you know, how do we work engage-- i-in a new way, sort of engage with the community to make future Nemotron models even stronger? You know if the only things that we were to optimize for with a Nemotron model would be kind of academic benchmarks that are, you know, highly cited it’s likely the case that the model wouldn’t be general enough to really be useful. And so what we’re trying to build is a technology that other people can extend and deploy, and that means we need to have, like, other ways of understanding the strength of a model besides you know, a handful of academic benchmarks.I think we have a lot of room to grow here. I’m hoping over time that we develop the muscle of being able to engage with the community and learn from them. Like, you know, okay, this particular thing that I tried to do with Nemotron, it didn’t work. It did this other thing that, you know, I wasn’t expecting, it was wrong. well, that can become feedback that then is used to make the next version better.I think we’ve got a lot of work to do in that regard.00:33:10 Nathan Lambert: Do you think there’s any magic to it? I’ve-- I’m blown away by how successful OpenAI’s two open-source models are. Like, yes, they’re obviously the number one name brand in AI, but on the same metric that I see you guys, like, overperforming, like, what I would expect. I’m like, “Wow, great job, NVIDIA.” They’re, like, totally off the charts, like, on track to like, beat Llama’s, like, most downloaded numbers ever with these two GPT OSS models.And I feel like what they-- like, even on release, they had hiccups where people were pretty negative on it. But for whatever reason, it has just like.. People figured it out, and it just clicked, and then just, like, for a company to say so little about it. Like, we-- Meta put so much effort into Llama being adopted, and you obviously are putting a lot of effort into this.Like, I’m just like, did OpenAI just crack the code, or is there sometimes a bit of luck?00:33:59 Bryan Catanzaro: Well, I don’t think I, I don’t think about OpenAI as a, as a lucky company. I think of them as a visionary company that works incredibly hard and you know, I think their success is well deserved. I love the GPT OSS models. You know definitely they’re an inspiration for us here at Nemotron. and yeah, so I think OpenAI also has, like, some other ways of engaging with the community just because of the large number of people that use their services, and that helps them learn things about what are people trying to do with AI, that then they can address when they’re building models, and you know, obviously, you know, people talk about that as a flywheel. you know, I think that’s really interesting and really important.NVIDIA is never going to have the same kind of flywheel as OpenAI does. We’re not trying to build a service like ChatGPT. What we’re trying to do is help the ecosystem, you know, be strong and enduring. we think that it’s important for there to be this openly developed AI ecosystem, and also we’re, we’re trying to build our next generation of systems, and so we have our own reasons for doing this. But we’re not ever going to have the same exact user base or flywheel that OpenAI does.On the other hand, you know, we are able to work with institutions around the world in our own way, that I think offers us different opportunities and hopefully, that helps us make things that are, that are useful, too.00:35:38 Nathan Lambert: Yeah, this makes me realize, I’m having a lot of conversations on.. There are many open model efforts, especially even among people that are fully open, and it’s like, how do we better coordinate? So especially at the smaller scale, it’s like AI2 and Hugging Face. So they’re not big teams.Like, how do we make sure we’re not doing the same data project at the same-- the same exact thing at the same time? And it’s like, I wonder if there’s opportunities for open companies, like LM Arena has historically released a lot of user data to, like, better help us close this kind of what are people using models for flywheel. And but it’s just-- it’s very hard to build cross-organizational model improvement pipelines, is something that I think. I think models become pretty vertical in terms of somebody at NVIDIA getting the feedback and the model making better.So that’s what would be something I would like to see this year, but I don’t have ideas for doing it well.00:36:28 Bryan Catanzaro: Yeah. You know at NVIDIA, we have a tradition of working really closely with, you know, organizations that use our technology. and, you know, we really-- we have, we have teams of engineers that their job is to enable success for our customers. in fact, there’s more people at NVIDIA that care about the success of people outside of NVIDIA than I feel like sometimes there are people that care about the success of things inside NVIDIA. So, like, sometimes I’m like, I’m like: “Hey, could we use a little bit of that e-energy to support Nemotron?” And, and the answer is yes, and NVIDIA is doing that. But I think as Nemotron matures, we’re gonna find that you know, the organizations that work with NVIDIA to make Nemotron awesome for their business, for their use case are gonna have a say in how Nemotron evolves and hopefully, that helps Nemotron address their needs.00:37:29 Nathan Lambert: .. Yeah, a basic question: how many people, like, how many employees does it take to build all the different versions of Nemotron? I haven’t brought this up because you also have other great types of models. I think our, like, open model analyst, Florian, is obsessed with the Parakeet model, ‘cause- Much faster at typing and is much faster at speaking than typing.So there’s a lot of other-- I don’t know-- I don’t have the full list of other NVIDIA models off the top of my head, but you are releasing a lot of varieties of models. So I think it’s a bit of a there’s more context to my original question, which is I think about language models ‘cause I’m a n-- like, I just think of AI’s progress is gonna continue to go very fast, so I focus as that as the engine. So but it’s like, how many people is putting this kind of movement into place?00:38:16 Bryan Catanzaro: Yeah. Well, it’s, it’s, it’s hard to know exactly, and as I said, NVIDIA is a company of volunteers. But and also these days, things are changing, right? Like, so the Parakeet team, which is an excellent team, by the way they I would say a year ago wouldn’t have really considered themselves so much part of the core Nemotron effort, but these days they absolutely are. for the obvious reason that, you know, LLMs these days need to be able to consume all sorts of data, right?Including audio data. And so you know, as the pro-- as the characteristics, the capabilities of Nemotron models expand obviously, the number of people contributing is gonna expand. I’d say right now there’s about five hundred people that are working pretty much full-time on Nemotron technologies in different ways. This is everything from numerics quantization recipes to speech recognition or image understanding or, you know, pre-training, post-training, RL systems inference software. you know, there’s, there’s a, there’s a whole bunch of different dimensions, right?So I’d say it’s about five hundred people. but also we’re having our Nemotron all-hands meeting this week, and so I took a look to see how many people were invited to that all-hands meeting, and it was about two thousand. so those are people around the company that are interested in working with Nemotron and either expanding its capabilities or helping its adoption. and so I think you know, the number is somewhere in between and it’s hopefully gonna keep growing as, as Nemotron matures.00:40:07 Nathan Lambert: Yeah, I mean, that’s one of the greatest attestations to what you’re saying is like, if the interest outside the company-- inside the company is four times as big as the people doing it, you’re gonna, you’re gonna keep scaling up, it seems. People are gonna-.. find ways to help. - One of the other things I’m interested in, I don’t know, like, on the point of five hundred, it’s like, it sounds like a lot of people, but with how many things you have going on, it seems also very few. ‘Cause I’m transitioning to thinking about the long-standing, like, open-source software that you’ve had for NeMo, and I think Megatron, and it’s like they’ve been around for a long time. I think Megatron has gone through many eras. I have a note here.It’s like these softwares have been going around since, like, twenty nineteen in some form. And it’s, it-00:40:51 Bryan Catanzaro: Publicly. We had our first public release in twenty nineteen, but we started earlier.00:40:56 Nathan Lambert: And it’s something that I’ve found is that when I started doing lang- language models, so I was a late bloomer, and we’ll transition to some career talk in a few minutes at Hugging Face. Like Megatron had, like, a bad rap of being very hard to use. But now, like three years later, I hear from anyone that’s founding a new language modeling startup, they’re like, “Just use Megatron.” like, do you pick up on things like this? Is it just, like, random-00:41:22 Bryan Catanzaro: Well, we-00:41:22 Nathan Lambert: .. but it’s like-00:41:22 Bryan Catanzaro: We hard on it. You know, we’re trying really hard to make Megatron easier to use. It’s difficult. Megatron is a complicated piece of technology, and, you know, when we originally started Megatron, the point was to show the community that you could make state-of-the-art large transformer language models with NVIDIA.I don’t know if you recall, but it-- there was some assertions by some other companies back in twenty seventeen when the transformer was invented, that they could only be made without NVIDIA. in fact, there were statements to that effect on bl-- on official blog posts, which I think got redacted later on. But it was important for NVIDIA to show up and say, “We love language models. We love transformers. Let’s see what we could do, you know, if we partitioned the work properly on lots of GPUs with an amazing interconnect, what kinds of models could we train?” And so that’s where the Megatron project started.You know, I actually came up with the name Megatron. one of my proudest moments, I suppose. I was thinking about it, I was like: This is a really big transformer. What’s the biggest and baddest transformer? Oh, it’s Megatron.So that’s, you know, where the name came from. but you’ll think about that had nothing to do with usability, right? Like, I wasn’t, I wasn’t thinking about, like, how do we make a platform that’s really easy for other people to use? I was just trying to show the world that, like, NVIDIA systems could be awesome for transformers. You know, that was, that was my goal.Over the years, you know, it has evolved. We have a lot more people trying to use Megatron. We got a lot of complaints about how hard it was to use, and then we did a lot of work to try to improve the software engineering around Megatron. You know, these days Megatron software engineering is actually shared between about four different teams at NVIDIA. and we have to coordinate that work very closely.That has also not been easy. There has been times when you know, people wanted to fork Megatron, and then there were times when we, like, had to bring it back together, and it’s like: Look, I know forking things is always tempting, but look, better together. It’s better for all of us to keep working together.. and so I feel like Megatron the-- and especially Megatron Core, which is like a subset of Megatron that’s, like, especially protected, and we try to put more software engineering into that that has gotten dramatically better since we started paying more attention to it as a company. are we done yet? No, there’s a lot, a lot, a lot more work.00:43:52 Nathan Lambert: a ba-- a basic question: Is is Megatron or Megatron Core, like, this is what Nemotron is trained on? And also-- And it’s also something that many of the hottest, like, AI startups are training their models on. I would guess that there’s nothing else that does that. So, like, could you summarize why it’s so hard?00:44:11 Bryan Catanzaro: Well, you know, there’s a, there’s a lot of other great frameworks out there. Megatron’s not the only one. and you know, we’re happy about that. NVIDIA doesn’t need to control the space. What we, what we do wanna do is make sure that we’re putting our products forward in the best light, you know, and it’s a challenging problem.We’ve got so many things going on with precision and you know, the networking. Like, those questions, like, the software is so complicated. these days, you know, we’re pre-training our Nemotron-3 Super and Ultra models using FP4 which is a thing that, you know, hasn’t been done publicly anyway and something that, you know, we’re pretty excited about because our GPUs have really awesome FP4 throughput. But obviously, the numerical challenges of, like, trying to train a state-of-the-art language model using four bits is non-trivial. So, like, you know, all of that work has to go into Megatron, into Transformer Engine which is a, another open-source project that Megatron relies on and, you know coordinating all of that making sure that, you know, we can actually deliver the benefits of NVIDIA systems to people that are trying to make state-of-the-art models, that’s really important to us.And, you know, of the five hundred or so people working on Megatron, like, a pretty good fraction.. or on Nemotron, a pretty good fraction of them are working on these kinds of systems issues, right? Because NVIDIA at its core, is a systems company. and Megatron, you know, Nemotron’s first job really is about systems, you know, and so we, we care, we care deeply about that.00:45:51 Nathan Lambert: Yeah. I mean, from my perspective, I was at Hugging Face before AI2, and Hugging Face is, like, the best company at doing public work. But also, and switching to AI2 and focusing on, like, we’re focused on the output artifact the most. Seeing the different type-- Like, it’s such a different type of work, going from you’re trying to build a tool that’s good for training models, to build a tool that’s good for everybody else and whatever heck use case they are.00:46:13 Bryan Catanzaro: It’s different.00:46:13 Nathan Lambert: So I think-00:46:13 Bryan Catanzaro: Yeah. Different work.00:46:14 Nathan Lambert: To do both is like.. I’m, I’m happy that AI2’s repos aren’t that popular in terms-00:46:21 Bryan Catanzaro: Oh,00:46:21 Nathan Lambert: .. of open-source adoption because, like, we can’t handle it. We just can’t. It’s, like, so hard because it’s people-- it’s, like, it ends up being researchers that are supporting it, and we don’t have the ability to scale the organization structure. So I just think, like, that’s a, that’s a very fun turnaround for me to think of all these things happening at once.00:46:39 Bryan Catanzaro: Yeah. Well, thanks for noticing we’re putting effort in. I would say Megatron is still not nearly as user-friendly as Hugging Face libraries. Like-.. Hugging Face libraries are legendary, and I admire the work they’ve done to make the community so productive. people, you know, are able to get so much research done thanks to the work that, you know, Hugging Face has put into to their library. So you know, my hat’s off to them as well.00:47:06 Nathan Lambert: Yeah. One of my hot takes, you don’t have to reply, is that Hugging Face and NVIDIA have been very good partners.00:47:10 Bryan Catanzaro: Oh, absolutely.00:47:10 Nathan Lambert: And it’s like bringing that Hugging Face culture to the NVIDIA stuff would be so good. It’s just so hard, so I don’t know how that would work, but-00:47:17 Bryan Catanzaro: We’re trying, you know, and you know, it is, it is challenging. NVIDIA is always a company that is gonna prioritize speed like hardware speed, above really anything else, ‘cause that’s, like, who we are. I am always trying to make the case that developer speed is important, too, right? It’s like there’s different ways of thinking about speed. and it is definitely the case that a lot of NVIDIA’s software is so cumbersome to use that you know people can’t get the actual hardware speed as fast as it should be because they just give up.You know, they just don’t, don’t even figure out how to use that. So I think NVIDIA’s making strides there. I think the, the company is understanding more deeply how important developer experience is, and I hope we continue to push that, so that the benefits of all of the systems technology that NVIDIA works so hard on can be more widely used. but at the same time, you know, there is gonna be a tension between those things. It’s, it’s not gonna go away, and you know, to a certain extent, I think that’s just life on planet Earth.00:48:26 Nathan Lambert: It is. I think you’re do- you’re doing a good job, and I’m gonna kind of shift gears in this interview. So I’ve.. In becoming more back in language- in becoming a person that works in language models, I’ve seen your name more and more times.I was like, “Bryan Catanzaro, like, where have I seen this?” And then I went and did the research of the Berkeley PhD in, like.. It says April of 2021, you gave a Berkeley EECS Colloquium titled “Applications of Deep Learning and Graphics, Conversational AI, and Systems Design.” I’m not even gonna posit that I actually went, but that’s definitely where I remembered the name from in grad school. And we both have backgrounds that aren’t traditionally in AI and end up working in language models. I just wanted to, like-- what have you learned from your path th- through NVIDIA into what, like, people should be thinking about with AI or open models today?This could be career reflections, like technical reflections. I just think that there’s-- there are actually a lot of people that come from all over the, like, STEM field to work in AI, so giving it-00:49:29 Bryan Catanzaro: Sure00:49:29 Nathan Lambert: .. space to think about is-00:49:31 Bryan Catanzaro: .. useful, even if it’s just like, it was the big problem, and I wanted to go solve it. Well, I think, you know I’ve, I’ve had a lot of opportunity and a lot of luck in my career. I think in hindsight, it seems like an extraordinarily lucky thing that, you know, I did my first internship at NVIDIA in 2008, and I was, like, building machine learning models on the GPU, and I went to NVIDIA, and nobody else was really doing that. And I was like, “Hey, like, we should have more people doing machine learning on the GPU.I think this could be an opportunity.” And you know, it took a few years for me to make any headway. NVIDIA didn’t really wanna listen to me. I was a brand-new PhD. I was in the research organization, which is very independent, but, you know, sometimes struggles to change the way that the, you know, the bigger company thinks about things.And and yet, I just had this conviction, you know, I just was following my heart about what I think is gonna be important, what do I think could really change the world? And that has been, I think, the thread that has taken me through my whole career, is that I’m constantly trying to refine my beliefs about what matters and then hold to them. And that.. I don’t know how helpful it is to say that, but I feel like sometimes people you know, tend to follow the, whatever the thing is that people are talking about on Twitter.And like I’ve- I’ve done a lot of unpopular things during my career because I believed in them, you know? I remember I published my first paper in 2008 on, at ICML, on training support vector machines on the GPU, and I actually had somebody at the conference, it was in Helsinki at dinner, you know, we were all telling each other what we’re doing, and, and I was like: Yeah, I wanna help people train bigger models on bigger data sets with GPUs. And, and I had you know, a couple of people just say, “Well, why are you here at ICML? That just doesn’t really feel like a good thing for us.” And in 2008, ICML was momly- mainly about new mathematical frameworks for thinking about data, and you know, maybe if you trained a model at all, you would train one on your laptop.You know, that was the state of machine learning in 2008. So for somebody to come in and say, “I think I want to focus on, like, parallel computing, new kinds of hardware for machine learning, programming frameworks for machine learning, so that, you know, we- more people can try inventing new models on complicated machines with a lot more compute throughput on bigger data sets,” that was like a, an unpopular thing. At least it felt very unpopular. I felt very marginalized at the time by the community.But I believed in it, you know? I just felt like, look, technology.. Like I have this sense of, like, where do I think technology is going? I knew that traditional computing was running out of steam.You know, I had, I had done a few internships at Intel, and I was trying to help Intel make processors that ran at, like, ten gigahertz back in 2001, and, you know, it was, like, clear that th- they were running into a wall. And I was thinking: Okay, so if the compute hardware is gonna have to be different, it’s gonna be more restricted. It’s not gonna be able to be so general-purpose in order to get speed. What kinds of applications are gonna have, like, an infinite need for more computing?And I thought, well, machine learning and AI, that could really change the world if it ever actually worked. But, you know, but, you know, back then it, back then, it kinda worked inside of Google. outside of Google, it kind of didn’t work. and so I had kinda these signals, like it was possible, but it was hard. It was a little weird. It was a little niche.I was a little bit caught in between different fields, like the systems people didn’t think I was systems enough, and the machine learning people didn’t think I was machine learning enough. But, but I believed in what I was doing, and I found a way to keep following that belief. And, you know, ultimately it was very rewarding when all of a sudden NVIDIA decided, “Hey deep learning is changing the world. What do we know about deep learning?” And then it was like: Oh, well, Bryan’s been doing that for several years, and he’s written some libraries that we could turn into a product.Let’s go do that. And, you know, so that all happened really quickly after many years of nothing happening, you know? And that was really obviously an amazing opportunity for me. you know, an- another thing that was important to me, I left NVIDIA in 2014 to go work at the Silicon Valley AI Lab at Baidu with a group of really talented people, including Andrew Ng and Dario Amodei and Awni Hannun and Adam Coates, and you know, this was a, a really once-in-a-lifetime opportunity, I think for me, to learn some things that would have been hard for me to learn on my own. you know, I felt at the time at NVIDIA that although I had this great opportunity to help NVIDIA become an AI company, and I was doing that, and I was succeeding at that back in 2013 2014, I also felt like I really wanted to learn from a broader community of people applying machine learning and AI to solve really important business problems. And so going to work at Baidu really gave me that chance. and I was there for a couple of years, learned a ton. very grateful to the team there especially to Andrew Ng, who, who encouraged me to, to join with him on that. and then, you know, I ran into limits of what I could do in California, working for a Chinese company.I was thinking about, you know, what should I do next? And Jensen asked me to come back and build an applied research lab at NVIDIA in 2016. and -.. I wasn’t sure, like, if that was a good idea. I thought NVIDIA’s already grown so much, you know.The, the years from twenty fourteen to twenty sixteen, NVIDIA actually grew a lot. these days you look back at it, and you’re like: It was still really tiny. But, but back then, I was like: I don’t know, maybe NVIDIA’s already tapped out. I don’t know if you recall, in twenty sixteen, there was already, like, ten different companies making GPU competitors, right? The TPU had already been out for a while and you know, it, it wasn’t clear that NVIDIA was gonna become as large as it, as it has.But I believed in the opportunity. I believed in the people. you know, one of the things I loved about NVIDIA was that it’s a very stable organization. So Jensen, he’s been running it since he founded it in nineteen ninety-three. my boss, Jonah Alben, who’s an absolutely extraordinary person has been here for you know quite a, quite a long time, almost since the very beginning of NVIDIA. And these people a lot of the leadership at NVIDIA they love the work.Their heart is in the work. Jensen and Jonah and many other leaders at NVIDIA, they don’t need to be doing this, right? They, they have earned the right to go sit on a beach and drink mai tais all day, but their heart is in the work, and they work incredibly hard. you know, the.. I feel like if there was an Olympics for email, you know Jensen would get the gold medal.You know, like it’s, it’s unfathomable to me, like, how much information he’s able to process. and it’s a skill that he’s built up over a long time running this company, but it’s also a reflection of his commitment to the work. And I felt like working at a place where we’ve got this very stable organization that loves the work, that really wants to change the world. You know, why does, why does Jensen get up in the morning? Well, it’s-- this is his chance to do something meaningful.I thought, associating with these people, you know, I could do worse. I could-- I think I could learn from this as well. And so I came to NVIDIA, and back then it was really hard to explain to people why I was trying to build an AI lab inside of NVIDIA. At, at the time, NVIDIA wasn’t doing very much AI, and so I had to kind of develop a vision for that and then explain it to people. that’s ended up being a really good idea for me as well.You know, the lab, I think, has really helped NVIDIA. you know, Megatron, I think, has really shown the industry, like, how valuable NVIDIA systems can be for language modeling, which is, which is awesome. DLSS, you know I’m continuing to, to push DLSS forward. Very excited about making graphics, you know more efficient with AI. These days, you know, fifteen out of every sixteen pixels a gamer sees are rendered by AI models that, you know, my team developed, and that then makes the GPU ten times more power efficient.This is a really exciting you know, thing for me to be involved with, something that I’ve, you know, dreamed about for years. So, so that’s the kind of thing that continues to push me forward, is that I have strong beliefs about what I think is possible, where I think technology’s going, and I’m willing to do things that are we- weird and unpopular but, you know, basically following my convictions. I’m very much always thinking about the people I’m working with, the tribe. You know, I think tribes matter enormously. like you know if I..So, so back when I was a grad student, I was working on programming models for machine learning. I joined the Python tribe. There are other people that were in the Scala tribe, and the people that did their work in the Scala tribe, trying to make programming models for machine learning in, like, two thousand and ten you know, that work, although a lot of it was technically excellent, didn’t matter to the community as much as the people who were in the Python tribe. It ended up.. and, you know, it kind of sucks sometimes that the world is tribal like this, but it’s just the case.You know, that like the people that you work with, the community that you work with has a big impact on the problems you think about and then the impact that your work has. So I think a lot about the people and the tribes that I’m collaborating with or that I’m part of. and you know, that’s, that’s kind of been the thread that has carried me through my career.00:59:56 Nathan Lambert: Yeah. Than- thanks for sharing this full arc. I think you’ve said things that I tell people but in different languages, and the first one, the early days, it seems like there can be space in between fields, where people-- two fields will have their way of describing things, but both of them are probably incomplete, and there can be space there, which is a lot of what I was doing transitioning from novel robots to model-based RL, where I, like, didn’t sit and bear in the actual AI lab, but I started doing AI with my, like, total electrical engineering friends. And then the second thing is, like, I’d wholeheartedly recommend this to people, is, like, choose your work based on the people and people that sincerely are in it for-.. the, what they want to do, and a lot of-01:00:41 Bryan Catanzaro: And follow your beliefs. You know, think about it. What do you believe in? And it’s okay to change your mind, you know, but, like, figure out what is it that you believe in.Ask yourself every day: Do I still believe in that? If I do, what next? You know. If I don’t, well, what do I believe in?You know, that’s been really important to me. I think too many people end up kind of just following trends. That’s not usually helpful because the trends are too late. So if you wanna, if you wanna change the world, you need to be ahead of the trends, and you need to know, you know, it-- trends-- I don’t think trends in computing are just fashion.I think there’s truth that drives those trends. Not always, but often. You know, it’s just-- this is, it’s there’s kind of an inevitable force of gravity. It just can be really hard to par- parse out the noise and figure out what is the truth that is gonna push the industry forward, and how can you push that with it.You know, if you can join with that, you can accomplish great things.01:01:36 Nathan Lambert: Yeah, I agree. I think in building language models, it’s like you want to build a model that the community wants in six months. I think if you’re building a model to compete-.. with the models that are already out, you’re not gonna keep up. And I think that it’s like, what is the right thing is building open language models in six months, and like, where do you need to try to steer things is one of the hardest problems that I think about. So I don’t-- if you want to close with any predictions where you see, like, open models, like, if we’re-- if you’re gonna be here at the end of twenty-six, if there’s anything you think will be far more obvious than it is today, or any bets that you want to make, I think it’s kind of a good place to wrap.01:02:18 Bryan Catanzaro: Well predictions are always hard, and I don’t feel like I’m very good at making predictions. But I am-- I feel like I am good at identifying what I believe in, and what I believe in right now is that compute remains one of the fundamental challenges behind AI. It has been that way for a very long time and I think it continues to be. I think as we find new ways to apply compute to AI, we discover new forms of scaling laws that help AI become more useful and therefore, it becomes more widespread.So I’m gonna keep thinking about compute. I continue to believe that the fastest-- that, you know, the way to think about AI is not just in terms of absolute intelligence, but rather intelligence per second. You know, there’s some sort of normalization in there that relates to how fast a model can think, how fast a model can be trained or post-trained. You know, that models that kind of incorporate this compute acceleration characteristic, where they’re thinking about intelligence per unit time, those are gonna end up winning because they end up getting trained on more data, they end up getting post-trained with more cycles, they end up with more iterations during thinking when they’re deployed. and you know, of course, if they happen to fit the hardware really well whatever hardware that is then, you know, that can have a pretty non-trivial effect on the intelligence as well.So that’s something that I really believe in. I really believe in AI as an infrastructure. You know, there’s, there’s different ways of thinking about AI. I think some people believe AI is more like the singularity, like once AGI has been declared, then the whole world is different forever, and all humans have lost their jobs and, you know, there’s a lot of like-- there’s a lot of things about AI that people believe that I personally don’t believe.You know, I believe, first of all, that intelligence is very multifaceted that it is not easy to pin down, that as soon as we try to pin down intelligence, we find that there’s very many more forms of intelligence that aren’t covered by that. So, for example, a model that achieves gold medal status on the International Math Olympiad, that’s an extraordinary achievement, but it doesn’t make me have no job, right? Like, I’m actually not solving math problems all day, even though, like, having the ability to solve math problems is clearly very useful. And you know, it’s also the case that intelligence is, you know, is kind of like a potential energy it’s not a kinetic energy, right?In order to transform intelligence into kinetic energy, it needs to have a platform. It needs to be applied in the proper way. and you know, that is why I believe in open models and open- openly developed and deployed intelligence. I believe every company, every organization, has secrets that only they know. They have special data, they have special ways of thinking about their problems, their customers, their solutions, and they’re gonna know how to apply AI better than anyone else.And so AI as infrastructure that transforms companies, turbocharges them, allows them to take the things they know and multiply their impact, that’s something that I believe in more than AI as an event, that one day, when it happens, makes everyone obsolete. I don’t.. I just don’t believe in that. you know, I often joke that, like if, for example, the CEO were to retire at some point, and we needed to find a replacement you know, handing out an IQ test or asking, you know, who has the highest SAT score that would not be a very good way of finding a replacement, you know? intelligence is just far too complex for that. And so you know, so this, these beliefs, you know, you can disagree with me about anything that I just said, and I’m not offended by that.I have a lot of friends that do. but you know, I’m asking myself, well, if I believe that intelligence has these characteristics and that AI is gonna change the world by turbocharging institutions that exist a-and also creating new applications that we haven’t even dreamed of yet rather than replacing all humans, then, you know, how do I go about building that, you know? And so that’s, that’s kind of the direction that I’m on right now.01:07:00 Nathan Lambert: Yeah, I love it. I agree, I agree that we’re entering an interesting area where the open models are taking so many different shapes and sizes and have so many different strengths and trade-offs, that there can start to be interesting interplay as an ecosystem, where there’s just so many different things going on. And I think I like your idea of potential energy, and you have to build things that are kind of unclear of what-- It’s like you have to build the energy in a way, and you don’t really know what the goal is, but you have to do.. try to build these good models. So I appreciate it, and-01:07:30 Bryan Catanzaro: Yeah, and then let people apply it. Let it-- let them make the kinetic energy happen.01:07:35 Nathan Lambert: I agree. Thanks for coming on.01:07:37 Bryan Catanzaro: Thanks so much for inviting me. It’s been a great conversation. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 1h 07m 42s | ||||||
| 1/30/26 |  Thoughts on the job market in the age of LLMs | There’s a pervasive, mutual challenge in the job market today for people working in (or wanting to work in) the cutting edge of AI. On the hiring side, it often feels impossible to close, or even get interest from, the candidates you want. On the individual side, it quite often feels like the opportunity cost of your current job is extremely high — even if on paper the actual work and life you’re living is extremely good — due to the crazy compensation figures.For established tech workers, the hiring process in AI can feel like a bit of a constant fog. For junior employees, it can feel like a bit of a wall.In my role as a bit of a hybrid research lead, individual contributor, and mentor, I spend a lot of time thinking about how to get the right people for me to work with and the right jobs for my mentees.The advice here is shaped by the urgency of the current moment in LLMs. These are hiring practices optimized for a timeline of relevance that may need revisiting every 1-2 years as the core technology changes — which may not be best for long-term investment in people, the industry, or yourself. I’ve written separately about the costs of this pace, and don’t intend to carry this on indefinitely.The most defining feature of hiring in this era is the complexity and pace of progress in language models. This creates two categories. For one, senior employees are much more covetable because they have more context of how to work in and steer complex systems over time. It takes a lot of perspective to understand the right direction for a library when your team can make vastly more progress on incremental features given AI agents. Without vision, the repositories can get locked with too many small additions. With powerful AI tools I expect the impact of senior employees to grow faster than adding junior members to the team could. This view on the importance of key senior talent has been a recent swing, given my experiences and expectations for current and future AI agents, respectively:Every engineer needs to learn how to design systems. Every researcher needs to learn how to run a lab. Agents push the humans up the org chart.On the other side, junior employees have to prove themselves in a different way. The number one defining trait I look for in a junior engineering employee is an almost fanatical obsession with making progress, both in personal understanding and in modeling performance. The only way to learn how the sausage gets made is to do it, and to catch up it takes a lot of hard work in a narrow area to cultivate ownership. With sufficient motivation, a junior employee can scale to impact quickly, but without it, it’s almost replaceable with coding agents (or will be soon). This is very hard work and hard to recruit for. The best advice I have on finding these people is “vibes,” so I am looking for advice on how to find them too!For one, when I brought Florian Brand on to help follow open models for Interconnects, when I first chatted with him he literally said “since ChatGPT came out I’ve been fully obsessed with LLMs.” You don’t need to reinvent the wheel here — if it’s honest, people notice.For junior researchers, there’s much more grace, but that’s due to them working in an education institution first and foremost, instead of the understatedly brutal tech economy. A defining feature that creates success here is an obsession with backing up claims. So a new idea improves models, why? So our evaluation scores are higher, what does this look like in our harness? Speed of iteration follows from executing on this practice. Too many early career researchers try to build breadth of impact (e.g. collecting contributions on many projects) before clearly demonstrating, to themselves and their advisors, depth. The best researchers then bring both clarity of results and velocity in trying new ideas.Working in academia today is therefore likely to be a more nurturing environment for junior talent, but it comes with even greater opportunity costs financially. I’m regularly asked if one should leave a Ph.D. to get an actual job, and my decision criteria is fairly simple. If you’re not looking to become a professor and have an offer to do modeling research at a frontier lab (Gemini, Anthropic, OpenAI is my list) then there’s little reason to stick around and finish your Ph.D.The little reason that keeps people often ends up being personal pride in doing something hard, which I respect. It’s difficult to square these rather direct pieces of career advice with my other recommendations of choosing jobs based on the people, as you’ll spend a ton of your life with them, more than the content of what you’ll be doing. Choosing jobs based on people is one of the best ways to choose your job based on the so-called “vibes.”Working in a frontier lab in product as an alternative to doing a Ph.D. is a path to get absorbed in the corporate machine and not stand out, reducing yourself to the standard tech career ladder. Part of what I feel like works so well for me, and other people at Ai2, is having the winning combination of responsibility, public visibility, and execution in your work. There is something special for career progression that comes from working publicly, especially when the industry is so closed, where people often overestimate your technical abilities and output. Maybe this is just the goodwill that comes from open-source contributions paying you back.If you go to a closed lab, visibility is almost always not possible, so you rely on responsibility and execution. It doesn’t matter if you execute if you’re doing great work on a product or model that no one ever touches. Being in the core group matters.This then all comes back to finding the people hiring pipeline.There are many imperfect signals out there, both positive and negative. For individuals building their portfolio, it’s imperative to avoid negative signals because the competition for hiring is so high. A small but clear negative signal is a junior researcher being a middle author on too many papers. Just say no, it helps you.The positive signals are messier, but still doable. It’s been said that you can tell someone is a genius by reading one Tweet from them, and I agree with this. The written word is still an incredibly effective and underutilized communication form. One excellent blog post can signify real, rare understanding. The opposite holds true for AI slop. One AI slop blog post will kill your application.The other paths I often advise people who reach out asking how to establish a career in AI are open-source code contributions or open research groups (e.g. EluetherAI). I’ve seen many more success cases on the former, in open-source code. Still, it’s remarkably rare, because A) most people don’t have the hardware to add meaningful code to these popular LLM repositories and B) most people don’t stick with it long enough. Getting to the point of making meaningful contributions historically has been very hard.Doing open-source AI contributions could be a bit easier in the age of coding agents, as a lot of the limiting factors today are just bandwidth in implementing long todo lists of features, but standing out amid the sea of AI slop PRs and Issues will be hard. That’ll take class, creativity, humanity, and patience. So, to be able to run some tiny models on a $4000 DGX Spark is an investment, but it’s at least somewhat doable to iterate on meaningful code contributions to things like HuggingFace’s ML libraries (I’ve been writing and sharing a lot about how I’m using the DGX Spark to iterate on our codebases at Ai2).Back to the arc of hiring, the above focused on traits, but the final piece of the puzzle is alignment. The first question to ask is “is this person good?” The second question is, “will this person thrive here?” Every organization has different constraints, but especially in small teams, the second question defines your culture. In a startup, if you grow too fast you definitely lose control of your culture. This isn’t to say that the company won’t have a strong or useful culture, it’s to say you can’t steer it. The culture of an organization is the byproduct of how all the individuals interact. You do not want to roll the dice here.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.Personally, I’m working on building out a few more spots in a core post-training methods team at Ai2. Post-training recipes have gotten very complicated, and we’re working on making them easier to run while doing research on fundamentals such as post-training data mixing and scaling laws. To be a little vague, getting the post-training recipes done for both Olmo 3 and Olmo 2 was... very hard on the team. At the same time, post-training hasn’t gotten much more open, so hiring through it and doing the hard work is the only way.Ideally I would hire one engineer and one researcher, both fairly senior, meaning at least having a Ph.D. or a similar number of years working in technology. Junior engineers with some experience and the aforementioned obsession would definitely work.This callout serves as a good lesson for hiring. It is intentional that people should self-filter for this, no one likes when you way overreach on selling yourself for a job. I also intentionally make people find my email for this as an exercise. The art of cold emailing and approaching people in the correct pipelines is essential to getting hired. Many people you look up to in AI read their emails, the reason you don’t get a response is because you didn’t format your email correctly. The best cold emails show the recipient that they learned from it or obviously benefitted from getting it. Platitudes and compliments are of course nice to receive, but the best cold emails inspire action.Two of the most recent people I helped hire at Ai2 I learned of through these side-door job applications (i.e. not found through the pile of careers page applications). I learned of Finbarr through his blogs and online reputation. Tyler sent me an excellent cold email with high-quality blog posts relating to my obvious, current areas of interest and had meaningful open-source LLM contributions. Both have been excellent teammates (and friends), so I’m always happy to say the system works, it’s just intimidating.All together, I’m very torn on the AI job market. It’s obviously brutal for junior members of our industry, it obviously feels short sighted, it obviously comes with tons of opportunity costs, and so on. At the same time, it’s such a privilege to be able to contribute to such a meaningful, and exciting technology. My grounding for hiring is still going to be a reliance on my instincts and humanity, and not to get too tied down with all the noise. Like most things, it just takes time and effort.Other posts in my “life thoughts” series include the following. I send these to people when they ask me for career advice generally, as I don’t have time to give great individual responses:* Apr 05, 2023: Behind the curtain: what it feels like to work in AI right now* Oct 11, 2023: The AI research job market s**t show (and my experience)* Oct 30, 2024: Why I build open language models* May 14, 2025: My path into AI* Jun 06, 2025: How I Write* Oct 25, 2025: Burning out This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 10m 41s | ||||||
| 1/27/26 | 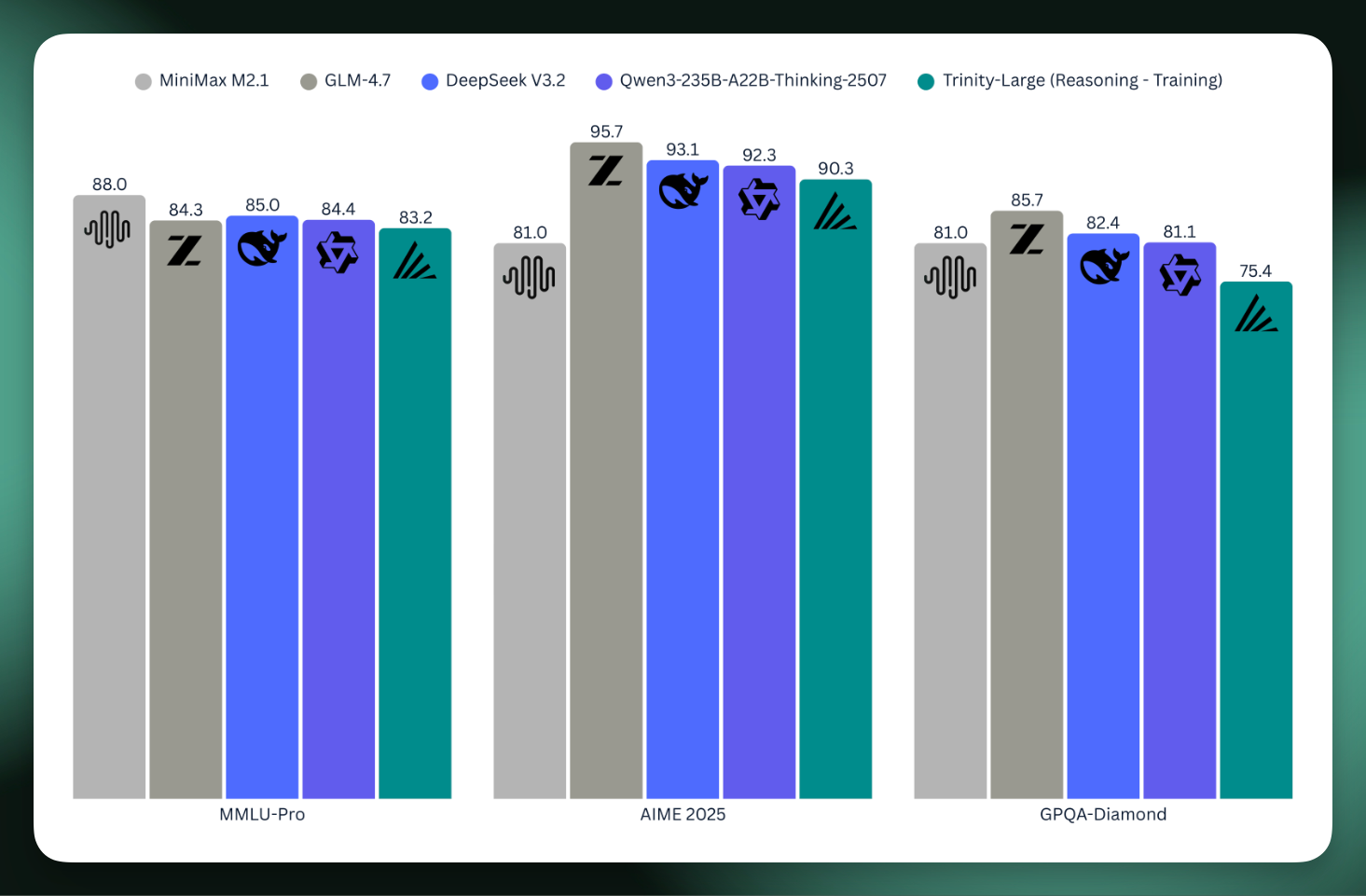 Arcee AI goes all-in on open models built in the U.S. | Arcee AI is a the startup I’ve found to be taking the most real approach to monetizing their open models. With a bunch of experience (and revenue) in the past in post-training open models for specific customer domains, they realized they needed to both prove themselves and fill a niche by pretraining larger, higher performance open models built in the U.S.A. They’re a group of people that are most eagerly answering my call to action for The ATOM Project, and I’ve quickly become friends with them.Today, they’re releasing their flagship model — Trinity Large — as the culmination of this pivot. In anticipation of this release, I sat down with their CEO Mark McQuade, CTO Lucas Atkins, and pretraining lead, Varun Singh, to have a wide ranging conversation on:* The state (and future) of open vs. closed models,* The business of selling open models for on-prem deployments,* The story of Arcee AI & going “all-in” on this training run,* The ATOM project,* Building frontier model training teams in 6 months,* and other great topics. I really loved this one, and think you well too.The blog post linked above and technical report have many great details on training the model that I’m still digging into. One of the great things Arcee has been doing is releasing “true base models,” which don’t contain any SFT data or learning rate annealing. The Trinity Large model, an MoE with 400B total and 13B active tokens trained to 17 trillion tokens is the first publicly shared training run at this scale on B300 Nvidia Blackwell machines. As a preview, they shared the scores for the underway reasoning model relative to the who’s-who of today’s open models. It’s a big step for open models built in the U.S. to scale up like this. I won’t spoil all the details, so you still listen to the podcast, but their section of the blogpost on cost sets the tone well for the podcast, which is a very frank discussion on how and why to build open models:When we started this run, we had never pretrained anything remotely like this before.There was no guarantee this would work. Not the modeling, not the data, not the training itself, not the operational part where you wake up, and a job that costs real money is in a bad state, and you have to decide whether to restart or try to rescue it.All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million. 4 Models got us here in 6 months.That number is big for us. It’s also small compared to what frontier labs spend just to keep the lights on. We don’t have infinite retries.Once I post this, I’m going to dive right into trying the model, and I’m curious what you find too.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.GuestsLucas Atkins —X,LinkedIn — CTO; leads pretraining/architecture, wrote the Trinity Manifesto.Mark McQuade — X, LinkedIn — Founder/CEO; previously at Hugging Face (monetization), Roboflow. Focused on shipping enterprise-grade open-weight models + tooling.Varun Singh — LinkedIn — pretraining lead.Most of this interview is conducted with Lucas, but Mark and Varun make great additions at the right times.LinksCore:* Trinity Large (400B total, 13B active) collection, blog post. Instruct model today, reasoning models soon.* Trinity Mini, 26B total 3B active (base, including releasing pre-anneal checkpoint)* Trinity Nano Preview, 6B total 1B active (base)* Open Source Catalog: https://www.arcee.ai/open-source-catalog* API Docs and Playground (demo)* Socials: GitHub, Hugging Face, X, LinkedIn, YouTubeTrinity Models:* Trinity models page: https://www.arcee.ai/trinity* The Trinity Manifesto (I recommend you read it): https://www.arcee.ai/blog/the-trinity-manifesto* Trinity HF collection — (Trinity Mini & Trinity Nano Preview)Older models:* AFM-4.5B (and base model) — their first open, pretrained in-house model (blog post).* Five open-weights models (blog): three production models previously exclusive to their SaaS platform plus two research models, released as they shifted focus to AFM — Arcee-SuperNova-v1, Virtuoso-Large, Caller, GLM-4-32B-Base-32K, HomunculusOpen source tools:* MergeKit — model merging toolkit (LGPL license return)* DistillKit — knowledge distillation library* EvolKit — synthetic data generation via evolutionary methodsRelated:* Datology case study w/ ArceeChapters* 00:00:00 Intro: Arcee AI, Trinity Models & Trinity Large* 00:08:26 Transitioning a Company to Pre-training* 00:13:00 Technical Decisions: Muon and MoE* 00:18:41 Scaling and MoE Training Pain* 00:23:14 Post-training and RL Strategies* 00:28:09 Team Structure and Data Scaling* 00:31:31 The Trinity Manifesto: US Open Weights* 00:42:31 Specialized Models and Distillation* 00:47:12 Infrastructure and Hosting 400B* 00:50:53 Open Source as a Business Moat* 00:56:31 Predictions: Best Model in 2026* 01:02:29 Lightning Round & ConclusionsTranscriptTranscript generated with ElevenLabs Scribe v2 and cleaned with Claude Code with Opus 4.5.00:00:06 Nathan Lambert: I’m here with the Arcee AI team. I personally have become a bit of a fan of Arcee, ‘cause I think what they’re doing in trying to build a company around building open models is a valiant and very reasonable way to do this, ‘cause nobody really has a good business plan for open models, and you just gotta try to figure it out, and you gotta build better models over time. And like open-source software, building in public, I think, is the best way to do this. So this kind of gives you the wheels to get the, um... You get to hit the ground running on whatever you’re doing. And this week, they’re launching their biggest model to date, which I’m very excited to see more kind of large-scale MoE open models. I think we’ve seen, I don’t know, at least ten of these from different providers from China last year, and it’s obviously a thing that’s gonna be international, and a lot of people building models, and the US kind of, for whatever reason, has fewer people building, um, open models here. And I think that wherever people are building models, they can stand on the quality of the work. But whatever. I’ll stop rambling. I’ve got Lucas, Mark, um, Varun on the, on the phone here. I’ve known some of them, and I consider us friends. We’re gonna kind of talk through this model, talk through building open models in the US, so thanks for hopping on the pod.00:01:16 Mark McQuade: Thanks for having us.00:01:18 Lucas Atkins: Yeah, yeah. Thanks for having us. Excited.00:01:20 Varun Singh: Nice to be here.00:01:20 Nathan Lambert: What- what should people know about this Trinity Large? What’s the actual name of this model? Like, how stoked are you?00:01:29 Lucas Atkins: So to- yeah.00:01:29 Nathan Lambert: Like, are you, like, finally made it?00:01:32 Lucas Atkins: Uh, you know, we’re recording this a little bit before release, so it’s still like, you know, getting everything buttoned up, and inference going at that size is always a challenge, but we’re-- This has been, like, a six-month sprint since we released our first dense model, which is 4.5B, uh, in, in July of last year, 2025. So, um, it’s always been in service of releasing large. I- it’s a 400B, um, thirteen billion active sparse MoE, and, uh, yeah, we’re, we’re super excited. This has just been the entire thing the company’s focused on the last six months, so really nice to have kind of the fruits of that, uh, start to, start to be used by the people that you’re building it for.00:02:16 Nathan Lambert: Yeah, I would say, like, the realistic question: do you think this is landing in the ballpark of the models in the last six months? Like, that has to be what you shop for, is there’s a high bar- ... of open models out there and, like, on what you’re targeting. Do you feel like these hit these, and somebody that’s familiar, or like MiniMax is, like, two thirty total, something less. I, I don’t know what it is. It’s like ten to twenty B active, probably. Um, you have DeepSeeks in the six hundred range, and then you have Kimi at the one trillion range. So this is still, like, actually on the smaller side of some of the big MoEs- ... that people know, which is, like, freaking crazy, especially you said 13B active. It’s, like- ... very high on the sparsity side. So I don’t actually know how you think about comparing it among those. I was realizing that MiniMax is smaller, doing some data analysis. So I think that it’s like, actually, the comparison might be a little bit too forced, where you just have to make something that is good and figure out if people use it.00:03:06 Lucas Atkins: Yeah, I mean, if, if from raw compute, we’re, we’re roughly in the middle of MiniMax and then GLM 4.5, as far as, like, size. Right, GLM’s, like, three eighty, I believe, and, and thirty-four active. Um, so it-- you know, we go a little bit higher on the total, but we, we cut the, uh, the active in half. Um, it was definitely tricky when we decided we wanted to do this. Again, it was July when... It, it was July when we released, uh, the dense model, and then we immediately knew we wanted to kind of go, go for a really big one, and the, the tricky thing with that is knowing that it’s gonna take six months. You, you can’t really be tr-- you can’t be building the model to be competitive when you started designing it, because, you know, that, obviously, a lot happens in this industry in six months. So, um, when we threw out pre-training and, and a lot of our targets were the GLM 4.5 base model, um, because 4.6 and 4.7 have been, you know, post-training on top of that. Um, and, like, in performance-wise, it’s well within where we want it to be. Um, it’s gonna be... Technically, we’re calling it Trinity Large Preview because we just have a whole month of extra RL that we want to do. Um- But-00:04:29 Nathan Lambert: I’ve been, I’ve been there.00:04:31 Lucas Atkins: Yeah, yeah. But i- you know, we’re, we’re in the, um, you know, mid-eighties on AIME 2025, uh, GPQA Diamonds, uh, seventy-five, um, at least with the checkpoint we’re working with right now. We’re still doing more RL on it, but, um, you know, MMLU Pro, uh, eighty-two. So we’re, we’re, we’re happy. We’re really-- Like, for it being our first big run, like, just getting it trained was, was an extreme accomplishment, but then for it to actually be, like, a, a genuinely useful model is a, a cherry on top.00:05:03 Nathan Lambert: Yeah, let’s go big picture. Uh, like, let’s recap. We have all of the... We have this full trinity of models. I think that there’s a fun note. Uh, did I put it in this doc? Yeah, on Nano Preview, which was the smallest- ... you’re, like, charming and unstable. The model card’s really funny. Um, ChatGPT, doing deep research on this, I was like, ChatGPT Pro just tagged next to it, “charming and unstable.” And I was like: Is this a hallucination? And then in the model card, you have, like: “This is a chat-tuned model with a delightful personality and charm we think users will love. Uh, we think- ... it’s pushing the boundaries, eight hundred million, um, active parameter, and as such, may be unstable in certain use cases.” This is at the smallest scale- ... which is like, I appreciate saying it as it is, and that’ll come up multiple times in the conversation. And then you have Mini, which is like, um, I think it was, like, 1B active, 6B total type thing. In my-- I, I don’t have it, the numbers right in front of me. I have it somewhere else. Um-00:05:52 Lucas Atkins: Yeah, Nano was, Nano was the 6B, uh, 1 active.00:05:55 Nathan Lambert: Oh, yeah, yeah.00:05:55 Lucas Atkins: And then, and the Mini was twenty-six, 3B active.00:05:58 Nathan Lambert: Yeah. So, like-00:06:00 Lucas Atkins: Um, yeah.00:06:00 Nathan Lambert: -are these based on more of, like, you need to build out your training chops, or are you trying to fill needs that you’ve-... heard from community, and like, I think for context, previously, your first open model was a base and post-trained model, which was Arcee 4.5B, which was a dense model- -which people like. And prior to that, you had, like, a long list of, like, post-training fine tunes that you had released. So before that, it was like a post-training shop, and I think that kind of history is i- important to fill in, ‘cause I think most people-- a lot of people are gonna meet you for the first time listening to this.00:06:34 Lucas Atkins: Yeah, it, it, um, we chose those sizes for Mini and Nano, uh, specifically Mini, um, the 26B, 3B Active, because we wanted to de-risk, uh, large. Like, th- this has all been in service of getting to a model of, of, you know, the 400B class. So, um, we, you know, learned from doing the original 4.5B, that you might have everything on paper that you need to train a model, but i- inevitably, there’s tremendous, you know, difficulties that come up, and, um, it, it’s-- we, we definitely knew we wanted to make sure that we, you know, solved some of... E- especially when it came to just doing an MoE model performance, uh, you know, like a, like an efficient, fast train of an MoE. So, um, we thought that that was a good ground where we could, you know, it wasn’t crazy expensive, uh, but gave us a lot of data, uh, going into large. And then Nano just came about because we had some extra compute time, and we really want to do more research on, like, smaller models that are very deep. Um, and we hadn’t really seen that in an MoE before, so that one was very much we started training it, and then it, you know, early benchmarks were good, so we said, “Well, we’ll just do the whole dataset.” Um, and, uh, but most of the love for those releases went into, to Mini. So I, I definitely think that long term, uh, from an ROI perspective, the smaller models are going to be where we shine, just because there’s a tremendous amount of, of cost savings a company can get from, from optimizing on a, on a smaller model. Um, but, but we, uh, w- we’re definitely gonna be trying to push the, the large frontier, too.00:08:26 Nathan Lambert: Yeah. Um, I’d like to kind of double-click on training before going back to the small model that’s useful for companies, ‘cause we’re gonna have-- we’re gonna end up talking for, like, twenty minutes plus about open ecosystem. So I kind of am curious, like, philosophically, how your company feels about, like, sharing scientific details. So if I ask you, like, what are the things you’re technically most excited about in the model, or, like, what are the pain points? Like, uh, like, are you willing to talk about these things? Like, I- Do you feel like it’s kind of orthogonal to the company? Like, I feel like a lot of it is just, like, things that happen. I think your framing of all of this is in service of getting the big model going. And particularly, of, like, you have to be thinking about your model as landing in six months, is probably... Like, for people not training models, it’s hard to think about, ‘cause even I- ... like, I’m thinking about trying to refresh our post-training stack for OLMo 3, and I’m like, the thinking model, the, um, we are pretty SFT heavy right now, and it makes it not very dynamic in terms of the thinking time. But it’s just like, I can’t see people deploying this model, or probably will have a hard time fine-tuning it. And it’s like to think about where tool use models are going in six months, like, seems pretty hard. Um, it’s a very hard task to do, so it takes a lot of gumption to actually set out and do it. So I, I would just appreciate the framing, kind of self-reflecting on what I go through. So if you have anything that you think was, like, particularly hard to actually land the six-month outlook, because you use Muon as an optimizer, or is it Muon? And some of these things. I think the data, it’s well known that Datology is cranking a lot of this, and you probably provide-- I think of it as like you’re kind of driving and working with these partners, and I’m sure you provide a lot of feedback on what’s working and what’s not. So- ... anything you’re willing to share, I think it’s useful.00:10:08 Lucas Atkins: Uh, I, I think, um, I mean, on the data side, like Datology, I-- at least for these models, that, that partnership has very much been almost an extension of our own research team. Like, we’ve worked very closely with them, and, um, obviously, our model’s doing well, you know, i- is, is, is good for them. So, um, but it, it-- there was definitely, you know, and you know this better than most, like, small-scale ablations, when you throw them at scale, sometimes, you know, uh, the-- i- it doesn’t always turn out how you want. So there was quite a lot of iterating there to at least get the dataset we used for Large. Um, I, I would say that as far as looking out six months and then figuring out how we wanted to... Obviously, the big one was compute. We don’t, um, you know, we, we never raised as, like, a foundation model company, so we’ve ne- we haven’t signed massive commits for, you know, thousands of GPUs before. Um, we didn’t have a, a, a massive cluster that was always active, uh, for a lot of our post-training. So if they came before, um, you know, we had sixty-four, uh, H100s, that was pretty sufficient for that kind of work, but obviously, this necessitated quite a bit more. Um, but the first thing was-00:11:29 Nathan Lambert: That’s still less than people would guess. Like, you’re releasing models- ... that weren’t like, your models weren’t catching national news, but people in the community knew about them. And, like, uh, i- I think of, like, Moondream when I think about that. Like, vik has- ... such little compute, and he puts it to so use. Like, you, like, see how successful he is? And he tells you that he has, I don’t know, thirty... Like, l- it might be, like, sixty-four GPUs. Like, uh- ... there’s, uh, uh, that’s a whole separate conversation on building- ... actual good ML output on little compute. I, I should ta- I should chat with vik about this, but aside00:12:03 Lucas Atkins: No, it’s, it is-- I think it was... Yeah, it, it, it was very much a gift going into the pre-training side because-... we were kind of already thinking, All right, how do we do the mu- you know, the most with the, the least amount of compute? But, um, you know, we-- it took us quite a while to get the cluster that we have been training large on, which is twenty-two thousand forty-eight B300s. Um, and once we figured out when we were going to get that, get access to that cluster, everything else kind of became clear as far as, like, timelines for Mini and Nano and, and when we wanted to do that. Uh, obviously, you know, five hundred and twelve H100s was easier to come across, um, for Mini and Nano. So once we figured that out, um, it really became, uh, this game of, okay, how can we find, like, the best research on the topic of, of pre-training, and what is kind of... What are the, the, the papers and publications that are coming out, um, that have enough potential and enough precedence, either because, uh, another lab used them, it comes from a reputable team, uh, the ablations and the, the evaluation setup, like in the paper, was sufficient enough to give us confidence. Uh, and then we basically spent, I don’t know, it was probably about two months just figuring out what we wanted our architecture to be for the MoE, then figuring out, okay, now that that’s what we want to do, how do we implement all of that in the actual training pipeline? Uh, how can we-- you know, at that time, there had been many people who’d done Muon, but, um, for post-training, and, and then other-- some Chinese labs had used it, but there wasn’t, like, a widely available distributed Muon, um, to do it that scale.00:13:54 Nathan Lambert: What do you think that, like, looks like in decision-making? ‘Cause that seems like a risky decision, if you ask me. I think for one, the ti-00:14:00 Lucas Atkins: Muon?00:14:00 Nathan Lambert: ... the timing, the, the, like, timing sharing that you’re saying is good. Like, you said this for two months, and then, like... But, like, even Muon is like, that’s a bet that would even take-- like, somewhere like AI2, that would take some serious evidence to go with it. We would want to ablate it. So like- ... on a single track, it’s like y- you had probably had a process for becoming fairly confident in it then.00:14:24 Lucas Atkins: It- yes, but it, it was also, like, Kimi had, had just come out, and we knew that that one used Muon, and so we knew that it, at least, if implemented correctly, could deliver a good model. There weren’t outstanding ablations done around like... You know, there wasn’t a Kimi scale model done with Adam, and then compared to Muon and see the difference. But, um, that at least gave us enough confidence that if-00:14:50 Nathan Lambert: What does Muon give you? Does it give you, like, memory saving, uh, in-00:14:55 Lucas Atkins: No, it’s actually a little bit more memory. It’s, it’s, it’s mostly-00:14:58 Varun Singh: It’s, uh-00:14:58 Lucas Atkins: ... like the loss converges a bit quicker.00:15:00 Varun Singh: It’s, it’s less memory, actually. It’s, uh, uh, only one momentum buffer instead of Adam’s two, uh, beta buffers, and then it’s also better convergence.00:15:10 Nathan Lambert: Okay. So it’s, like, mostly designed around convergence, and then I know the math is different, which is where this momentum term changes.00:15:15 Lucas Atkins: Well, it, it kind of came out... I mean, it had its, its, its big, you know, uh, explosion of popularity in the kind of nanoGPT speedrunning community. So it was kind of all built around converging to a certain, you know, validation loss faster, and, uh, that, that, that was, um... As for why we chose it as opposed to Adam, we’d used Adam for 4.5b, uh, but we also knew that if we wanted to move this fast, that we were going to have to make some pretty big bets, educated. Um, but, but still, we would have to make some, some, some risky decisions, um, beyond just, you know, training in general. So, um, there were a few that Muon we went with, uh, I think was, was one of our bigger bets. Uh, we ended up not doing, like, multi-token prediction or, or, or FP8 because we were throwing so many new things into the run at once, um, that-00:16:12 Nathan Lambert: Do these apply for-00:16:12 Lucas Atkins: ... if something were to go wrong-00:16:13 Nathan Lambert: um, Mini and Nano? Are those also Muon, or are those- ... Adam as well? Okay, so then you- ... you get some de-risk from that. Do you know off the top of your head how many days it take to train each of those? Like, a, a good-00:16:25 Lucas Atkins: Uh-00:16:25 Nathan Lambert: ... ballpark for people, before-00:16:27 Lucas Atkins: Yeah, so-00:16:28 Nathan Lambert: going into the bigger run.00:16:29 Lucas Atkins: So, so Mini, uh, so Nano on it was five hundred and twelve H200s, uh, took a little over thirty days. Um, and then Mini was about forty-five days.00:16:45 Nathan Lambert: Okay. I think another thing- ... off the top of my head is I know that, like, a OLMo 1B dense would take us, like, eleven days on a hundred and twenty-eight H100s for a dense model. So, like, sixteen. So, like, the numbers- ... just go up from there. ‘Cause then it’s like the question is like, I’m guessing i- if those are forty-five days, and then you have-- you up the number of GPUs, it’s gonna be like a similar amount of time, or forty days for the big model, but much more stressful.00:17:16 Lucas Atkins: Yeah, the big model was... But again, that was- we knew that we, we wanted- we felt confident that we could deliver a competitive and exciting model in January 2026. Like, we knew that it would-- we could... Who knows kind of where the research and what, what class and, and, and, and skill and performance of model is gonna come out in the next three months? Um, so we also knew that we really wanted to land sometime in January, and that’s also why we also took- we went with B300s, even though definitely the largest public train of that size on B300s and, and the, um, you know, a lot of the software was not-- did not have, like, out-of-the-box B300 support. It was the only way we were gonna be able to train a model of this size in-00:18:06 Nathan Lambert: Did you have to do this? Did you have to implement the... like, help solve version issues or other issues on B300s? ‘Cause I’ve heard that-00:18:13 Lucas Atkins: W-00:18:14 Nathan Lambert: ... the rollout has been rough.00:18:16 Lucas Atkins: We had to add-... a, a bit. There, there were a couple days where the, the data center had to take it offline to implement some bug fixes. It was, it was definitely, like, a very cool experience being on the bleeding edge, but, um, also, like, a little frightening ‘cause you just know, like, “Oh, we’re not getting the most out of these that we possibly could.” So, um, a little bit of both.00:18:40 Nathan Lambert: Uh, was your final training run stable, or did you have to do interventions through it?00:18:46 Lucas Atkins: Uh, it was very stable, actually. Uh, it took-- the beginning of it was not. The, the, the first ten days were absolute, um... It, it would start very well and, and looked, you know, uh, the dynamics and the logs, and the graphs looked very similar to Mini and Nano, and then after, uh, around a trillion tokens, it- the- we- you know, you’d get collapsing, experts would start to go crazy. Uh, part of this is just, again, we are very sparse compared to what you, you, you have. So, um, you know, four hundred billion total, um, thirteen billion active, two hundred and fifty six experts. Like, it was, it was-00:19:26 Nathan Lambert: Did you do a, uh, expert routing loss or some sort of balancing loss?00:19:30 Lucas Atkins: Yeah. Yeah, yeah. Yeah.00:19:32 Varun Singh: We did, um, we used DeepSeek’s, uh... We, we modified DeepSeek’s Auxiliary-loss-free, um, uh, loss balancing with our own, like, uh, with some tweaks, and then we also added a sequence loss like they, uh, did as well.00:19:47 Nathan Lambert: Uh, was there Auxiliary-loss-free one from DeepSeek V3, or was that a later model?00:19:51 Varun Singh: That was V3.00:19:52 Lucas Atkins: It was V3.00:19:52 Varun Singh: They did a separate paper on it as well. Yeah.00:19:55 Nathan Lambert: Yeah. Yeah, that makes sense. I think a lot of people have derived from there. Um, have you- ... had issues on post-training as well? So I have a theory that the new algorithms we’re getting from the Chinese labs, like GSPO and SysPO, are primarily for problems that you solve when you have big MoEs and you have expert problems when trying to do the RL. And that’s the whole reason that, like, I think our very serious AI two RL setup, like, we’re doing it on dense models, and we’re just like, “It’s fine. We don’t have this big clipping problem, and as much like we don’t have as much of a need to get the batch size as big to ac- activate all the experts.” So you’re saying you have so many experts and so much sparsity, that potentially sounds like you’re making RL harder.00:20:36 Lucas Atkins: Um, yes. I will also... I will say that from just, like, a purely post-training side, we added as much as we po- we used- we... So our code base started from TorchTitan. We’ve had to make a ton of modifications to it to get it where we need it to be, but that was an excellent base. And from one of the bigger learnings from Mini and Nano was treating, uh, at least the SFT side of it, as a s- as a separate phase. Um, ‘cause with, with Mini and Nano, we finished the pre-training, we did context extension, then we took those and then ran those on, like, the sixty-four H100s we usually would do post-training on. Um, that presented a lot of challenges, uh, with the MoEs. They, they really... And that’s kind of been a thing in the open space, is post-training MoEs, like, really, um, can be frustrating, even for SFT. So for Large, we added, uh, like, fine-tuning directly to TorchTitan, um, and did it all on the same cluster. So, um, from a performance standpoint, like, SFT was very, um... actually ended up being totally different.00:21:42 Nathan Lambert: What is the actual difference between the q- the, the implementations then? Is it just kinda like you end up with different batch sizes and parallelism and stuff? Like why-00:21:50 Lucas Atkins: Uh, I mean, we ended up, we... Yeah, we ended up needing to get it to do really, like, to get context parallelism really well, really good, ‘cause we’re obviously going at a higher sequence length, and then, um, just adding the proper loss masking. Um, it, it, it, it ended up being a relatively easy implementation, especially ‘cause we did all the pre-processing, uh, outside of TorchTitan.00:22:13 Nathan Lambert: Interesting.00:22:14 Lucas Atkins: Uh, and then on the RL side, yes, I would say it’s not, um, it didn’t present itself as, as, as significantly harder than, than, um, Mini and Nano. However, that many GPUs does, so we didn’t end up using, uh, two thousand of the B300s for that. That ended up being, uh, a thousand. So two, we just split the nodes in half.00:22:39 Nathan Lambert: Yeah. That makes sense.00:22:40 Varun Singh: On the dense model side of things, uh, you mentioned that you didn’t need to use all the tricks and stuff. I, I think it is, uh... I think the, the, it- MoEs are just, in general, harder to RL, but I think it’s also, like, uh, b- because of, like, the KL mismatch between trainer and inference engine, right? Um, where you have, like, uh, sometimes the inference engine can pick different experts compared to, like, the trainer, uh, when you, like, do a forward pass on the same tokens. So I think there is definitely some, like, inherent instability with, with RL on MoEs.00:23:13 Nathan Lambert: Yeah, that makes sense. Are, are... Okay, um, another question of, like, how much do you want to say? How do you feel about the state of public post-training recipes? Like, do you... Like, I, I feel like there’s so little out there, and there’s an opportunity to be seen as technical leaders by sharing just, like, more of what you’re doing. ‘Cause I feel like we’ve seen for years how complicated things can be, but also at, kind of at the same time... Like, we see this from the likes of Llama, has these really complicated recipes. But at the same time, I feel like just executing on a simpler recipe can get pretty close. But it’s just, like, very uns- I feel, uh, currently unsatisfied with how much I know about what are the actual core trade-offs of doing post-training well. And I think you could do a lot with SFT, but there’s definitely, in this RL regime, more trepidation of kind of narrowing your model to either downstream use or, like, being able to do this multi-week RL run where you get the most performance.00:24:06 Lucas Atkins: Yeah, I mean, I, I, from-- since RL has become such a pivotal part of the process beyond what, you know, DPO and, and, uh, and kind of your, your typical RLHF was in the past, like, we used to get quite, uh-... sophisticated with, with how we would do SFT and, and even our, our RL. We, we obviously, we make MergeKit, so we, we utilized merging, and we used to do a lot of distillation, um, to eke out as much performance as we could. Now that RL is such a massive part of the entire post-training stack, I, I have almost reverted us to just really solid but simple SFT. Um, like in, in large, I mean, we’ve-- our post-training data set for, uh, Trinity Large is, uh, two hundred and thirty billion tokens. Like, like, it just like a really, really, really large-00:25:09 Nathan Lambert: That’s ten X what we did. At least in SFT.00:25:10 Lucas Atkins: And even that-- and even, even your tenant, like that was bef- before this kind of w- going at this scale and even kinda thinking and, and reasoning models. Like our largest SFT before that was five billion to-- we’d do, like, three epochs, but it was like five billion, you know, tokens, so- Um-00:25:28 Nathan Lambert: Our non-reasoning model is, like, te- another ten X. So, like, our most latest instruct model is, like, two billion.00:25:34 Lucas Atkins: Yeah, which is, uh, already a lot, you know. So, um, I, I’ve definitely... We-- you know, simplicity’s key because it also makes debugging anything easier, and then, um, devoting a lot of that sophistication to the RL. Our RL part is, like, really important. I do think that, I mean, the next, uh, phase of reinforcement learning for models of this scale is, is just scale. Is, is... Okay, we went from, you know, twenty billion SFT to two hundred and thirty, now we’re going from, you know, ten environments to a hundred. I think that that really is where you’re gonna get the biggest benefit. I also think that’s why, you know, MiniMax and, and, and other players like GLM are so performant and just, like, have that extra bit of, of usefulness that goes beyond just what you see in the benchmarks, is they’ve, they’ve really embraced, like, long-form, uh, RL. And, and so, um, yeah, I mean, to be quite frank, our, our RL pipeline’s rather... immature might be the wrong word. Like, it’s, it’s, uh, there’s definitely a lot more work we could do and a lot more work we need to do, but, um-00:26:43 Nathan Lambert: Have you started the tool use side of RL?00:26:46 Lucas Atkins: That-00:26:46 Nathan Lambert: Or are you mostly... Well, um, beyond like, if you’re training on code, just verifying the code answer, I don’t count yet as tool use. I would say, like, search and code integrated reasoning is what I think is gonna be like minimum table stakes, but do it- to do it well is really hard. Like, we have to, like- ... like, you, you really, like, uh... That’s what I want to do. I want all of our models to have that this year. Search is prob- you have to have, like, a partner to do search or just, like, illegally scrape Google if you’re gonna- ... you’re gonna serve this model onto a customer, and it’s gonna- ... what? Go, go to Google, like, what?00:27:16 Lucas Atkins: Yeah. Yeah, no, I mean, I, I... Beyond, like, like, really kind of like long-form, like deep research or, um, you know, even like GPT-OSS style or, or G- GPT 5 style, where, you know, it’s doing a hundred tool calls before it gives you a response. Not there yet, um, but that is kind of... Once we get past the, the final kind of RL of Trinity Large, and, and we kinda look at where we go next, like, that is the next major hurdle, um, for sure, and it’s intimidating.00:27:56 Nathan Lambert: How big is your, your team of- of... Like, how many people are spending the majority of their time on the model? And then I think we c- start to wrap up technical talk and zoom out a bit to ecosystem and company strategy.00:28:09 Lucas Atkins: Uh, there’s thirteen at Arcee- ... that are just, like, every, every single day is working on it. Yeah.00:28:16 Nathan Lambert: And I guess that’s a good number because these people are talking about data, but there’s also, like, the whole data thing that’s coming somewhere else. But also somebody else that wanted to pre-train a model, like they could just download the best fully open data set. And I don’t think it’s gonna be quite as good, particularly in the fact that, um, like, if you look at OLMo’s models, we don’t have a lot of tokens, so we need to, like, acquire- ... more tokens in the open still. But to, like, get a number of thirteen, where some are spending a bit of time on data, but there’s the whole data abstraction, is actually kind of nice for somebody that’s like... To do a serious modeling effort, you need to have this many people, I think.00:28:50 Lucas Atkins: It, it was-00:28:51 Nathan Lambert: It’s reasonable to me.00:28:52 Lucas Atkins: It was, it was a good number. I mean, I would say that, um, it, it was helpful to be able to, you know... This was like, how do we alleviate as many concerns as possible? Or how do we check off as many boxes, right? And it’s like, if we’re trying to do this in the shortest possible amount of time, like, we need to focus on what we’re good at, which is we- pretty good at post-training, and how do we get to the point where we’re able to do that? Well, we have to have a pretty strong base model. How do we get a strong base model? We’ll-- we have to, you know, figure out how to do it, perform, you know, efficiently across many, many GPUs, and then data’s, you know, extremely important, so getting a partner that could, you know, help us with that, and we could offload some of that. It, it- there ended up being, obviously, as you, you know, alluded to earlier, like, a lot of, uh, working with Datology and, and, and others to make sure that the data accomplished what we needed it to. Um, I think that that is gonna be an interesting... You know, as we, as we- now that we have Large and we’re looking at, you know, kind of going further, it’s like, okay, you know, the, the pre-training data really has to be in service of what you wanna do in the post-training, uh, work.00:30:10 Nathan Lambert: How did you identify this?00:30:11 Lucas Atkins: Like, like-00:30:11 Nathan Lambert: Like, like- ... did, did you identify this through Mini and Nano, or, like, how’d you come to think that this was so important?00:30:19 Lucas Atkins: Data in general or, or just-00:30:20 Nathan Lambert: Or like this in form of post-training00:30:21 Lucas Atkins: ... of optimizing it for the post-training? Um, I- really ob- observing other, other players, I think. I mean, it’s, it’s... You know, the, the true base model has kinda stopped really being a thing.... around Qwen2, but definitely around Qwen 2.5, um, where you started to see how much post-training data was making its way into the, the, the base models themselves. Um, and then you start to see the models that have done that, how malleable they are with RL, Qwen 2.5, Qwen3 being a good example. And you start to see like, oh, yeah, like they are, uh, doing as much in the last probably thirty percent of training to make it so that when they go to do RL or post-training, they’re gonna have a really good time. Um, you know, they’re just complete-- they’re way easier, way more malleable, way more performant than what you had in Llama 2 or Mistral 7B. So, um, I knew that i-in-intuitively, kind of going into this, but it wasn’t until after Mini and Nano, yeah, where, where we kind of... Well, definitely 4.5B, where we were like, “Yeah, we definitely need to juice our mid-training quite a bit.”00:31:31 Nathan Lambert: Yeah, I agree. Okay, this was fun. We could- we’ll probably revisit themes from this. I think that, um, I can definitely go over time and keep chatting because I’m enjoying this. And for context, Mark and I had coffee at some point when I was at some conference in SF, and I was like: Damn straight, this is a fun bet that you’re making. So I’m trying to recapture as much of this as you can. Um, for context, it’s like in July, which is similar to when you decided to start this model, which is when, like, Qwen Coder came out, Kimi came out, um- ... GLM 4.5 came out, and I was just, like, looking- and Llama had kind of been, like, become a meme of going away. And that’s why I launched the Adam Project, where I was like: Come on, we need to have some people doing this. And I think that it’s, like, hard in the US because I think there’s so much money to be made on AI. Like, the company- the big tech companies are like: “We see it, and we’re gonna take it, so I don’t need to bother with, like, caring about open models ‘cause we don’t need it.” But from, like, an ecosystem co- perspective and a long-term tech perspective, I don’t think that works very well for the country. So it’s kind of this weird middle ground of like, how do you convince people to actually build open models? I was on... Like, I have calls with people in government asking me, like, what would I actually do? So it’s, like, very hard to think about this. And I have this- and then it’s just, like, to hear that you guys are just making this bet on this is very fun to me, but it’s also, like, based on actual learning from trying to do this. So you’ve been trying to train open models. I think Mark and I have both been at Hugging Face in our past, and you’re, you were trying to sell people on using open models, and there is a market for this, but it wasn’t enough to not have the base models. So I think, like, talking about your experience in selling on-prem open models and why you needed to train your own end-to-end, and why you needed to train bigger, is great because I hope there are more stories like this, and it kind of fills a void and inspires people to work in it. So how- however you want to take this prompt.00:33:24 Mark McQuade: Yeah, I can jump in. Um, I mean, yeah, I mean, wh- when I started Arcee in 2023, right, uh, it was... All we did was post-training. Uh, and we worked with, uh, a lot of large organizations and did model customization, you know, for their use case on their data. Um, and we were using Llama-based models, Mistral-based models, and then, you know, some Qwen. I don’t even know if we actually did much Qwen, right, Lukas, at that time, but-00:33:54 Lucas Atkins: No, we did. Yeah, we, we- Later on, but and then-00:33:56 Mark McQuade: Later on, right? Uh-00:33:57 Lucas Atkins: We did, and then we ended up not, because after a lot of Chinese models started to come out, then the companies didn’t wanna use Chinese models, so then we kind of went... Yeah, it was kind of just tricky.00:34:08 Mark McQuade: Yeah, and people don’t realize that that’s real.00:34:10 Nathan Lambert: People don’t realize that that actually happened.00:34:13 Mark McQuade: Yeah, no, that’s, that’s a real thing. That’s why we, we started going down to pre-training was because, well, you know, Meta did their thing and kind of got out of it, right? So there was the, the main US player got out of it, and, and we were working with a lot of US-based enterprises that were not comfortable using Chinese-based architectures. And if you wanted to use the best open models of the day, it started to really trend towards, you know, the Chinese labs. Um, and to the point where we are now, where it’s like, you know, ninety-plus percent of the top mo- open models are coming out of China, um-00:34:47 Nathan Lambert: Yeah, like, Cursor’s building on it and stuff. Like, people are building on these things.00:34:52 Mark McQuade: Yeah. So, um, we said, “Okay, let’s...” Instead of we were so reliant on the Metas of the world, the Mistrals of the world, and Mistral largely stopped open sourcing, uh, you know, fully. So we said: You know what? We’ll just go down the stack, and we feel we’re capable enough to, to, to train our own models from scratch, and then we control the, you know, the stack. We can, you know, we, we control the core of, of... as opposed to relying on others to release great models. And, um, and then during this time, you know, it just happened to be that, um, you know, there wasn’t a tremendous amount of US companies doing it. So, um, from our perspective, it was kind of a, a win-win, in that we were able to own more of the stack by going down to pre-training and creating our own models, as well as we were entering into a, like, a space that there wasn’t a tremendous amount of competition, to be honest. Um, and, you know, I-- Lukas and I had said this yesterday, I, you know, I think as a startup, every startup doesn’t want to directly compete with, you know, X or OpenAI, or Anthropic, or Google because they have more money than God, and they can do whatever they want. Um, but when you’re doing open weights, you don’t-- it’s, it’s a different kind of compe- they, they don’t sit in there, right? You’re kind of going into your own path, where there isn’t a tremendous amount of players, and you can kind of find your, your way and, and build your niche and, and kind of go from there and, and become something big. So, um, it kind of happened to all coincide for us back in, in July, and, and we went all in.00:36:23 Nathan Lambert: Yeah, yeah, like, uh, the, the all-in thing is real because this is expensive. I think that- ... I could dig up in my research the cost of daily, um, twenty-four T8 B300. So I think I’ve seen this type of cost at AI too, where we have long rentals, and we’re like: I know exactly how much this costs, and it’s like, it’s not cheap. Are you... A, a way to transition this is like-... do you see the demand? Like, you were selling open models, like, does this kind of be continuous, where people are like: “You helped us deploy this model, but it’s not good enough.” Like, is, is that something that’s happening, and you’re like: “Well, we have this, and we can help you do it coming in this time?” Or is it like you need to build it... It’s like, is it a we will build it, and they will come type of situation? Like, how much- ... continuity is there in this?00:37:17 Mark McQuade: Yeah, I think it’s largely-00:37:19 Nathan Lambert: I-00:37:19 Mark McQuade: I, uh, from my perspective, I think it’s largely if you build it, they will come. Because we stopped, you know, focusing on that whole revenue generation side of the house when we started to go all in on being this, you know, frontier lab in the open source side. So, um, there’s a couple pieces to that, that, that I think we should all be very proud of inside of Arcee, is that we not only went all in by committing a significant amount of capital. Like, we, we committed, you know, sixty-five, seventy percent of our capital to these models, which is a large amount for a startup. I mean, we didn’t... So that’s not like a dip your toe in, that’s like, we’re all the way in.00:37:55 Nathan Lambert: Yep.00:37:55 Mark McQuade: Um, but we did that at the same time as abandoning essentially the whole revenue angle to go all in on it, because we couldn’t focus on both. So we said, “We know how to make revenue on open models. We’ve been doing it for two years. Now, let’s take a step back, because it wasn’t, uh, in a repeatable or sustainable way that we h- the way we had that business set up. Let’s take a step back, let’s build these models from scratch, let’s come up with the, the Trinity family, then let’s go back to generating the revenue side of the house and the monetization piece,” which I think we are in a good position to capitalize on even more now, but we, we took a... We, we, we kind of walked away from it to do what we’re doing here.00:38:36 Nathan Lambert: Yeah, I love this.00:38:36 Lucas Atkins: Yeah, I mean, when you have... When there’s only, like, thirteen, you know, uh, researchers who would... Well, we’re, we’re doing obviously our own products and own models, but when you’re working with customers, like, inevitably, those are the same people that need to help train those models for customers, and we got to a point where we were really beginning to, like, do mini and nano. We were getting down to, like, the start date of the cluster, where, um, having myself or Mark, or even, you know, Varun and others, like, pulled into customer or, or, or, uh, conversations or contracts, like, it was not-- we would not be where we are if we had continued, you have know, working with, you know, ten customers at once. So-00:39:19 Nathan Lambert: But-00:39:19 Lucas Atkins: ... we, we scaled that down pretty drastically. I do think that when... You know, Mark and I put a lot of thought into, “Okay, well, we’re gonna spend all this money to train these models, like, you know, w- how do we not...” I think, uh, one of the things that makes the idea of, of going all in on training open weight models hard, is that you’ve seen other people try it. And, and like M-00:39:42 Nathan Lambert: Um, like, like do you think Meta or do you think Meta or Mistral went all in?00:39:46 Lucas Atkins: I, I think, well-00:39:48 Nathan Lambert: Meta obviously did.00:39:48 Lucas Atkins: I think they, they both... Yeah. I think, I think that when I say all in, I mean more like Mistral was, was one of the core ones I’m thinking of, where- ... they were a venture-backed company that, like, had a, a, a fiduciary responsibility to bring in money, but were also trying to release open weight models, uh, for, you know, the West, and for their communities, and for the world. And, um, they tried doing closed versions, and then monetizing off of that. They, they also kind of have more recently, luckily, for all of us, gotten back to their kind of Apache 2.0 roots, and-00:40:30 Nathan Lambert: Oh, my God.00:40:30 Lucas Atkins: And-00:40:30 Nathan Lambert: Have you seen the download numbers on Mistral 3 Large?00:40:33 Lucas Atkins: I haven’t. No, what is it?00:40:35 Nathan Lambert: Oh, s- no bueno, sir.00:40:38 Lucas Atkins: Hey.00:40:39 Nathan Lambert: Carrying on. Sorry.00:40:41 Lucas Atkins: But, I mean, yeah, you know-00:40:42 Nathan Lambert: Um, Mist- the, the Large Instruct model has downloads in the last month. I honestly don’t know what’s going on. Maybe there’s some, like, quantized version out there. I, I was confused.00:40:50 Lucas Atkins: Maybe. Well, I mean, yeah. But I think that we-00:40:52 Nathan Lambert: It’s, it’s hard to get adoption. The competition is insane.00:40:55 Lucas Atkins: Hmm. Well, that’s, that’s- ... yeah, I mean, and that could be a whole conversation also, is, like, how do you actually get people to use it?00:41:00 Nathan Lambert: I was gonna ask you, like, how do you get people... How do you get people to- - really sell into this? You said you’re good at it.00:41:06 Lucas Atkins: Yeah, I think that the-00:41:08 Nathan Lambert: Continue your point, we can come back to it.00:41:11 Lucas Atkins: No, no, but they... I think they all kind of tie into it, is, is... We knew that the, the market was there for, for custom models. It was two years ago, frankly, and it’s even more so now, because RL has drastically, uh, increased the areas that you can hill climb and become really powerful with a tiny model. Um, and but, but also, people are beginning to see how powerful, you know, uh, te- uh, cust- or, or training in a, a, a product is. Like, you see Claude Code, you see Codex, you see, um... I think Deep Research was kind of one of the first ones that really kind of opened my eyes to what was possible, when you kind of are kind of training in the same environment that you’re serving your users. So we knew that, that people wanted it. We’d, we’d had good success with, with customers in the past using other people’s open models. So, um, it was less of a question of, like, could we monetize it, or will we? And it was just a matter of, um, could we get a model, you know, that pe- that, that we would feel that, you know, given a, a wide suite of basically being able to pick any model in the world, would, would our researchers and, and would our teams re- reach towards our own? And, uh, luckily, I think we’re there. Um, on, on the-00:42:31 Nathan Lambert: Uh00:42:31 Lucas Atkins: ... on the topic of, like, how do you get people to use it? How do you get adoption? You know, I’ve never wanted Trinity, uh, or our biggest advertising thing to be, like, US. You know-00:42:45 Nathan Lambert: Yeah, I know00:42:45 Lucas Atkins: ... like, if, if your entire-00:42:47 Nathan Lambert: I know, man, it hurts me.00:42:48 Lucas Atkins: Yeah, if your-00:42:48 Nathan Lambert: I spent months reckoning with this.00:42:50 Lucas Atkins: Yeah. If, if your entire, uh, you know, value prop is that you’re an American company-... great, but ultimately people are gonna use the best. Um, and so I think that we’re gonna be able to serve and, and the people like that need a US-based model because their compliance or legal teams won’t let them use something out of China, it’s gonna be a fantastic option. But I think, you know, kind of the next phase of what we’re doing as a company is, all right, now we’ve, we’ve proved to ourselves and maybe the, the wider industry that like we deserve to be in the conversation, and we can train models of this scale. Um, then it’s like, okay, how do we train the best one? Uh, ‘cause really, I mean, people’s loyalties are very fickle, and, and, yeah, you, you go to what’s the best. I guess it’s like, how much do you think00:43:41 Nathan Lambert: you’ve learned about being able to tune a model narrowly by going and building the whole stack? Um, something we talk about is like ability- ... to specialize models, and I kind of, of opinion that you just make a better general model right now ‘cause the pace of progress is so high. And but the question is like, can we tune a OLMO that’s very good at science or something? And I- ... w-would guess that training the entire model, you’re going to be able to actually do a better job at what you were doing, but I don’t know how to articulate why or what that looks like.00:44:18 Lucas Atkins: Um, I mean, the, the, the simplest answer to that being yes is just that... or the simplest reason why that’s the answer to the question is yes, is because we know what went into the model. Like, we know what it actually saw at the later stages of training during the decay. Um, and so that all- that helps influence, A, what are we tr- what kind of data and what topics and, and what format are we giving these models, uh, in post-training? But it also allows you to know like, okay, where, where do I absolutely wanna crank, you know, how, how many- how much of this, say, 230 billion dataset, do we want it to be math or, or, or, or coding? And a lot of that’s influenced by what you’re able to put in-00:45:06 Nathan Lambert: How, how much of your post-training-00:45:07 Lucas Atkins: ... post-training00:45:07 Nathan Lambert: -do you expect to redo? Like, uh, how much can you say about when you’re serving something on-prem? Um, you- you’re not gonna redo the pre-training. You might, for a very big customer, redo mid-training or do continued pre-training- ... in which, in that case, you do need the pre-training data to keep, keep it being stable. Which is a use case where like I’m- I would love to see a paper that’s like, “Because of OLMO being open, we continued to pre-train on biology, and we mixed half of their exact mid-training dataset in with our dataset, and it, and it worked,” yadi, yadi. Like, you could obviously- ... do that, but how much do you think is gonna be like the standard, you fine-tune the last instruct model, or do- are you gonna have to retouch the post-training for a customer? Because that, like, I, I really feel like-00:45:48 Lucas Atkins: Um00:45:48 Nathan Lambert: ... it’s just at the end.00:45:50 Lucas Atkins: It, I think, I think-00:45:50 Nathan Lambert: But it would be fun if you had to change it.00:45:52 Lucas Atkins: For the most part, um, I think a lot of tasks will be fine just starting from our, our, our, po- uh, like the released, you know, official post-trained version. Um, now, that’s for maybe simpler tasks, is the wrong way to frame it, but if it’s like, “Oh, hey, we’re doing a deep search agent. We want it to do 30 calls and, before...” That would be a good use for just starting with the finished model that we released that’s already post-trained. Now, if we’re going into something along the lines of, um, a very low-resource programming language or, um, something that it didn’t see a lot of in, in, in pre-training, um, or it’s kind of like a, you know, we’re wanting to train this thing to be really good at humanities last exam, but tools. Um, once we get into the world where we’re having to, especially... Actually, I have a much better answer to this question as I was thinking through it, but most of that holds the same. I think that the, the, the world where we’re gonna be doing a lot of extra instruct and, and SFT and, and post-training is gonna be when we’re trying to distill capabilities from large, like into mini or nano. So say like, oh, you know, this large is, is, is really great at invoice processing, but it’s also 400b, and the, you know, the company doesn’t wanna be hosting that on-prem, you know-00:47:24 Nathan Lambert: Ah00:47:24 Lucas Atkins: ... let’s go out generate a new one.00:47:25 Nathan Lambert: Do you have costs off the top of your head for, like, what the hosting costs are for each of the model? Like, do people... Are people all gonna host these models in the same way, or is there actually-00:47:32 Lucas Atkins: Uh00:47:32 Nathan Lambert: ... a wide variance? And if you have, like, the same three models- ... do almost all of your customers end up hosting the same way, or do you end up doing a lot of, like, how do you configure the model to fit in the right hosting for them? Like, is that part of-00:47:44 Lucas Atkins: It depends00:47:44 Nathan Lambert: ... the business model?00:47:45 Lucas Atkins: It, it, it, it kind of... And we tried to move a, a, a little bit further away from that because you get into the risk of being like, like a consultancy, and it’s- that becomes tricky, where there’s not a very clear separation of concern. But, um, for the mo- it would change depending on, were they using AWS? Did they have a commit with Azure? Um, if not, okay, then we, we can go to, you know, someone like Prime Intellect or Parasail and, and get a, you know, maybe a, a cheaper rack of eight. Uh, it just really depended. Uh, there’s quite a bit, um, of, of people that were also serving them, just using, like, Llama CPP. So, like, on CPU-00:48:25 Nathan Lambert: Uh, is the 400b designed to be, to fit onto one rack of eight 80 big gigabytes in FP8? Is that how you designed it? ‘Cause Llama- ... Llama four, whatever, Llama 405b was the same. It was like one rack in FP8 works pretty well.00:48:41 Lucas Atkins: It’ll do- we... well, you’ll be able to get really good throughput, a little bit lower concurrency on a, a rack of eight H100s at FP8, and then for, like, our, you know, what we’re serving, we’re serving them on, uh, a series of H200s, but we’re not doing, like, multi-node inference. Uh, but that’s just to add more, you know, replicas and- ... other kinds of things.00:49:03 Nathan Lambert: Hopefully, eventually. I think that the-... Do you have anything else to say about selling open models? I think that generally, like, how do you think about the market for AI? ‘Cause I see the market as being so big, but the- with specifically with open models, it’s so hard to measure. I think I’ve started talking to some of the Chinese labs at all- as well, and I like to ask them, like, this is very US-centric and like Fortune 500 or whatever, and it’s just like, who the heck uses these models? I think- I guess another question is, like, what license or do you know the licenses you’re gonna use for the biggest models? And I think they’re, like, you’re, you’re playing with fire ‘cause people can use it for free, obviously, but potentially- ... you’ll get to hear like, “Oh, s**t, somebody actually used our model for this.” And I think any successful business, you’re gonna want... You, you, you know that this model is not gonna be very relevant in a year with the pace of progress. So like- ... how do you think about your license decisions?00:49:55 Lucas Atkins: Uh, we- you know, with the 4.5B, we tried to do like a, like a, a reve- one of those revenue-gated licensing. So it’s like, oh, it’s completely free for you to use for commercial and whatnot, but if you or your company made over, I think it was like $1.7 million last year, then you need to come to us and get a license. And what we ultimately found was like, it, it didn’t... Maybe for some people who are just only trying to train the model, release it on Hugging Face, and then just call it a day, maybe that is a huge requirement. But when so much of our, our, our company is built around, you know, training custom versions of the models, and, and not even just ours, but in general, even before we did pre-training. Like, at the end of the day, i- as long as we were using it, a- and we knew that we were in full control of, of whether- if we really succeed, it’s because we trained the models, we did them well, and we executed on it well. If we fail, it’s because we, uh, didn’t execute, instead of, oh, some company just stopped releasing good open models. Um, so we eventually switched to just Apache 2.0, and Trinity Large is also gonna be Apache 2.0. Um, you know, I’m- I think it is-00:51:23 Nathan Lambert: I think this is the right approach. I have a big investor-00:51:25 Lucas Atkins: Yeah, I think it-00:51:25 Nathan Lambert: Without, without naming other companies, it’s easy- like, raising a lot of money, whe- or being Meta and releasing open models, and do it- and you could release it with non-commercial, and you could get all these, like... You could talk to, I don’t know, f*****g Adobe, whoever. Oh, Adobe’s too big. They’ll have good AI. Some... I don’t know, a bank. Bank of America. You could run Llama on Bank of America and make good money on this. But I just feel like the cultural home of open source AI, and I don’t think- it’s impossible to know who wins it, and I don’t think that you’re in the prime position, and I don’t think that it’s easy to win, but you’re doing a thing that aligns with it. It’s the person that just, like, commits to building the models and learning how the ecosystem works, and to rebuild the models based on the feedback th- that you get from people, and to just kind of commit to an evolving process. And if the whole thing works out, there will be a lot of value, and the person who understands it best should be able to learn how to extract said value. And I think that I’m personally, like, sometimes frustrated with Hugging Face, ‘cause I feel like they have sat on that s- a sort of position like this, and they- ... haven’t figured it out. Not that it is easy to figure it out, but I think that has to be the ideal of open source AI, of like, if it’s really gonna work, that’s, that’s what I hope it looks like. And it’s like, I, I don’皮 know, maybe you guys could do some of that. Like, I have a question of like, could you figure out how to make models that are more fine-tunable- ... after all this post-training? Because you need to sell it to a- you need- ... you, you know the customer’s not gonna want it off the shelf. And I don’t know how to train to post-training to make sure that you don’t, you don’t cook it. Maybe you just learn that you need to warm up the model in a l- in the right way, and you just learn the technique of training downstream. But when you talk to people doing research, the different base models have such different characteristics. I think one of them is character training. I did this paper, and the guy was like: “Qwen and OLMo love their character,” and I’m like, “I have no idea why.” And but it’s like Llama and Gemma, you can change them so much. And I’m like, “Dog, like, please figure out why this is the case.” And for one thing, it’s really cool, but also, like, in your case, that would unlock a lot of value to be like, we know exactly what the model’s gonna do, and we know exactly how to change it. So.00:53:35 Lucas Atkins: Yeah-00:53:36 Nathan Lambert: Uh00:53:36 Lucas Atkins: ... it, it, that’s- no, you’re, you’re, you’re right on the money. I think that even, uh, going into the post-training at large, we, uh, one of our researchers came out with, like, a pretty cool, um, experiment and ablation run that they did on drastically reducing catastrophic forgetting. And I almo- I mean, this was, like, three days before we were gonna start doing SFT, and then we ultimately just... I, I ended up pausing on it because it was just throwing something in that wasn’t tested. But, um, yeah, I think-00:54:08 Nathan Lambert: A good research lead. You did the right thing.00:54:10 Lucas Atkins: Yeah, I think, I think one of the most important things long term, you know, as we look at kind of what our research priorities are for this year is, is there’s obviously just how to scale RL and, and make these- the end result of the model as good in as many situations as possible. Um, but I think the other half of that is, you know, how do we make the, the, the speed and efficiency and, and performance of customizing them as, as fast as possible, and as easy as possible.00:54:42 Nathan Lambert: Yeah. Do you learn in making open models from your experience just kind of running these open software things in MergeKit and DistillKit? I know there was a whole license journey on one of those as well.00:54:52 Lucas Atkins: Yeah, DistillKit.00:54:52 Nathan Lambert: Do you feel like they’re kind of isolated?00:54:54 Lucas Atkins: Or MergeKit. Um, yeah, I mean, I think so. I think that, that, um, you kind of have to play the tape out. With MergeKit-... it was by far our most popular piece of software we’d ever released, but it was so popular because it took something that isn’t fundamentally very complicated, but we ma- but it’s time-consuming, and standardization is great for things like that, and we made it, uh, you know, streamlined and easy to do and fast, and you could experiment and ablate really quickly for, you know. And, and so I, I think that when we switched that to, like, a, you know, a, a similar, uh, revenue-based licensing, like, it, it didn’t end up having the value prop that was important because are you gonna pay Arcee, you know, thousands of dollars, or are you just gonna have one of your researchers-00:55:52 Nathan Lambert: You’re gonna have clone code in a week, right?00:55:52 Lucas Atkins: recreate it in a week, right? Yeah, so it’s-00:55:55 Nathan Lambert: In a day.00:55:55 Lucas Atkins: It’s, it’s kind of... It, it’s remi- it’s remembering like, okay, what is- what problem is this solving, and is this even a prob... Like, is the solution to this monetizable? Um, and so MergeGit, we brought it back to the original license, but I think with even viewing the models in the same way, it’s like it’s... Open source is an unbelievable marketing tactic. Like, there’s no one would care about Arcee if we weren’t open sourcing stuff, ‘cause as soon as you do something closed source, if you’re not the best or the cheapest for your price point, I mean, your performance point, no one’s gonna use it. Because-00:56:30 Nathan Lambert: Um, another question on this. Um, do you think that open models are kind of at a disadvantage when progress is so high? Because it’s potentially easier to swap APIs than open model configurations, especially if, like, model weights are changing sizes or something like this. Where it’s like, “Oh, I can just upgrade to the new Opus, and I do this.” Like, does that, like, uh, decentivize people from using it? Or do you think most of the people are like: “I can only use open models, therefore, I’m gonna use open models?”00:56:56 Lucas Atkins: Uh, I think for the people who are using, like, s- either self-hosted or, you know, um, uh, bespoke, uh, you know, engines to, to run it, where they have complete... You know, in a VPC or they have complete control over, like, data in and out, egress, ingress. I don’t think that’s really gonna be so much of a problem because they’re obviously doing it for a reason. Um, like, they’re either for privacy or security or, or HIPAA or SOC 2. For whatever reason they’re doing it, um, I, I don’t think that that’ll be, um, so much of a blocker, but I definitely do think that, um, you know, by far, e- even, even with some of the, the larger open... You know, like inference players, like Together and Fireworks, that, that host a lot of open models. Like, being feature- being on feature parity with a lot of these, these larger labs’ APIs is gonna be extremely important, um, o- of being able to serve, you know, um, with features that they’re used to, like prompt caching, that kind of stuff.00:58:03 Nathan Lambert: Yeah, are- like, I, I think I saw that you guys are setting up an API as well. Is that kind of what the vision there is, is being able to o- offer parity at least, or, like, make it easy for people to consider it?00:58:13 Lucas Atkins: I think so. I, I- we’re- we very... Yeah, we are doing our own API. We are hosting it. Um, we haven’t- we, we push a lot of that through Open Router just because it’s such a great place to get, like, discovered. Um, as... If we see, like, tremendous growth there, that would obviously be where we’ll, we’ll invest very heavily. Um, whereas the right move might be to let other people host it, and we invest super hard on the infra for, like, make- taking advantage of the models, um, and, and customizing them. There’s, there’s, there’s a few avenues we have ahead of us then, and we have, you know, projects going kind of toward to poke at each one. Um, and we’re just kinda getting as much data as we can before we... I mean, we’re gonna have to go all in on another direction soon. Not, not like pivoting away from pre-training, but now that we’ve done that, now w- what’s the next big bet we’re gonna make, and how do we go fully into that? So we’re trying to figure out what that is.00:59:12 Nathan Lambert: Yeah. My two last kind of, like, real questions are, like, one is... I guess I can start with, like, where do you see the open model ecosystem? Do you think- where would you see it changing substantially in the next six or twelve months? I, like... Or, or do you? Or you just kinda think we’re marching along for a while?00:59:31 Lucas Atkins: No, I think we’ll, I think we’ll, we’ll be... I, I, I don’t think it’s an unrealistic prediction to make that by the end of 2026, like, the best model in the world is, is some degree of open. Uh, I think that’s very, very possible, especially with, like, what I’ve seen GLM and, and MiniMax do recently. Um, they have started to find that secret sauce that takes you out of just being good on benchmarks and, like, genuinely useful in people’s day-to-day workflows. And, um, I wouldn’t- like, if, if I, you know, came back, and I... Someone came from the future and told me that the best model in the world was, uh, an open-weight model, I wouldn’t be surprised. I actually think we’re on a, a, a super good trajectory, and, and, and fostering and, and promoting that kind of work and adoption here in the United States is gonna be extremely important.01:00:24 Nathan Lambert: And where do you see the company going? ‘Cause like, like, I have my guess. Like, you kind of hopefully-01:00:31 Mark McQuade: What’s, what’s your guess? I wanna hear your guess.01:00:31 Nathan Lambert: Um, you can hopefully do a mix and kind of oscillate into trading when you get... Like, you need to start having the feedback of the real world. I think that’s obvious. Like, it’s o- like, it’s... Well, obviously, you need to make money to survive as a company, but then you need to start using that as the feedback to guide training. And then it’s like, you need to figure out how to balance and do some of them at each time, and you can plan your cluster at different times, and then you kind of... Hopefully, they become a, a loop across each other, and they kind of make it so obvious of why you each need them, ‘cause it, it seems somewhat natural.01:01:03 Mark McQuade: Yeah, I mean, exactly. You know, you kinda hit, hit it right on the head. Um, you know, getting feedback and then kinda steering the ship from there, um, is, is probably-01:01:15 Lucas Atkins: ... exactly what we’ll do, but we have a good idea already. I mean, first and foremost, you know, we talked about it earlier, w- we’ve spent a tremendous amount of money. So, uh, we need to go raise some money after we - after we get, you know... We need people to back the, the, the mission and the vision of US open source and, and, you know, so, um, because, uh, you know, we, i- i- Lucas had mentioned about, like, MergeKit and how we flopped the license and, you know. I mean, we’re a smaller-sized start-up. We have-- we’re-- we gotta think of kinda unique ways to try and generate revenue because we don’t have the money of the large labs. So, uh-01:01:52 Nathan Lambert: Well, I think it’s a benefit to the employee. I think a lot of these labs have over-raised.01:01:56 Lucas Atkins: Yeah, I like, uh- uh, I-01:01:57 Nathan Lambert: OpenAI, Anthropic, and all of them are fine. Like, with the OpenAI, Anthropic, Cursor scale, like, let it rip. They should, they should really rip the raising. But all the other companies that are stuck at the, like, the one to two billion range without, like, obvious traction, like, the risk goes to the... I mean, you could-- a lot of them do secondary, so a lot of the founders get out. But it’s like, the risk is the employees get nothing.01:02:21 Lucas Atkins: Yeah. Yeah.01:02:22 Nathan Lambert: There is a lot of money, but that’s also why I like the approach, ‘cause it’s like, “Oh, you’re doing the actual start-up thing.”01:02:28 Lucas Atkins: Yeah, yeah. Yeah, I mean, I think... W- what I was gonna add to what Mark... is just like, what- whatever we do from, uh, uh, uh, scaling and, and speeding things up and growing, um, my goal is to keep our research and engineering teams pretty small. I think, I think that one of the reasons we’ve been able to, to move as quickly as we have is it’s been, like, a small group of, like, highly intelligent, smart, and opinionated people sitting in a room, debating in good faith on decisions. And I think that that’s, uh, uh, under the constraints of, “Hey, we don’t have five hundred million dollars to go and, you know, to rip on, on, you know, X, Y, and Z.” So and I think that’s kind of where creativity comes from, and I think that fostering a culture like that over time is how you can kind of make it so that excellence is less of like a, um, an accident, and it’s actually, like, a by-product of the way that you work. So, so we’re gonna stay small, we’re gonna stay lean, but, um, I, I do think that, like, the, the major, um, kind of challenge for us over the next probably six months, beyond any other models we might have, kind of, uh, think or we’re thinking about, is, is getting up to, like, post-training parity with the likes of DeepSeek, and GLM, Qwen, and others.01:03:47 Nathan Lambert: Yeah. I, I hear lots of horror stories about this, where it’s usually and-- it’s-- you end up having people that are going after different important abilities, but, uh, like, doing each of the abilities alone is pretty easy to hill climb, but then you just end up with such a mess. It’s like you’re- ... building a custom puzzle, and you’re building all these custom pieces, and they’re magnificent, and then you’d have to, like, pick up these pieces and assemble this unknown thing at the end. And it’s like-01:04:12 Lucas Atkins: Like they didn’t have the same designer, right? Yeah.01:04:15 Nathan Lambert: As AI2 is barely scratching the surface of this. Like, you talk to the people at the frontier labs, and it’s like, holy cow, like, post-training is really the Wild West. But a lot of it works. I think, like, we find-- like, even like model merging gives a ton of performance across the whole- ... training pipeline. It’s like- ... you merge at pre-- you merge after each pre-training stage, you merge in post-training. It’s like-01:04:35 Lucas Atkins: Roon can tell you.01:04:36 Nathan Lambert: But merging post-training becomes a lot more complicated because you- ... can have all these domains and things, uh.01:04:41 Lucas Atkins: Well, in, in merging, you know, it, it actually, it used to be very YOLO, um, the way we used to do it, and, and Charles, who, who created MergeKit, I call him, like, chief alchemist, and, like, you’d kinda just send him ten promising checkpoints, and he’d come back a day later with, like, some insane, you know, model that was really good at all of them. And, and you can’t do that as much in post-training anymore because of, uh, of just the, the formatting and the way that RL is done. Like, you do have to be a little bit more surgical about it, but yeah, everyone can tell you, like, any time we start to see anything worrisome at all in training or, or, or even something going really good, you know, “Lucas, what do we do?” I’m like: Merge it. I’m like, just-01:05:21 Nathan Lambert: Merge.01:05:21 Lucas Atkins: ... I’m like: “Just take it, just merge it. Let’s see.” And more often than not, it fixes it, so...01:05:27 Nathan Lambert: Um, do you merge during RL? Like, you could just, like, merge the last few checkpoints and resume or something?01:05:32 Lucas Atkins: We’ve ex-- we’ve, we’ve dabbled in that, not, not for what we’ve done. You know, again, a, a lot of the, the mini, nano, and large story for Trinity is, like, getting to a level of... what was my level of complexity I was comfortable with us undertaking, and then, uh, not introducing anything more. So, um, not yet. But we, I mean, we, we, uh, regularly merged. We didn’t do it for LARP, but we used to merge a lot, um, during just, like, your standard, uh, um... When we’d do, like, RLHF, we used to do a bunch of merging. We’d do it, like, every five checkpoints. We would-01:06:11 Nathan Lambert: Online RLHF or D-DPO?01:06:13 Lucas Atkins: There’s DPO.01:06:15 Nathan Lambert: Yeah. It’s so much easier to get started. One of my goals is to have somebody figure out how to do actual online RLHF, pure LM feedback, obviously, for scaling. But it’s just like- ... it’s, it’s unsavory to it’s just, like, doesn’t look like DPO-01:06:28 Lucas Atkins: Yeah, I mean, if, if, you know, if GRPO and kind of op-- in, in the, the present day RL regime, like, if that hadn’t materialized when it did, I think that would’ve been a big topic in 2025. But I do think that, you know, GRPO and just the overall, um, DeepSeek and o1 style reasoning and thinking and RL kind of... Any, a- any person who is thinking of doing that for, like, performance reasons, realize that there was something that had fifty thousand papers released every day on how to do it. Um- ... that was kind of probably right where you’d get the same amount of performance.01:07:07 Nathan Lambert: Um, do you force dog feeding? Do you make yourself-- do you guys use your own models to understand them? Like, do you, like, make that a thing?01:07:14 Lucas Atkins: Uh, Mini was the first one we could actually start doing that with, um, a- at least for, uh, a more general day-to-day tasks. So a lot of our, like, internal Slack, we have stuff that, like, monitors Twitter and LinkedIn for feedback on Trinity and, and, and that kind of stuff. That all runs on Trinity Mini now. Um, and then, uh-... you know, we, we put a good amount of work into, into large being, um, you know, good in, in a bunch of your, like, OpenCode and, and Cline, uh, and, and Kilo Code. So, um-01:07:45 Nathan Lambert: Uh, what does that, what does that work look like?01:07:49 Lucas Atkins: Uh, working with those guys to get data. And then, um-01:07:53 Nathan Lambert: That’s, I mean- Good for me to know.01:07:55 Lucas Atkins: I mean-01:07:55 Nathan Lambert: I should do that, I guess.01:07:58 Lucas Atkins: Yeah. Yeah, working with, uh... Or, or I mean, it- the way it started was us, like, using open models and then, like, passing those through as the base URL, and then, like, getting the logs from that. Um, and then realizing that, like, that translated pretty well. Um, and then over time, obviously turning this-01:08:16 Nathan Lambert: Um, can you expand on this? So I was gonna ask you-01:08:19 Lucas Atkins: So-01:08:19 Nathan Lambert: -if you’re, like, using these open models regularly, ‘cause I, I’m just, like, Claude Code psychosis, man. I’m like, “Can’t take that away from me.”01:08:26 Lucas Atkins: Yeah, I, I use, I use four... I’ve used 4.7 a lot. I think 4.7 from GLM was one of the first ones that could replace a lot of my day-to-day. Uh, I’ll still reach for Claude Code or even 5.2 Pro if it’s, if it’s, like, something that’s, like, really... I- if I do not know how to measure what success looks like for something, I’ll usually use those. Um, but, uh, yeah, I mean, it, it- even using DeepSeek before, um, kind of their May update was hit or miss. But, um, yeah, w- the reason I decided to, like, start talking to these people and working on, like, how can we get data and, and start making our models good in these systems was I would use them. I had a, um, you know, something that would grab the logs, like, it, you know, inter- as a proxy, so it’d like grab the logs and then format them in the messages format. And then I saw that and went, “Yeah, that’s... You can make a pretty good filter for just, like, standard stuff that you don’t want, and kind of hit a scale.”01:09:30 Nathan Lambert: Yeah, it makes sense. So, so you’re like, uh, open code will let you look at the data, and then you’re probably gonna get a sense for... Like, I don’t even actually know how the, on the back end, the code agents in open code format data, which I think is actually something I should just go look at, ‘cause then you can design around.01:09:44 Lucas Atkins: Uh, they’re all different. Yeah. Yeah, but you just have to- you just- basically, it all starts from like, what do you want your format to be? And then how can you take what, what those look like to, you know, to... How do you force it into that? The hard thing, though, is, is with newer models like MiniMax and 4.7, the way they do interleaved thinking is, is like... You know, I’m a big believer in post-training. Like, if you’re gonna do interleaved thinking, like, every sample in your data set should be that. Um, it, you know, it should follow that same format and that same behavior. So, um, that gets tricky if you’re trying to, like, take a bunch of Nemo tr... Or, or, or, well, like, uh, DeepSeek data and Qwen data, and then, oh, we’re also trying to mix in MiniMax, and at that point, you’re- it, it gets really difficult ‘cause they all handle thinking slightly differently.01:10:34 Nathan Lambert: Yeah, I can buy this. Um, okay, this was fun. Any last predictions or things you want people to know about the model? I will say that, um, when you debuted the Trinity models, you had a great blog post that was very to the point, that covered a lot of this. So I’ll definitely link to the, um, what is it? The Trinity manifesto. I enjoyed reading it. So I’ll link to that in the show notes, and, oh, hopefully you have a new one for me to read when you’re done with the model.01:10:58 Lucas Atkins: Yeah, we’ll do- we will have a tech report. We’ll have a tech report for you, too. So we, we never, we never did a tech report for 4.5B Mini or Nano because we were so focused on just getting to large, but we also thought it’d be very interesting to write it under the, the... How do you go from 4.5B to a 400B MoE in six months, and, like, what did we learn-01:11:19 Nathan Lambert: That’s right01:11:19 Lucas Atkins: ... when you’re viewing it as a whole, so.01:11:21 Nathan Lambert: That’s about the timeframe that, um, Ant Ling took, too, as well. Ant Ling, uh, the anchor, we talked about, they’re like... It took us about six months to do, um, Ring-1T and their 1T models, which, like, it sounds like a lot more, but I think that’s about the same. It, it depends on compute and configs and stuff to go from, like- ... basic modeling to big MoE, which is pretty interesting to see a lot of people speedrun this sort of thing.01:11:46 Lucas Atkins: Yeah, it’s, it’s a really, uh... It is a logistical nightmare, but, like, I think everyone on the team has had a tremendous amount of fun over the last, uh, six months. So now the fun begins.01:11:58 Nathan Lambert: Yeah. Congrats on the milestone. Congrats on the model existing. That has gotta be an almighty relief, and I’ll look forward- ... to see what you all are up to soon. I’ll stop by at some point next time I’m in the Bay.01:12:10 Lucas Atkins: Yeah. Yeah, come by. Yeah, come by.01:12:12 Nathan Lambert: Thanks for-01:12:12 Lucas Atkins: Thanks for having us.01:12:14 Nathan Lambert: Yeah. Thanks, guys. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 1h 12m 15s | ||||||
| 1/21/26 |  Get Good at Agents | Two weeks ago, I wrote a review of how Claude Code is taking the AI world by storm, saying that “software engineering is going to look very different by the end of 2026." That article captured the power of Claude as a tool and a product, and I still stand by it, but it undersold the changes that are coming in how we use these products in careers that interface with software. The more personal angle was how “I’d rather do my work if it fits the Claude form factor, and soon I’ll modify my approaches so that Claude will be able to help.” Since writing that, I’m stuck with a growing sense that taking my approach to work from the last few years and applying it to working with agents is fundamentally wrong. Today’s habits in the era of agents would limit the uplift I get by micromanaging them too much, tiring myself out, and setting the agents on too small of tasks. What would be better is more open ended, more ambitious, more asynchronous. I don’t yet know what to prescribe myself, but I know the direction to go, and I know that searching is my job. It seems like the direction will involve working less, spending more time cultivating peace, so the brain can do its best directing — let the agents do most of the hard work.Since trying Claude Code with Opus 4.5, my work life has shifted closer to trying to adapt to a new way of working with agents. This new style of work feels like a larger shift than the era of learning to work with chat-based AI assistants. ChatGPT let me instantly get relevant information or a potential solution to the problems I was already working on. Claude Code has me considering what should I work on now that I know I can have AI independently solve or implement many sub-components. Every engineer needs to learn how to design systems. Every researcher needs to learn how to run a lab. Agents push the humans up the org chart.I feel like I have an advantage by being early to this wave, but no longer feel like just working hard will be an lasting edge. When I can have multiple agents working productively in parallel on my projects, my role is shifting more to pointing the army rather than using the power-tool. Pointing the agents more effectively is far more useful than me spending a few more hours grinding on a problem. My default workflow now is GPT 5 Pro for planning, Claude Code with Opus 4.5 for implementation. I often have Claude Code pass information back to GPT 5 Pro for a deep search when stuck with a very detailed prompt. Codex with GPT 5.2 on xhigh thinking effort alone feels very capable, more meticulous than Claude even, but I haven’t yet figured out how to get the best out of it. GPT Pro feels itself to be a strong agent trapped in the wrong UX — it needs to be able to think longer and have a place to work on research tasks.It seems like all of my friends (including the nominally “non-technical” ones) have accepted that Claude can rapidly build incredible, bespoke software for you. Claude updated one of my old research projects to uv so it’s easier to maintain, made a verification bot for my Discord, crafted numerous figures for my RLHF book, feels close to landing a substantial feature in our RL research codebase, and did countless other tasks that would’ve taken me days. It’s the thing de jour — tell your friends and family what trinket you built with Claude. It undersells what’s coming.I’ve taken to leaving Claude Code instances running on my DGX Spark trying to implement new features in our RL codebase when I’m at dinner or work. They make mistakes, they catch most of their own mistakes, and they’re fairly slow too, but they’re capable. I can’t wait to go home and check on what my Claudes were up to.Interconnects is a reader-supported publication. Consider becoming a subscriber.The feeling that I can’t shake is a deep urgency to move my agents from working on toy software to doing meaningful long-term tasks. We know Claude can do hours, days, or weeks, of fun work for us, but how do we stack these bricks into coherent long-term projects? This is the crucial skill for the next era of work.There are no hints or guides on working with agents at the frontier — the only way is to play with them. Instead of using them for cleanup, give them one of your hardest tasks and see what it gets stuck on, see what you can use it for.Software is becoming free, good decision making in research, design, and product has never been so valuable.Being good at using AI today is a better moat than working hard.Here are a collection of pieces that I feel like suitably grapple with the coming wave or detail real practices for using agents. It’s rare that so many of the thinkers in the AI space that I respect are all fixated on a single new tool, a transition period, and a feeling of immense change:* Import AI 441: My agents are working. Are yours? This helped me motivate to write this and focus on how important of a moment this is.* Steve Newman on Hyperproductivity with AI coding agents — importantly written before Claude Opus 4.5, which was a major step change.* Tim Dettmers on working with agents: Use Agents or Be Left Behind? * Steve Yegge on Latent Space on vibe coding (and how you’ll be left behind if you don’t understand how to do it).* Dean W. Ball: Among the Agents — why coding agents aren’t just for programmers. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe | 5m 05s | ||||||
Showing 25 of 156
Pitch Fit is a Pro feature
See how bookable this show is for guests, which brands already advertise, the per-episode ad value, and the best-fit guest and sponsor profile. The numbers are blurred on the free plan.
How readily this show books outside guests like you.
How proven this show is for host-read sponsorships.
For Guests
ProFor Advertisers
ProUpgrade to Pro to unlock guest cadence, sponsor categories, fit scores, and per-episode ad value for this show.
Similar Audience Demographics
Podcasts that attract a similar listener profile

Machine Learning Street Talk (MLST)
Machine Learning Street Talk (MLST)

Unsupervised Learning with Jacob Effron
by Redpoint Ventures

No Priors: Artificial Intelligence | Technology | Startups
Conviction

The TWIML AI Podcast (formerly This Week in Machine Learning & Artificial Intelligence)
Sam Charrington

Dwarkesh Podcast
Dwarkesh Patel

Training Data
Sequoia Capital

AI + a16z
a16z
Chart Positions
6 placements across 6 markets.
Chart Positions
6 placements across 6 markets.