
Insights from recent episode analysis
Audience Interest
Podcast Focus
Publishing Consistency
Platform Reach
Insights are generated by CastFox AI using publicly available data, episode content, and proprietary models.
Most discussed topics
Brands & references
Total monthly reach
Estimated from 6 chart positions in 6 markets.
By chart position
- 🇸🇪SE · Technology#9410K to 30K
- 🇯🇵JP · Technology#1111K to 10K
- 🇪🇸ES · Technology#1261K to 10K
- 🇬🇷GR · Technology#2710K to 30K
- 🇫🇮FI · Technology#603K to 10K
- Per-Episode Audience
Est. listeners per new episode within ~30 days
14K to 50K🎙 ~2x weekly·195 episodes·Last published 3d ago - Monthly Reach
Unique listeners across all episodes (30 days)
28K to 100K🇸🇪30%🇬🇷30%🇯🇵10%+3 more - Active Followers
Loyal subscribers who consistently listen
11K to 40K
Market Insights
Platform Distribution
Reach across major podcast platforms, updated hourly
Total Followers
—
Total Plays
—
Total Reviews
—
* Data sourced directly from platform APIs and aggregated hourly across all major podcast directories.
On the show
From 1 epsHost
Recent guests
Recent episodes
Can AI Learn What Experts Know? Automating Prior Elicitation with Generative Models
Jun 2, 2026
Unknown duration
#158 Bayesian Workflows & Foundation Models, with Stefan Radev
May 21, 2026
Unknown duration
The Hidden Geometry of Hierarchical Models
May 13, 2026
Unknown duration
#157 Amortized Inference & BayesFlow in Practice, with Stefan Radev
May 6, 2026
Unknown duration
How to Design Better Experiments with Expected Information Gain
May 1, 2026
5m 42s
Social Links & Contact
Official channels & resources
Official Website
Login
RSS Feed
Login
| Date | Episode | Topics | Guests | Brands | Places | Keywords | Sponsor | Length | |
|---|---|---|---|---|---|---|---|---|---|
| 6/2/26 | 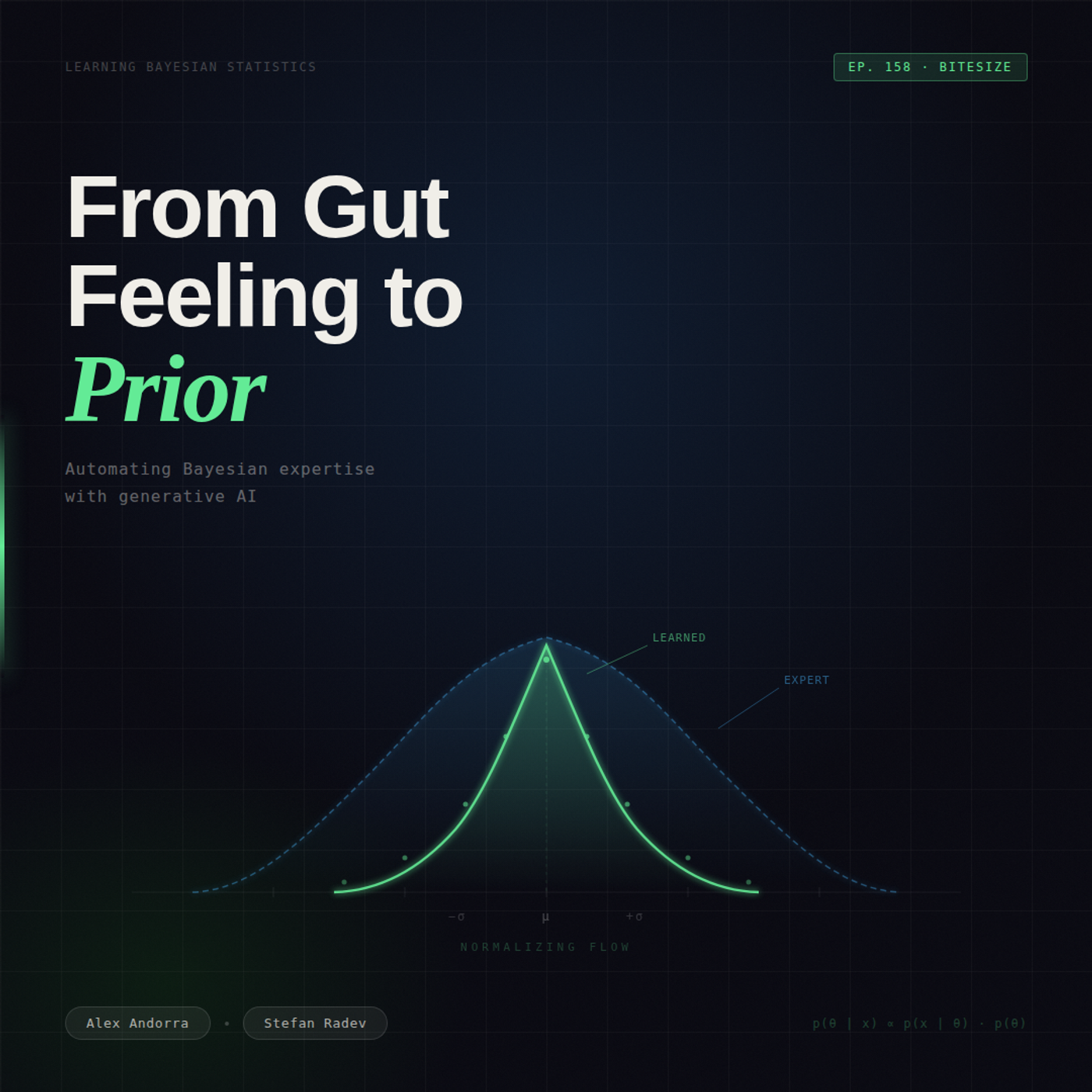 Can AI Learn What Experts Know? Automating Prior Elicitation with Generative Models | Today's clip is from episode 158 featuring Stefan Radev. In this conversation, Alex and Stefan explore a genuinely fascinating problem: how do you turn an expert's intuition into a mathematically valid prior distribution - and can AI help automate that process?Alex explains that prior elicitation is essentially a translation problem. Experts don't walk around thinking in probability distributions - their knowledge lives in intuitions, rules of thumb, and rough ranges. The challenge is converting that into something a Bayesian model can actually use.The traditional approach? Ask an expert for quantiles or a mean, then parameterize your prior with hyperparameters and simulate until the model-implied quantities match what the expert described. If your pipeline is differentiable end-to-end, you use gradient descent. If not, you fall back to something like Bayesian optimization. Either way, you're iterating toward a prior that genuinely reflects expert knowledge - not just a convenient assumption.But the really exciting part is what came next. In a follow-up paper, they pushed this further: instead of optimizing within a fixed parametric family (say, a Gaussian), they replaced the prior entirely with a normalizing flow - a flexible generative network - and ran the same procedure. No assumed distribution family. Just let the data and the expert's knowledge shape the prior from scratch.The catch? More flexibility means more non-identifiability and stability headaches. But the direction is clear: a fully automated, end-to-end pipeline for building priors from non-probabilistic expert knowledge. And in 2026, that pipeline could theoretically be driven by an agent.Get the full discussion hereSupport & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work | — | ||||||
| 5/21/26 |  #158 Bayesian Workflows & Foundation Models, with Stefan Radev | Support & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome workTakeaways:Q: Why are prior predictive checks so underused in practice, and how do simulations help?A: They're underused because researchers don't always think to run them before seeing data -- but also because doing them rigorously (in the style Michael Betancourt advocates, with prior push-forward checks on interpretable summaries) takes effort. Simulations make it cheap to generate thousands of “what-if world” datasets from your model and check whether they look plausible, catching bad priors before you ever touch real data.Q: How can generative AI help with prior elicitation?A: Rather than forcing a domain expert to choose a distributional family and parameterize it, you can use a generative model to translate their qualitative knowledge directly into a prior. The expert describes what realistic data should look like; the generative model produces synthetic datasets matching that description; those datasets are used to fit a prior distribution. It removes the assumption that experts can think in terms of parameters and replaces it with the more natural question: does this look like your data?Q: What would a foundation model for Bayesian inference actually look like?A: Stefan's bet is that it won't be a fine-tuned general LLM. The right analogy is chess: you don't fine-tune GPT to play chess, you teach it when to call Stockfish. For Bayesian inference, you'd want a semantic layer – an LLM that understands the analysis goal – calling specialized numerical engines (MCMC samplers, amortized inference networks) that do the actual computation. Agent skills are already a step in this direction; the longer-term vision is engines that have been trained from scratch to generalize across large families of models and priors.Full takeaways here.Chapters:00:00 How does amortized inference fit into modern Bayesian workflows?06:01 What role do simulations play across the full Bayesian workflow?12:12 How do you elicit priors from a domain expert who doesn't think in distributions?19:01 What would a foundation model for Bayesian inference actually look like?35:32 What is self-consistency in amortized inference and why does it matter?39:22 How does semi-supervised learning improve simulation-based inference?43:16 Why is sensitivity analysis so important yet so underused in Bayesian practice?47:40 What is multiverse analysis and how does it change how we report Bayesian results?51:32 How does amortized inference make sensitivity and multiverse analysis affordable?01:02:47 How do amortized inference and classical MCMC complement each other?01:10:08 What are the next major directions for BayesFlow and amortized inference research?Thank you to my Patrons for making this episode possible!Links from the show here. | — | ||||||
| 5/13/26 |  The Hidden Geometry of Hierarchical Models | Today's clip is from Episode 157 featuring Stefan Radev. In this conversation, Alex and Stefan dig into one of the hardest open problems in simulation-based inference — hierarchical models.The core idea: when you move from flat to hierarchical models, you're no longer estimating one set of parameters. You have local parameters that vary by location (or subject, or city) and global parameters that capture what's shared across all of them. And you don't just want each separately — you want the full joint posterior, because that's where the Bayesian magic of shrinkage actually lives.Stefan builds the problem from the ground up. Start with the simplest hierarchical case: a two-level model. He uses electoral forecasting in France as the example — cities nested inside departments nested inside the whole country.Now your simulator has to cover all three levels. If that simulator is slow (think: brain emulators, minutes per sample), scaling to hundreds of groups becomes completely intractable. Memory issues, specialized network requirements, the works.The key insight: this problem has structure you can exploit. The joint posterior factorizes in a particularly nice way — each local parameter depends on its own local data and on the global parameters. That means instead of cramming everything into one giant high-dimensional vector and hoping a neural network figures it out, you can decompose the problem. Estimate local parameters conditioned on local data and the globals. Use composition.The takeaway: hierarchical models aren't just "harder flat models" - they have a geometry that demands a different architecture. Respecting that structure is what makes amortized inference scale.Get the full discussion hereSupport & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work | — | ||||||
| 5/6/26 |  #157 Amortized Inference & BayesFlow in Practice, with Stefan Radev | Support & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome workTakeaways:Q: What is simulation-based inference and what does "sim-to-real" mean?A: Simulation-based inference (SBI) uses a mechanistic simulator as an epistemic tool: you train a neural network on a large number of labeled simulations and then deploy it on real, unlabeled data. The "sim-to-real" framing captures the key asymmetry -- your network never sees real data during training, only simulations, but it generalizes to real observations at inference time. This is the opposite of the more common "synthetic-for-ML" approach, where fake data is used purely to augment real training data.Q: What is the amortized inference agent skill and what does it do?A: It's an open-source AI agent skill, co-developed by Stefan and Alexandre, that teaches an AI coding agent to run a complete, state-of-the-art amortized inference workflow. Because amortized inference is recent enough that it's underrepresented in LLM training data, vanilla agents tend to get it wrong. The skill injects the right methodology: it guides the agent to set up the simulator, choose the right network architecture, run a pilot, train with appropriate diagnostics, and produce an actionable report -- without the user needing to know the details.Q: What is calibration coverage and why should you never skip it?A: Calibration coverage tells you whether your posterior uncertainty is honest -- whether your credible intervals actually contain the true parameter at the right frequency. A model can show poor parameter recovery yet still be well-calibrated (because it's falling back on the prior), or it can appear to recover parameters while being poorly calibrated. Running calibration diagnostics both in-sample and out-of-sample is especially revealing for hierarchical models, which often appear to underfit in-sample but generalize much better out-of-sample thanks to shrinkage.Full takeaways hereChapters:00:00:00 How does amortized inference fit into the Bayesian workflow?00:12:03 What does "sim-to-real" mean in simulation-based inference?00:15:57 Why is amortized inference particularly suited to psychology and neuroscience?00:21:51 What is the amortized inference agent skill?00:39:00 What is calibration coverage and how do you interpret it?00:41:50 How do you decide what to do next after your first training run?00:44:53 How do actionable insights make Bayesian workflows more usable?00:49:08 What are the unique challenges of hierarchical models in amortized inference?01:00:51 What is the current state of BayesFlow's support for hierarchical models?01:05:00 What are the main failure modes of amortized inference and how do you handle model misspecification?Thank you to my Patrons for making this episode possible!Links from the show | — | ||||||
| 5/1/26 |  How to Design Better Experiments with Expected Information Gain✨ | Bayesian experimental designExpected Information Gain+3 | Adam Foster | Good Bayesian | — | Expected Information GainBayesian statistics+3 | — | 5m 42s | |
| 4/25/26 |  #156 Bayesian Experimental Design & Active Learning, with Adam Foster | Support & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome workTakeawaysQ: What is Bayesian experimental design and what problem does it solve?A: It's the practice of using a Bayesian model to decide how to collect data before you collect it. Most statistical thinking starts with a fixed dataset. Bayesian experimental design sits upstream -- you have control over experimental parameters (which questions to ask, which reagents to mix, which conditions to test) and you want to choose them optimally. The Bayesian angle is to ask: what new data would most reduce my current uncertainty?Q: When should you actually use Bayesian experimental design?A: When two conditions hold: you have active control over how data is collected (not just passive observation), and you have a Bayesian model whose prior predictive distribution gives a reasonable picture of what typical data might look like. It's especially valuable when data collection is expensive or irreversible -- when the "committal step" of running an experiment has real cost, it's worth doing the analysis first.Q: What is expected information gain (EIG) and why is it central to Bayesian experimental design?A: EIG is the score you assign to a candidate experimental design -- the amount of information you expect to gain about your model parameters by running an experiment with that design. You compute it by simulating datasets from your prior predictive, doing Bayesian inference on each, and averaging how much the uncertainty decreased. What's remarkable is that you can derive the same quantity from two completely different starting points -- reducing parameter uncertainty, or maximizing outcome uncertainty while correcting for noise - and arrive at the same formula. That convergence is why EIG keeps being re-discovered independently across fields.Full takeaways hereChapters:00:00 What is Bayesian experimental design and why does it matter?00:06:02 What problem does Bayesian experimental design actually solve?00:08:54 When should practitioners use Bayesian experimental design?00:12:00 Is Bayesian experimental design changing how scientists work in practice?00:15:04 What are the limitations of Bayesian experimental design?00:17:55 What is expected information gain (EIG) and how does it work?00:21:05 How do you compute expected information gain in practice?00:23:48 What is active learning and how does it connect to Bayesian experimental design?00:41:02 What is active learning by disagreement?00:48:57 What is deep adaptive design and when should you00: use it?00:56:02 How is Bayesian experimental design applied in protein dynamics and quantum chemistry?01:01:58 What does a practical Bayesian experimental design workflow look like?Thank you to my Patrons for making this episode possible!Links from the show | — | ||||||
| 4/16/26 | 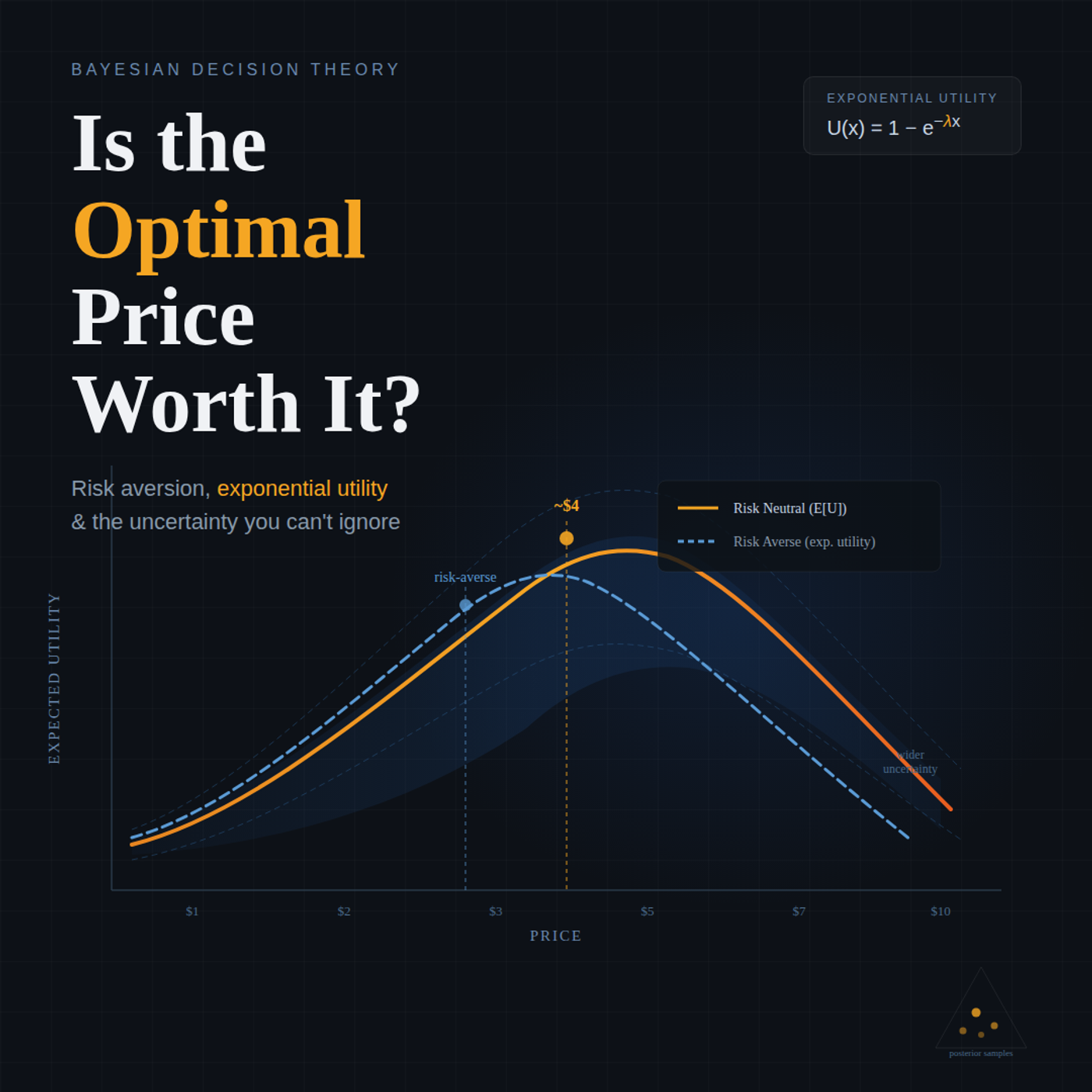 Pricing Under Uncertainty: A Bayesian Workflow | Today's clip is from Episode 152 of the podcast, featuring Daniel Saunders. In this conversation, Daniel explores how Bayesian decision theory handles real-world risk aversion beyond the textbook maximum expected utility framework.The key insight: classical Bayesian decision theory assumes risk neutrality, but in practice, people and businesses are risk-averse. Using a pricing optimization example, Daniel shows how uncertainty varies dramatically across price points—lower prices have predictable demand, while higher prices create wide uncertainty in profits. This asymmetry matters when you want safer decisions.Daniel introduces exponential utility functions—a technique from economics that models diminishing returns on money. By adjusting a risk-aversion parameter, you can see how increasing risk aversion shifts optimal decisions away from high-uncertainty, high-profit scenarios toward more predictable outcomes.The broader lesson: optimal decision-making requires separating the modeling process from the decision process, allowing you to build in constraints and risk adjustments that pure expected utility maximization would miss.Get the full discussion hereSupport & Resources→ Support the show on Patreon: https://www.patreon.com/c/learnbayesstats→ Bayesian Modeling Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 4/8/26 |  #155 Probabilistic Programming for the Real World, with Andreas Munk | Support & Resources→ Support the show on Patreon→ Bayesian Modeling Course (first 2 lessons free): Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work Takeaways:Q: Why is bridging deep learning and probabilistic programming so important?A: Deep learning is extraordinarily good at fitting complex functions, but it throws away uncertainty. Probabilistic programming keeps uncertainty explicit throughout. Combining the two – as in inference compilation – lets you get the expressiveness of neural networks while still doing proper Bayesian inference.Q: What is inference compilation and how does it relate to amortized inference?A: Amortized inference is the general idea of training a model upfront so you don't have to run expensive inference from scratch every single time. Inference compilation is a specific form of amortized inference where a neural network is trained to propose good posterior samples for a given probabilistic program – essentially learning to do inference rather than computing it fresh each query.Q: What is PyProb and what problems does it solve?A: PyProb is a probabilistic programming library designed specifically to support amortized inference workflows. It lets you write probabilistic models in Python and then train inference networks on top of them, making methods like inference compilation practical for real-world simulators and scientific models.Full takeaways here.Chapters:00:00:00 Introduction to Bayesian Inference and Its Barriers00:03:51 Andreas Munch's Journey into Statistics00:10:09 Bridging the Gap: Bayesian Inference in Real-World Applications00:15:56 Deep Learning Meets Probabilistic Programming00:22:05 Understanding Inference Compilation and Amortized Inference00:28:14 Exploring PyProb: A Tool for Amortized Inference00:33:55 Probabilistic Surrogate Networks and Their Applications00:38:10 Building Surrogate Models for Probabilistic Programming00:45:44 The Challenge of Bayesian Inference in Enterprises00:52:57 Communicating Uncertainty to Stakeholders01:01:09 Democratizing Bayesian Inference with Evara01:06:27 Insurance Pricing and Latent Variables01:16:41 Modeling Uncertainty in Predictions01:20:29 Dynamic Inference and Decision-Making01:23:17 Updating Models with Actual Data01:26:11 The Future of Bayesian Sampling in Excel01:31:54 Navigating Business Challenges and Growth01:36:40 Exploring Language Models and Their Applications01:38:35 The Quest for Better Inference Algorithms01:41:01 Dinner with Great Minds: A Thought ExperimentThank you to my Patrons for making this episode possible!Links from the show here. | — | ||||||
| 4/2/26 | 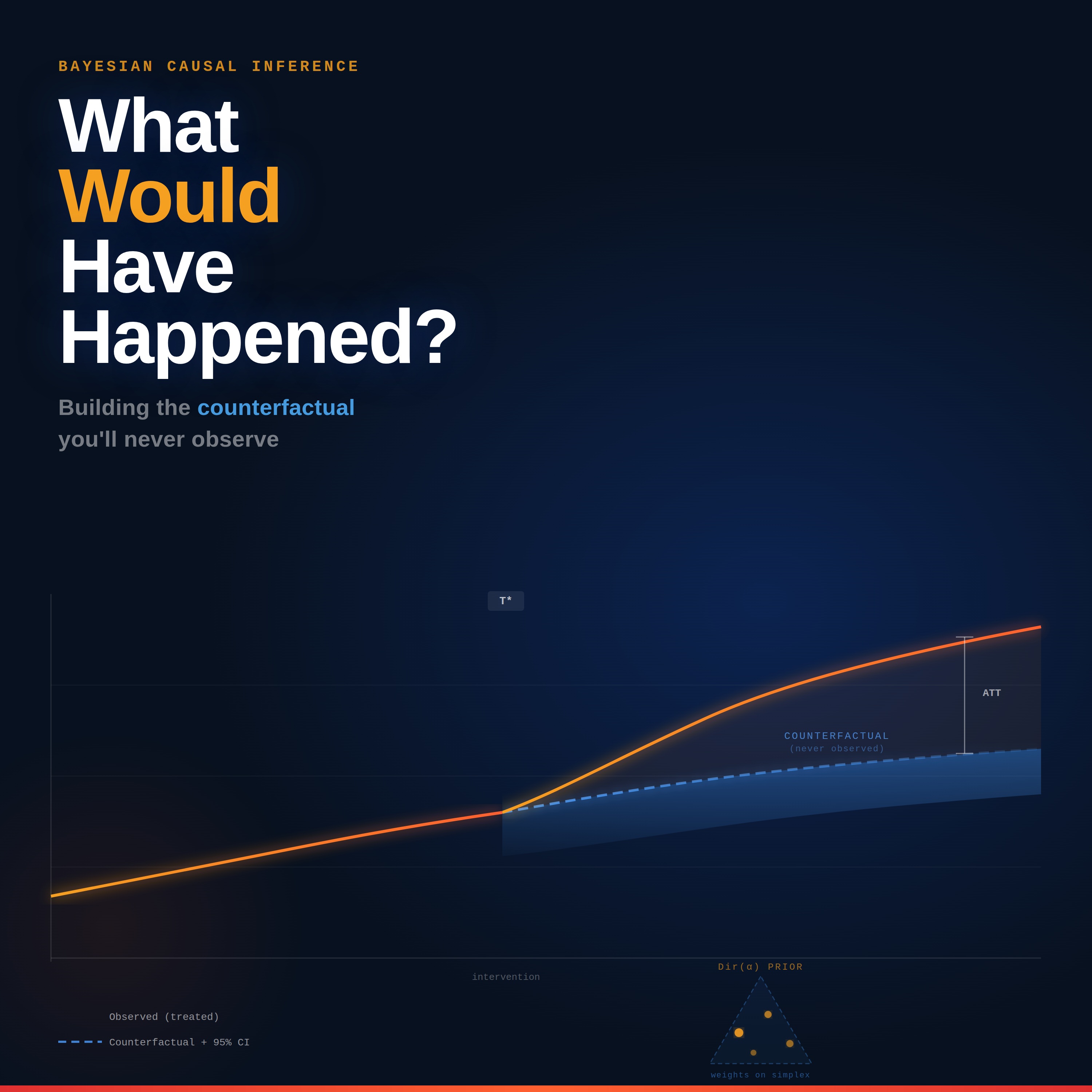 Bitesize | "What Would Have Happened?" - Bayesian Synthetic Control Explained | Today's clip is from Episode 154 of the podcast, with Thomas Pinder.In this conversation, Thomas Pinder explains how Bayesian methods naturally lend themselves to causal modeling, and why that matters for real-world business decisions. The key insight is that causal questions in industry are rarely black and white: instead of a single treatment effect, you get a full posterior distribution, credible intervals, and the ability to communicate the probability that an effect is positive, which is far more useful to stakeholders than a p-value.Thomas then dives into Bayesian Synthetic Control, a reframing of the classic synthetic control method from a constrained optimization problem into a Bayesian regression problem. Rather than optimizing weights on a simplex, you place a Dirichlet prior on the regression coefficients, which turns out to be not just mathematically elegant but practically richer: you can express prior beliefs about how many control units are informative, set the concentration parameter accordingly, or let a gamma hyperprior on that parameter let the data decide. The result is a more flexible, less fragile counterfactual, implemented cleanly in PyMC or NumPyro.Get the full discussion here Support & Resources→ Support the show on Patreon: https://www.patreon.com/c/learnbayesstats→ Bayesian Modeling Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 3/25/26 |  #154 Bayesian Causal Inference at Scale, with Thomas Pinder | • Support & get perks!• Bayesian Modeling course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work! Takeaways:Q: Why was GPJax created and how does it benefit researchers?A: GPJax was developed to provide a high-performance, flexible framework for Gaussian processes (GPs) within the JAX ecosystem. It allows researchers to move beyond black-box implementations and easily experiment with custom kernels and model structures while leveraging JAX’s automatic differentiation and GPU acceleration.Q: What are the primary advantages of using Gaussian processes for data modeling?A: Gaussian processes are highly effective at modeling complex, nonlinear relationships in data. Unlike many machine learning methods that only provide a point estimate, GPs offer built-in uncertainty quantification, which is essential for understanding the reliability of predictions in research and industry.Q: How does the GPJax and NumPyro integration enhance probabilistic modeling?A: The integration allows users to treat GPJax models as components within a larger NumPyro probabilistic program. This combination enables the use of advanced sampling techniques like NUTS (No-U-Turn Sampler), making it easier to build and fit complex hierarchical models that include Gaussian processes.Q: What are the main challenges when applying Gaussian processes to high-dimensional data?A: High-dimensional data significantly complicates GP modeling due to the curse of dimensionality and the cubic scaling of computational costs. In high dimensions, defining meaningful distance metrics for kernels becomes harder, often requiring specialized techniques like sparse GPs or dimensionality reduction to remain tractable.Full takeaways here!Chapters:11:40 What is GPJax and how does it simplify Gaussian Process modeling?15:48 How are Bayesian methods used for experimentation and causal inference in industry?18:40 How do you implement Bayesian Synthetic Control?32:17 What is Bayesian Synthetic Difference-in-Differences?39:44 What are the research applications and supported methods for the GPJax library?45:47 What are the primary software and computational bottlenecks when scaling Gaussian Processes?49:02 What are the real-world industrial applications of Gaussian Process models?54:36 How is Bayesian modeling applied to soccer and sports analytics?58:43 What is the future development roadmap for the GPJax ecosystem?01:05:37 What is Impulso and how does it integrate into a Bayesian modeling workflow?01:13:42 How do you balance Bayesian computational overhead with industrial latency requirements?01:20:26 Why is there optimism that scalable Bayesian methods for causal inference are now within reach?Thank you to my Patrons for making this episode possible!Links from the show here! | — | ||||||
Want analysis for the episodes below?Free for Pro Submit a request, we'll have your selected episodes analyzed within an hour. Free, at no cost to you, for Pro users. | |||||||||
| 3/11/26 |  #153 The Neuroscience of Philanthropy, with Cherian Koshy | • Support & get perks!• Bayesian Modeling course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Takeaways:Q: Is generosity a natural human trait?A: Yes, generosity is hardwired in our brains and is essential for social interaction.Q: Why do people say they care about causes but not act on it?A: There is often a disconnect between stated care for causes and actual action. Understanding the conditions under which generosity aligns with a person's identity is crucial for bridging this gap.Q: How should fundraising efforts be approached?A: Fundraising should primarily focus on belief updating rather than mere persuasion.Q: What are the benefits of being generous?A: Generosity has significant mental and physical health benefits, as the brain's reward systems activate when we give, making us feel good.Q: How do our beliefs relate to our actions?A: Our beliefs about ourselves strongly influence our actions and decisions, including our decision to be generous.Q: Can generosity impact a community?A: Yes, generosity can be a powerful tool for improving community dynamics.Q: How can technology like AI assist institutions with donors?A: AI could help institutions remember donors better, improving the donor-institution relationship.Chapters:00:00 What's the role of Behavioral Science inPhilanthropy19:57 What is The Neuroscience of Generosity?24:40 How can we best understand Donor Decision-Making?32:14 How can we achieve reframe Beliefs and Actions?35:39 What is the role of Identity in Habit Formation?38:06 What is the Generosity Gap in Philanthropy?45:06 How can we reduce Friction in Donation Processes?48:27 What is the role of AI and Trust in Nonprofits?52:11 How can we build Predictive Models for Donor Behavior?55:41 What is the role of Empathy in Sales and Stakeholder Engagement?01:00:46 How can we best align ideas with Stakeholder Beliefs?01:02:06 How can we explore Generosity and Memory?Thank you to my Patrons for making this episode possible!Links from the show:Come meet Alex at the Field of Play Conference in Manchester, UK, March 27, 2026! https://www.fieldofplay.co.uk/Bayesian workflow agent skillNeurogiving, The Science of Donor Decision-MakingCherian's websiteCherian's press kitLBS #89 Unlocking the Science of Exercise, Nutrition & Weight Management, with Eric Trexler | — | ||||||
| 3/4/26 |  Bitesize | How To Model Risk Aversion In Pricing? | Today's clip is from Episode 152 of the podcast, with Daniel Saunders. In this conversation, Daniel Saunders explains how to incorporate risk aversion into Bayesian price optimization. The key insight is that uncertainty around expected profit is asymmetric across price points, low prices yield more predictable (if modest) returns, while high prices introduce much wider uncertainty. Rather than simply maximizing expected profit, you can pass profit through an exponential utility function that models diminishing returns, a well-established idea from economics. This adds an adjustable risk aversion parameter to the optimization: as risk aversion increases, the model shifts toward more conservative price recommendations, trading off potentially large but uncertain gains for outcomes with tighter, more reliable distributions.Get the full discussion here• Join this channel to get access to perks:https://www.patreon.com/c/learnbayesstats• Intro to Bayes Course (first 2 lessons free): https://topmate.io/alex_andorra/503302• Advanced Regression Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 2/26/26 |  #152 A Bayesian decision theory workflow, with Daniel Saunders | • Support & get perks!• Proudly sponsored by PyMC Labs!• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:00:00 The Importance of Decision-Making in Data Science06:41 From Philosophy to Bayesian Statistics14:57 The Role of Soft Skills in Data Science18:19 Understanding Decision Theory Workflows22:43 Shifting Focus from Accuracy to Business Value26:23 Leveraging PyTensor for Optimization34:27 Applying Optimal Decision-Making in Industry40:06 Understanding Utility Functions in Regulation41:35 Introduction to Obeisance Decision Theory Workflow42:33 Exploring Price Elasticity and Demand45:54 Optimizing Profit through Bayesian Models51:12 Risk Aversion and Utility Functions57:18 Advanced Risk Management Techniques01:01:08 Practical Applications of Bayesian Decision-Making01:06:54 Future Directions in Bayesian Inference01:10:16 The Quest for Better Inference Algorithms01:15:01 Dinner with a Polymath: Herbert SimonThank you to my Patrons for making this episode possible!Links from the show:Come meet Alex at the Field of Play Conference in Manchester, UK, March 27, 2026! https://www.fieldofplay.co.uk/A Bayesian decision theory workflowDaniel's website, LinkedIn and GitHubLBS #124 State Space Models & Structural Time Series, with Jesse GrabowskiLBS #123 BART & The Future of Bayesian Tools, with Osvaldo MartinLBS #74 Optimizing NUTS and Developing the ZeroSumNormal Distribution, with Adrian SeyboldtLBS #76 The Past, Present & Future of Stan, with Bob Carpenter | — | ||||||
| 2/19/26 |  BITESIZE | How Do Diffusion Models Work? | Today's clip is from Episode 151 of the podcast, with Jonas ArrudaIn this conversation, Jonas Arruda explains how diffusion models generate data by learning to reverse a noise process. The idea is to start from a simple distribution like Gaussian noise and gradually remove noise until the target distribution emerges. This is done through a forward process that adds noise to clean parameters and a backward process that learns how to undo that corruption. A noise schedule controls how much noise is added or removed at each step, guiding the transformation from pure randomness back to meaningful structure.Get the full discussion here• Join this channel to get access to perks:https://www.patreon.com/c/learnbayesstats• Intro to Bayes Course (first 2 lessons free): https://topmate.io/alex_andorra/503302• Advanced Regression Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 2/12/26 |  #151 Diffusion Models in Python, a Live Demo with Jonas Arruda | • Support & get perks!• Proudly sponsored by PyMC Labs!• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:00:00 Exploring Generative AI and Scientific Modeling10:27 Understanding Simulation-Based Inference (SBI) and Its Applications15:59 Diffusion Models in Simulation-Based Inference19:22 Live Coding Session: Implementing Baseflow for SBI34:39 Analyzing Results and Diagnostics in Simulation-Based Inference46:18 Hierarchical Models and Amortized Bayesian Inference48:14 Understanding Simulation-Based Inference (SBI) and Its Importance49:14 Diving into Diffusion Models: Basics and Mechanisms50:38 Forward and Backward Processes in Diffusion Models53:03 Learning the Score: Training Diffusion Models54:57 Inference with Diffusion Models: The Reverse Process57:36 Exploring Variants: Flow Matching and Consistency Models01:01:43 Benchmarking Different Models for Simulation-Based Inference01:06:41 Hierarchical Models and Their Applications in Inference01:14:25 Intervening in the Inference Process: Adding Constraints01:25:35 Summary of Key Concepts and Future DirectionsThank you to my Patrons for making this episode possible!Links from the show:- Come meet Alex at the Field of Play Conference in Manchester, UK, March 27, 2026!- Jonas's Diffusion for SBI Tutorial & Review (Paper & Code)- The BayesFlow Library- Jonas on LinkedIn- Jonas on GitHub- Further reading for more mathematical details: Holderrieth & Erives- 150 Fast Bayesian Deep Learning, with David Rügamer, Emanuel Sommer & Jakob Robnik- 107 Amortized Bayesian Inference with Deep Neural Networks, with Marvin Schmitt | — | ||||||
| 1/28/26 |  #150 Fast Bayesian Deep Learning, with David Rügamer, Emanuel Sommer & Jakob Robnik | • Support & get perks!• Proudly sponsored by PyMC Labs!• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:00:00 Scaling Bayesian Neural Networks04:26 Origin Stories of the Researchers09:46 Research Themes in Bayesian Neural Networks12:05 Making Bayesian Neural Networks Fast16:19 Microcanonical Langevin Sampler Explained22:57 Bottlenecks in Scaling Bayesian Neural Networks29:09 Practical Tools for Bayesian Neural Networks36:48 Trade-offs in Computational Efficiency and Posterior Fidelity40:13 Exploring High Dimensional Gaussians43:03 Practical Applications of Bayesian Deep Ensembles45:20 Comparing Bayesian Neural Networks with Standard Approaches50:03 Identifying Real-World Applications for Bayesian Methods57:44 Future of Bayesian Deep Learning at Scale01:05:56 The Evolution of Bayesian Inference Packages01:10:39 Vision for the Future of Bayesian StatisticsThank you to my Patrons for making this episode possible!Come meet Alex at the Field of Play Conference in Manchester, UK, March 27, 2026!Links from the show:David Rügamer:* Website* Google Scholar* GitHubEmanuel Sommer:* Website* GitHub* Google ScholarJakob Robnik:* Google Scholar* GitHub* Microcanonical Langevin paper* LinkedIn | — | ||||||
| 1/21/26 |  BITESIZE | Building Resilience in Modern Tech Careers | Today’s clip is from episode 149 of the podcast, with Alana Karen.This conversation explores the evolving landscape of technology, particularly in Silicon Valley, focusing on the cultural shifts due to mass layoffs, the debate over remote work, and the impact of AI on job roles and priorities. The discussion highlights the importance of adapting to these changes and preparing for the future by developing complex skills that AI cannot easily replicate.Get the full discussion here!• Join this channel to get access to perks:https://www.patreon.com/c/learnbayesstats• Intro to Bayes Course (first 2 lessons free): https://topmate.io/alex_andorra/503302• Advanced Regression Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 1/14/26 |  #149 The Future of Work in Tech, with Alana Karen | • Support & get perks!• Proudly sponsored by PyMC Labs!• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:11:37 The Hard Tech Era21:08 The Shift in Tech Work Culture28:49 AI's Impact on Job Security and Work Dynamics34:33 Adapting to AI: Skills for the Future45:56 Understanding AI Models and Their Limitations47:25 The Importance of Diversity in AI Development54:34 Positioning Technical Talent for Job Security57:58 Building Resilience in Uncertain Times01:06:33 Recognizing Diverse Ambitions in Career Progression01:12:51 The Role of Managers in Employee Retention01:26:55 Solving Complex Problems with AI and InnovationThank you to my Patrons for making this episode possible!Links from the show:Alana's latest book (Use code BAYESIAN for 10% off + a free interview preparation download PDF)Alana’s SubstackAlana on LinkedinAlana on InstagramThe Obstacle Is the Way – The Timeless Art of Turning Trials into TriumphCourage Is Calling – Fortune Favours the Brave | — | ||||||
| 1/7/26 |  BITESIZE | The Trial Design That Learns in Real Time | Today’s clip is from episode 148 of the podcast, with Scott Berry. In this conversation, Alex and Scott discuss emphasizing the shift from frequentist to Bayesian approaches in clinical trials. They highlight the limitations of traditional trial designs and the advantages of adaptive and platform trials, particularly in the context of COVID-19 treatment. The discussion provides insights into the complexities of trial design and the innovative methodologies that are shaping the future of medical research. Get the full discussion here!• Join this channel to get access to perks: https://www.patreon.com/c/learnbayesstats • Intro to Bayes Course (first 2 lessons free): https://topmate.io/alex_andorra/503302 • Advanced Regression Course (first 2 lessons free): https://topmate.io/alex_andorra/1011122 Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ ! | — | ||||||
| 12/30/25 |  #148 Adaptive Trials, Bayesian Thinking, and Learning from Data, with Scott Berry | • Support & get perks!• Proudly sponsored by PyMC Labs. Get in touch and tell them you come from LBS!• Intro to Bayes and Advanced Regression courses (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work !Chapters:13:16 Understanding Adaptive and Platform Trials25:25 Real-World Applications and Innovations in Trials34:11 Challenges in Implementing Bayesian Adaptive Trials42:09 The Birth of a Simulation Tool44:10 The Importance of Simulated Data48:36 Lessons from High-Stakes Trials52:53 Navigating Adaptive Trial Designs56:55 Communicating Complexity to Stakeholders01:02:29 The Future of Clinical Trials01:10:24 Skills for the Next Generation of StatisticiansThank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Giuliano Cruz, Tradd Salvo, William Benton, James Ahloy, Robin Taylor,, Chad Scherrer, Zwelithini Tunyiswa, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Ian Moran, Paul Oreto, Colin Caprani, Colin Carroll, Nathaniel Burbank, Michael Osthege, Rémi Louf, Clive Edelsten, Henri Wallen, Hugo Botha, Vinh Nguyen, Marcin Elantkowski, Adam C. Smith, Will Kurt, Andrew Moskowitz, Hector Munoz, Marco Gorelli, Simon Kessell, Bradley Rode, Patrick Kelley, Rick Anderson, Casper de Bruin, Michael Hankin, Cameron Smith, Tomáš Frýda, Ryan Wesslen, Andreas Netti, Riley King, Yoshiyuki Hamajima, Sven De Maeyer, Michael DeCrescenzo, Fergal M, Mason Yahr, Naoya Kanai, Aubrey Clayton, Omri Har Shemesh, Scott Anthony Robson, Robert Yolken, Or Duek, Pavel Dusek, Paul Cox, Andreas Kröpelin, Raphaël R, Nicolas Rode, Gabriel Stechschulte, Arkady, Kurt TeKolste, Marcus Nölke, Maggi Mackintosh, Grant Pezzolesi, Joshua Meehl, Javier Sabio, Kristian Higgins, Matt Rosinski, Luis Fonseca, Dante Gates, Matt Niccolls, Maksim Kuznecov, Michael Thomas, Luke Gorrie, Cory Kiser, Julio, Edvin Saveljev, Frederick Ayala, Jeffrey Powell, Gal Kampel, Adan Romero, Blake Walters, Jonathan Morgan, Francesco Madrisotti, Ivy Huang, Gary Clarke, Robert Flannery, Rasmus Hindström, Stefan, Corey Abshire, Mike Loncaric, Ronald Legere, Sergio Dolia, Michael Cao, Yiğit Aşık, Suyog Chandramouli, Guillaume Berthon, Avenicio Baca, Spencer Boucher, Krzysztof Lechowski, Danimal, Jácint Juhász, Sander and Philippe.Links from the show:Berry ConsultantsScott's podcastLBS #45 Biostats & Clinical Trial Design, with Frank Harrell | — | ||||||
| 11/12/25 |  #145 Career Advice in the Age of AI, with Jordan Thibodeau | Proudly sponsored by PyMC Labs, the Bayesian Consultancy. Book a call, or get in touch!Intro to Bayes Course (first 2 lessons free)Advanced Regression Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work!Visit our Patreon page to unlock exclusive Bayesian swag ;)Thank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Giuliano Cruz, James Wade, Tradd Salvo, William Benton, James Ahloy, Robin Taylor, Chad Scherrer, Zwelithini Tunyiswa, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Ian Moran, Paul Oreto, Colin Caprani, Colin Carroll, Nathaniel Burbank, Michael Osthege, Rémi Louf, Clive Edelsten, Henri Wallen, Hugo Botha, Vinh Nguyen, Marcin Elantkowski, Adam C. Smith, Will Kurt, Andrew Moskowitz, Hector Munoz, Marco Gorelli, Simon Kessell, Bradley Rode, Patrick Kelley, Rick Anderson, Casper de Bruin, Michael Hankin, Cameron Smith, Tomáš Frýda, Ryan Wesslen, Andreas Netti, Riley King, Yoshiyuki Hamajima, Sven De Maeyer, Michael DeCrescenzo, Fergal M, Mason Yahr, Naoya Kanai, Aubrey Clayton, Omri Har Shemesh, Scott Anthony Robson, Robert Yolken, Or Duek, Pavel Dusek, Paul Cox, Andreas Kröpelin, Raphaël R, Nicolas Rode, Gabriel Stechschulte, Arkady, Kurt TeKolste, Marcus Nölke, Maggi Mackintosh, Grant Pezzolesi, Joshua Meehl, Javier Sabio, Kristian Higgins, Matt Rosinski, Luis Fonseca, Dante Gates, Matt Niccolls, Maksim Kuznecov, Michael Thomas, Luke Gorrie, Cory Kiser, Julio, Edvin Saveljev, Frederick Ayala, Jeffrey Powell, Gal Kampel, Adan Romero, Will Geary, Blake Walters, Jonathan Morgan, Francesco Madrisotti, Ivy Huang, Gary Clarke, Robert Flannery, Rasmus Hindström, Stefan, Corey Abshire, Mike Loncaric, David McCormick, Ronald Legere, Sergio Dolia, Michael Cao, Yiğit Aşık, Suyog Chandramouli and Guillaume Berthon.Takeaways:AI is reshaping the workplace, but we're still in early stages.Networking is crucial for job applications in top firms.AI tools can augment work but are not replacements for skilled labor.Understanding the tech landscape requires continuous learning.Timing and cultural readiness are key for tech innovations.Expertise can be gained without formal education.Bayesian statistics is a valuable skill for tech professionals.The importance of personal branding in the job market. You just need to know 1% more than the person you're talking to.Sharing knowledge can elevate your status within a company.Embracing chaos in tech can create new opportunities.Investing in people leads... | — | ||||||
| 10/30/25 |  #144 Why is Bayesian Deep Learning so Powerful, with Maurizio Filippone | Sign up for Alex's first live cohort, about Hierarchical Model building!Get 25% off "Building AI Applications for Data Scientists and Software Engineers"Proudly sponsored by PyMC Labs, the Bayesian Consultancy. Book a call, or get in touch!Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work!Visit our Patreon page to unlock exclusive Bayesian swag ;)Takeaways:Why GPs still matter: Gaussian Processes remain a go-to for function estimation, active learning, and experimental design – especially when calibrated uncertainty is non-negotiable.Scaling GP inference: Variational methods with inducing points (as in GPflow) make GPs practical on larger datasets without throwing away principled Bayes.MCMC in practice: Clever parameterizations and gradient-based samplers tighten mixing and efficiency; use MCMC when you need gold-standard posteriors.Bayesian deep learning, pragmatically: Stochastic-gradient training and approximate posteriors bring Bayesian ideas to neural networks at scale.Uncertainty that ships: Monte Carlo dropout and related tricks provide fast, usable uncertainty – even if they’re approximations.Model complexity ≠ model quality: Understanding capacity, priors, and inductive bias is key to getting trustworthy predictions.Deep Gaussian Processes: Layered GPs offer flexibility for complex functions, with clear trade-offs in interpretability and compute.Generative models through a Bayesian lens: GANs and friends benefit from explicit priors and uncertainty – useful for safety and downstream decisions.Tooling that matters: Frameworks like GPflow lower the friction from idea to implementation, encouraging reproducible, well-tested modeling.Where we’re headed: The future of ML is uncertainty-aware by default – integrating UQ tightly into optimization, design, and deployment.Chapters:08:44 Function Estimation and Bayesian Deep Learning10:41 Understanding Deep Gaussian Processes25:17 Choosing Between Deep GPs and Neural Networks32:01 Interpretability and Practical Tools for GPs43:52 Variational Methods in Gaussian Processes54:44 Deep Neural Networks and Bayesian Inference01:06:13 The Future of Bayesian Deep Learning01:12:28 Advice for Aspiring Researchers | — | ||||||
| 7/23/25 |  #137 Causal AI & Generative Models, with Robert Ness | Proudly sponsored by PyMC Labs, the Bayesian Consultancy. Book a call, or get in touch!Intro to Bayes Course (first 2 lessons free)Advanced Regression Course (first 2 lessons free)Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work!Visit our Patreon page to unlock exclusive Bayesian swag ;)Takeaways:Causal assumptions are crucial for statistical modeling.Deep learning can be integrated with causal models.Statistical rigor is essential in evaluating LLMs.Causal representation learning is a growing field.Inductive biases in AI should match key mechanisms.Causal AI can improve decision-making processes.The future of AI lies in understanding causal relationships.Chapters:00:00 Introduction to Causal AI and Its Importance16:34 The Journey to Writing Causal AI28:05 Integrating Graphical Causality with Deep Learning40:10 The Evolution of Probabilistic Machine Learning44:34 Practical Applications of Causal AI with LLMs49:48 Exploring Multimodal Models and Causality56:15 Tools and Frameworks for Causal AI01:03:19 Statistical Rigor in Evaluating LLMs01:12:22 Causal Thinking in Real-World Deployments01:19:52 Trade-offs in Generative Causal Models01:25:14 Future of Causal Generative ModelingThank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Ero Carrera, Giuliano Cruz, James Wade, Tradd Salvo, William Benton, James Ahloy, Robin Taylor,, Chad Scherrer, Zwelithini Tunyiswa, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Ian Moran, Paul Oreto, Colin Caprani, Colin Carroll, Nathaniel Burbank, Michael Osthege, Rémi Louf, Clive Edelsten, Henri Wallen, Hugo Botha, Vinh Nguyen, Marcin Elantkowski, Adam C. Smith, Will Kurt, Andrew Moskowitz, Hector Munoz, Marco Gorelli, Simon Kessell, Bradley Rode, Patrick Kelley, Rick Anderson, Casper de Bruin, Philippe Labonde, Michael Hankin, Cameron Smith, Tomáš Frýda, Ryan Wesslen, Andreas Netti, Riley King, Yoshiyuki Hamajima, Sven De Maeyer, Michael DeCrescenzo, Fergal M, Mason Yahr, Naoya Kanai, Aubrey Clayton, Jeannine Sue, Omri Har Shemesh, Scott Anthony Robson, Robert Yolken, Or Duek, Pavel Dusek, Paul Cox, Andreas Kröpelin, Raphaël R, Nicolas Rode, Gabriel Stechschulte, Arkady, Kurt TeKolste, Marcus Nölke, Maggi Mackintosh, Grant... | — | ||||||
| 2/25/21 |  #34 Multilevel Regression, Post-stratification & Missing Data, with Lauren Kennedy | Episode sponsored by Tidelift: tidelift.comWe already mentioned multilevel regression and post-stratification (MRP, or Mister P) on this podcast, but we didn’t dedicate a full episode to explaining how it works, why it’s useful to deal with non-representative data, and what its limits are. Well, let’s do that now, shall we?To that end, I had the delight to talk with Lauren Kennedy! Lauren is a lecturer in Business Analytics at Monash University in Melbourne, Australia, where she develops new statistical methods to analyze social science data. Working mainly with R and Stan, Lauren studies non-representative data, multilevel modeling, post-stratification, causal inference, and, more generally, how to make inferences from the social sciences.Needless to say that I asked her everything I could about MRP, including how to choose priors, why her recent paper about structured priors can improve MRP, and when MRP is not useful. We also talked about missing data imputation, and how all these methods relate to causal inference in the social sciences.If you want a bit of background, Lauren did her Undergraduates in Psychological Sciences and Maths and Computer Sciences at Adelaide University, with Danielle Navarro and Andrew Perfors, and then did her PhD with the same advisors. She spent 3 years in NYC with Andrew Gelman’s Lab at Columbia University, and then moved back to Melbourne in 2020. Most importantly, Lauren is an adept of crochet — she’s already on her third blanket!Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ !Thank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Ero Carrera, Brian Huey, Giuliano Cruz, Tim Gasser, James Wade, Tradd Salvo, Adam Bartonicek, William Benton, Alan O'Donnell, Mark Ormsby, Demetri Pananos, James Ahloy, Jon Berezowski, Robin Taylor, Thomas Wiecki, Chad Scherrer, Vincent Arel-Bundock, Nathaniel Neitzke, Zwelithini Tunyiswa, Elea McDonnell Feit, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Joshua Duncan, Ian Moran, Paul Oreto, Colin Caprani, George Ho, Colin Carroll, Nathaniel Burbank, Michael Osthege and Rémi Louf.Visit https://www.patreon.com/learnbayesstats to unlock exclusive Bayesian swag ;)Links from the show:Lauren's website: https://jazzystats.com/Lauren on Twitter: https://twitter.com/jazzystatsLauren on GitHub: https://github.com/lauken13Improving multilevel regression and poststratification with structured priors: https://arxiv.org/abs/1908.06716Using model-based regression and poststratification to generalize findings beyond the observed sample: https://arxiv.org/abs/1906.11323Lauren's beginners Bayes workshop: https://github.com/lauken13/Beginners_Bayes_WorkshopMRP in RStanarm: | — | ||||||
| 11/20/20 |  #28 Game Theory, Industrial Organization & Policy Design, with Shosh Vasserman | In times of crisis, designing an efficient policy response is paramount. In case of natural disasters or pandemics, it can even determine the difference between life and death for a substantial number of people. But precisely, how do you design such policy responses, making sure that risks are optimally shared, people feel safe enough to reveal necessary information, and stakeholders commit to the policies?That’s where a field of economics, industrial organization (IO), can help, as Shosh Vasserman will tell us in this episode. Shosh is an assistant professor of economics at the Stanford Graduate School of Business. Specialized in industrial organization, her interests span a number of policy settings, such as public procurement, pharmaceutical pricing and auto-insurance.Her work leverages theory, empirics and modern computation (including the Stan software!) to better understand the equilibrium implications of policies and proposals involving information revelation, risk sharing and commitment. In short, Shoshana uses theory and data to study how risk, commitment and information flows interplay with policy design. And she does a lot of this with… Bayesian models! Who said Bayes had no place in economics?Prior to Stanford, Shoshana did her Bachelor’s in mathematics and economics at MIT, and then her PhD in economics at Harvard University.This was a fascinating conversation where I learned a lot about Bayesian inference on large scale random utility logit models, socioeconomic network heterogeneity and pandemic policy response — and I’m sure you will too!Our theme music is « Good Bayesian », by Baba Brinkman (feat MC Lars and Mega Ran). Check out his awesome work at https://bababrinkman.com/ !Thank you to my Patrons for making this episode possible!Yusuke Saito, Avi Bryant, Ero Carrera, Brian Huey, Giuliano Cruz, Tim Gasser, James Wade, Tradd Salvo, Adam Bartonicek, William Benton, Alan O'Donnell, Mark Ormsby, Demetri Pananos, James Ahloy, Jon Berezowski, Robin Taylor, Thomas Wiecki, Chad Scherrer, Vincent Arel-Bundock, Nathaniel Neitzke, Zwelithini Tunyiswa, Elea McDonnell Feit, Bertrand Wilden, James Thompson, Stephen Oates, Gian Luca Di Tanna, Jack Wells, Matthew Maldonado, Ian Costley, Ally Salim, Larry Gill, Joshua Duncan, Ian Moran and Paul Oreto.Visit https://www.patreon.com/learnbayesstats to unlock exclusive Bayesian swag ;)Links from the show:Shosh's website: https://shoshanavasserman.com/Shosh on Twitter: https://twitter.com/shoshievassHow do different reopening strategies balance health and employment: https://reopenmappingproject.com/Aggregate random coefficients logit—a generative approach: http://modernstatisticalworkflow.blogspot.com/2017/03/aggregate-random-coefficients-logita.htmlVoluntary Disclosure and Personalized Pricing: https://shoshanavasserman.com/files/2020/08/Voluntary-Disclosure-and-Personalized-Pricing.pdfSocioeconomic Network Heterogeneity and Pandemic Policy Response: | — | ||||||
Showing 25 of 202
Sponsor Intelligence
Sign in to see which brands sponsor this podcast, their ad offers, and promo codes.
Chart Positions
6 placements across 6 markets.
Chart Positions
6 placements across 6 markets.