
ThursdAI - The top AI news from the past week
by From Weights & Biases, Join AI Evangelist Alex Volkov and a panel of experts to cover everything important that happened in the world of AI from the past week
Is this your podcast?Insights from recent episode analysis
Audience Interest
Podcast Focus
Publishing Consistency
Platform Reach
Insights are generated by CastFox AI using publicly available data, episode content, and proprietary models.
Most discussed topics
Brands & references
Total monthly reach
Estimated from 26 chart positions in 26 markets.
By chart position
- 🇺🇸US · Tech News#7730K to 100K
- 🇦🇺AU · Tech News#1125K to 30K
- 🇨🇦CA · Tech News#1285K to 30K
- 🇬🇧GB · Tech News#1755K to 30K
- 🇩🇪DE · Tech News#2005K to 30K
- Per-Episode Audience
Est. listeners per new episode within ~30 days
42K to 161K🎙 Daily cadence·152 episodes·Last published 6d ago - Monthly Reach
Unique listeners across all episodes (30 days)
140K to 536K🇺🇸19%🇦🇺6%🇨🇦6%+23 more - Active Followers
Loyal subscribers who consistently listen
56K to 214K
Market Insights
Platform Distribution
Reach across major podcast platforms, updated hourly
Total Followers
—
Total Plays
—
Total Reviews
—
* Data sourced directly from platform APIs and aggregated hourly across all major podcast directories.
On the show
From 17 epsHost
Recent guests
Recent episodes
Fable Got Banned, Open Source Delivered: GLM-5.2, Kimi K2.7 & SpaceX Buys Cursor - June 18
Jun 18, 2026
1h 55m 46s
📅 ThursdAI - Jun 11, 2026 - Fable & Mythos 5 are here, Anthropic gets caught sandbagging (then reverses), Siri AI finally works!? and we got live-translated on air
Jun 12, 2026
2h 11m 08s
📅 ThursdAI - Jun 4 - NVIDIA drops Nemotron 3 Ultra (550B open), Microsoft becomes a frontier lab, Ideogram 4 goes open, Agent Arena & more
Jun 5, 2026
1h 43m 49s
📅 May 28 - Opus 4.8 ships mid-show, the Pope writes 42K words on AI, 11labs dubs the world and DeepSwe breaks coding evals
May 29, 2026
1h 39m 11s
AI just cracked an 80-year-old math problem nobody could solve — plus everything from Google I/O 26
May 22, 2026
1h 49m 18s
Social Links & Contact
Official channels & resources
Official Website
Login
RSS Feed
Login
| Date | Episode | Topics | Guests | Brands | Places | Keywords | Sponsor | Length | |
|---|---|---|---|---|---|---|---|---|---|
| 6/18/26 |  Fable Got Banned, Open Source Delivered: GLM-5.2, Kimi K2.7 & SpaceX Buys Cursor - June 18 | Hey yall, Alex here, let me catch you up! I came back from vacation expecting to cover Fable 5 after a week of using it. The first two days after we all first got access to a Mythos level model were super exciting! But then the news hit, US Government issued an order banning Anthropic from giving access to Fable 5 and Mythos 5 to any foreign national, causing Anthropic to pull the models completely (even internally to their employees!). So, this wasn’t the show I planned, but it turned into a great show about Open Source, as two models hit the top rankings and are both MIT licence, filling a Fable shaped hole in our hearts!GLM released 5.2 with folks really excited about it web building capabilities, and Kimi 2.7 Code released (and is available on CW Inference with crazy speeds!). We also saw the SpaceX IPO and Cursor $60B acquisition, Noam Shazeer joining Open and Midjourney, the image company, launching a new Ultrasound full body scanner to kill MRIs! Great show today with Dexter Horthy from HumanLayer, Chris Van Pelt and Adrian Swanberg from W&B announcing our new product HiveMind and Tanishq Abraham came back to help cover Midjourney’s new Ultrasound scanner! Let’s dive in!ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.The US Government bans Fable 5! (X, Anthropic statement)Here’s a story in 3 parts: * Anthropic announces Mythos 5 preview - saying that this model is to dangerous to release, and only gives corporations access to it via project GlassWing. * Anthropic works hard on limitations and safery and releases Fable 5 (same weights as Mythos 5) built with guardrails so strong it refuses to do any cybersecurity tasks and switches back to Opus frequently* US Government receives a tip (reportedly from Amazon) that Fable 5 can be jailbroken to do cybersecurity tasks, and issues an order to Anthropic, citing national security concerns, banning them from giving access to Fable 5 and Mythos 5 to any foreign national, causing Anthropic to pull the models completely (even internally to their employees!)This is the first time that we see the US Government directly intervene in the AI space and restrict access to frontier models. The most updated reporting on this I could find is that Anthropic and US Government officials are in the process of negotiating a safe release framework. Given that preventing all jailbreaks is impossible, I hope they will land on a solution that gives me Fable 5 back!This hit especially hard because last week we were all high on Fable. Not in the usual AI Twitter benchmark sense, in the actual “oh, this is a different level” sense. Me and my wife Fable maxxed throughout our flight to Vacation. Peter had saved outputs he kept going back to because other models suddenly felt like a step down. Dexter later said it was the closest he had felt in a while to the old “I need to keep prompting this thing overnight” feeling.Peter Gostev made a point that stuck with me. It’s easy for us in the bubble to call this ridiculous, and on the technical merits it kind of is. But if you’ve spent weeks telling normal people “this thing is like a nuclear weapon, it’ll take everyone’s jobs,” and then someone asks “okay, can you make it safe?” and the answer is “no, I can’t,” then you can see how an outsider lands on “well, maybe you shouldn’t have it.” His takeaway, and I agree: we need to be way more careful with the imagery we use, because the nuclear-weapon framing came home to roost.The bigger questions are the scary ones. Wolfram framed it as a sovereign AI wake-up call, and he’s right. For the first time we’re seeing a real gap in intelligence available to people based on their nationality. Imagine building a company on a model that an outside government can switch off with one letter. Peter pointed out it’s commercially bad for the US but completely disastrous for Europe, which has basically one frontier lab and a pile of startups that suddenly look very exposed. And there’s the obvious irony Nisten enjoyed a little too much: the Europeans who spent years lecturing everyone about AI restrictions just got restrictions imposed on them.If anyone in the government is listening: we want Fable back, please.SpaceX IPOs and acquires Cursor for $60B (X)SpaceX went and did the largest IPO in the history of the world, around seventy-five billion dollars, which on a roughly two-trillion-dollar valuation made Elon the first trillionaire. (Did anything materially change for him? No. He can still fly his private plane. There’s nothing left to buy.) Three days later, SpaceX exercised its option and bought Cursor (Anysphere) for sixty billion dollars in an all-stock deal, paid in shares minted at the IPO and now trading around $211. The four Cursor co-founders are all billionaires now. Largest software acquisition ever, and for SpaceX it’s barely a blip on the radar.Why are we covering a stock-market story? Because it’s not really a coding-tools story, it’s an AI story. Cursor gave away its IDE to a lot of people while collecting their data, then quietly became a training company with Composer. SpaceX/xAI was always strong on compute and weak on code, and the missing ingredient was exactly that kind of data. Now Composer 2.5 is already showing up rebranded inside the xAI stack, and if you pay for X Premium you can use it. Composer 3, trained on the Memphis supercluster, is reportedly coming very soon and is going to hit hard.Nisten’s take was the spicy one. For the data alone it’s worth it, because xAI now has insight into how essentially every enterprise that touched Cursor operates. And he had zero sympathy for the companies that assumed “no data retention for training” meant the data was actually gone. We see in legal cases all the time that deleted data is still there. His view: it should have gone open source.Cursor has over a million paying customers, $2.6 billion in revenue, projected to hit $6 to $10 billion by end of 2026. But here’s the thing that matters for us, the AI coding angle. Cursor was one of Anthropic’s biggest revenue pipelines because Composer runs on Claude under the hood. That pipeline is now owned by xAI. They’re already jointly training Grok 4.3, a 1.5 trillion parameter model, with Cursor’s proprietary coding data injected directly into pre-training, not fine-tuning. Pre-training. That’s a fundamentally different thing. Composer 2.5 was already Pareto dominant on coding benchmarks before the deal closed. Now pair that with Colossus, the biggest GPU cluster in the world.Will this be enough to put XAI (now SpaceXAI) at the frontline of the AI race? Will Grok 5 be Fable level code? We’ll find out. Either way, this is the most consequential AI acquisition we’ve seen. Period.Open Source AI GLM-5.2 takes the open source crown (X, Blog, HF, Docs)Z.ai dropped GLM-5.2 and it’s now the strongest open source model for coding and long-horizon work. The headline number: 74.4% on FrontierSWE, which measures whether an agent can finish full engineering projects over hours. That trails Opus 4.8 by about one point and beats GPT-5.5. On Terminal-Bench 2.1 it jumps to 81% from GLM-5.1’s 63.5%, which is a big leap. It’s a 753B parameter MoE, MIT licensed, no regional restrictions, weights on HuggingFace. The 1M context window is real and usable, backed by a clever IndexShare technique that cuts per-token FLOPs by about 2.9x at full context. People are reporting roughly 8x cost savings versus Opus 4.8 for comparable quality on real coding tasks.The most interesting thing on the show was that this was a confusing release, in a good way. Peter put it well: normally a catching-up lab ships cherry-picked benchmarks and then independent testing deflates them. Here it’s the opposite, almost every benchmark holds up, even crossing above Fable at certain points, and yet when he actually used it over a couple of days he wasn’t blown away. His verdict, and I think it’s the calibration we needed: this is clearly an amazing model, and the fact that it’s open and you can run it is incredible, but it is nowhere near Fable, and it would frankly be implausible if a 700-odd-billion-parameter model matched a model that’s rumored to be in the trillions. Though, I think the comparison to Fable is really really unfair, and the comments online seem to suggest that 5.2 from GLM is a banger model. Just looking at this Harvey benchmark on legal tasks from Vals, a benchmark that there’s 0 chance Z.ai folks have seen! GLM 5.2 scores #3 on this benchmark! Just after Fable and Opus, and per TeorTaxes on X, previous GLM 5.1 scored an absolute 0% on this one! Where it genuinely shines is design. On Design Arena, which is a head-to-head ELO vote, people have been picking GLM-5.2’s website designs over Fable’s by a real margin (around 1360 to 1350). LDJ’s framing is the one I buy: specialization is becoming valuable again, and GLM is clearly leaning into front-end design and taste. Wolfram added the necessary asterisk, every benchmark only tells you the model did well on that specific test, so “as good as Fable” should always carry the “on this benchmark, with these tasks” disclaimer. Fair. I’d just say this: I don’t want to compare everything to Fable, because we can’t even use Fable anymore. Compared to the models we can actually touch, GLM-5.2 is a fantastic deal.Kimi K2.7 Code from Moonshot (X, HF, Announcement)The other big drop. Kimi is the darling of open source while we wait on DeepSeek, and Moonshot shipped K2.7 Code, a 1 trillion parameter MoE built specifically for coding, available through Kimi Code and the API, with a modified MIT license. The standout for me isn’t a single benchmark, it’s efficiency: roughly 30% fewer reasoning tokens than K2.6, which matters enormously when you’re running long agentic loops that burn tokens like crazy. Benchmark jumps over K2.6 are real (+21.8% on their Code Bench v2, +11% on Program Bench), though Peter and Wolfram both noticed something odd, on a few benchmarks including their Agentic Arena, the older K2.6 actually edged out K2.7. The likely explanation is that K2.7 is narrowly trained for code with reduced reasoning, so it may trade away some general capability. Moonshot themselves recommend K2.6 for general non-coding tasks. Also worth knowing: it’s not multimodal, no vision, which is a real gap for coding these days. And thinking-off isn’t supported, it’s reasoning-on by default.The model is available on our CW Inference, with the fastest token streaming in the industry, over 280 tok/s (Announcement, try it), with very decent pricing $0.94 - $0.19 - $4.00 (input - cached - output) per million tokens. This Week’s Buzz: W&B launched HiveMind 🐝 - track all your agentic work in one place (X, Try it, GitHub)This is the one I’ve been sitting on for months. We brought on Chris Van Pelt (CVP), Weights & Biases co-founder, and Adrian Swanberg to launch HiveMind, and I’ll be honest, I’ve been a beta user for a while and I’m thrilled I can finally talk about it.The premise: what it means to be a software developer has fundamentally changed, and your work is now scattered across six or seven agent dashboards. HiveMind is a tiny daemon that sits on your machine, picks up sessions from whatever harness you’re running (Claude Code, Codex, Cursor, Gemini CLI, OpenCode, GitHub Copilot, Pi), and within about 30 seconds they show up in one shared dashboard. It breaks each session into chapters, shows which files the agent touched, what to-dos it wrote, where context got compacted. W&B has been running it internally for six months.A few things genuinely delighted me. There’s a fork button: HiveMind pulls down a compacted history of a session and lets you relaunch it in a different harness, so you stay harness-agnostic. CVP’s line: “this has proven invaluable when Anthropic servers are on fire and I just gotta get something done.” Then there’s the skill engine, which to me is the real magic. It reads your team’s sessions and can clone a power user’s whole approach into a reusable persona, at CoreWeave they built a “Talk to Tim” skill from Tim Sweeney’s sessions, and apparently a virtual Tim is now a popular way to get guidance. And the insights feature detects where you kept correcting the agent, clusters those pitfalls across the org, and hands you a smart-merge command to drop the fix straight into your AGENTS.md.I’m excited to finally show this to you, it’s been genuinely helpful (for example, last week I was able to test Fable and tell you the number of tokens it used until i maxxed out my Claude Subscription!) - give it a try at hivemind.wandb.tools HumanLayer launches its Agentic IDE, and a real talk about code slop (X, humanlayer.dev, 12-factor-agents)Dexter Horthy, friend of the show and the team behind 12 Factor Agents and the Research-Plan-Implement framework (now running inside Block and Uber), launched HumanLayer’s Agentic IDE this week, and we got into one of my favorite conversations of the year. The whole product is explicitly anti-slop. His argument: the “lights-off loop,” where humans only write tickets and the agent codes, verifies, ships, and feeds its own crashes back to itself, is the fastest way to trash a codebase. Vibe coding is great for zero-to-one and side projects nobody depends on. But if you’re a staff engineer in a high-stakes codebase, dear God, read the code.This ties directly into my AI Engineer World’s Fair talk, the ZL continuum, which Dexter half-inspired. On one end you’ve got the YOLO camp (Ryan from OpenAI, one billion tokens a day, nobody can read that much code) and on the other Mario from PI (read every line of critical code). Those two are now the sixth and seventh most-watched AI Engineer talks globally, which tells you the whole field is wrestling with this. Dexter’s answer is leverage. Don’t aim for a perfect spec, because a perfect spec is just code. Get it 80% right, then zoom down a level at a time so the chunk you’re steering is human-consumable. He claims that an hour of upfront prep on architecture and even program design turns a three-hour code review into a twenty-minute one.I pushed him on the obvious counter: why does code quality even matter if Fable-class models keep arriving and maintenance is a prompt away? His answer was the most grounded thing I heard all week. Code quality matters for the same reason it mattered in the 1970s software crisis: pile in code without structure and your velocity tanks, every change starts breaking something else. And here’s the irony, we train models on beautifully architected projects (Django, Redis, Spring on SWE-bench multilingual), yet they still reward-hack their way to “just make the test pass.” We don’t yet have a penalty function or a verifier for “this code is harder to maintain,” and that’s hard to build, so humans are still needed in the loop. He played with Fable too, threw an 8K-line React PR refactor at it, and the first pass was bad, it introduced React context and patterns they don’t use. Better than before, not a step change that lets you drop the reins. We’re not there yet. It’s BYOK, $100/user/month for pro with a free tier for teams of three.OpenRouter Fusion: near-Fable quality at half the price (X, Blog, Announcement)Wolfram spotted this one and it’s clever. OpenRouter’s Fusion is a single API call that fans your prompt out to a panel of models, then a judge model reads all the responses and a synthesizer writes the best combined answer. It’s the LLM consortium idea (the thing we used to do by hand, asking several models and stitching the best parts together), now baked into the API so you don’t build it yourself. The wild result: on Perplexity’s DRACO deep-research benchmark, a budget panel beats solo GPT-5.5 and solo Opus 4.8 and lands within 1% of Fable 5 at roughly half the cost. The most interesting finding is that about three quarters of the lift comes from the synthesis step, not from model diversity, they even fused Opus with itself and got a 6.7-point jump. The catch is latency, it’s 2-3x slower, so it’s a deep-research and planning tool, not a quick-query tool. Big shout out to OpenRouter.Vision and videoGoogle Gemini Omni, finally with API access, takes #1 on video benchmarks (X, Announcement)We covered Google’s new video model Omni at Google I/O, and it finally landed as an API. It’s Google’s first any-to-any model, one single unified system for text, image, video, audio, and music. Think Nano Banana, but for video. Peter tested it and it scored really, really well, the kind of jump between generations you saw with GPT-image-2. Independent testing put it at #1 for realistic body physics and #2 behind Seedance for complex action, and it topped MovieGenBench for preference and instruction following. The session-memory piece is the part I find most useful: you can keep editing across turns, characters stay consistent, you say “continue” and it picks up where it left off. It’s live in the Gemini app, Google Flow, and YouTube ShortsGrok Imagine Video 1.5 (X, Blog, Docs)xAI’s Grok video work has been quietly getting really good, and they finally gave us an actual version number instead of silently updating “Grok Imagine” over and over (which drove me nuts). Grok Imagine Video 1.5 generates a 6-second 720p clip in about 25 seconds, down from 40-plus, so nearly 2x faster, with native audio generated in the same pass: sound effects, ambience, dialogue, lip sync, no post-production stitching. It hit #1 on the Design Arena image-to-video board with a 1,357 Elo and a ~49 point lead, and it’s generally available in the API. I ran my standard astronaut-riding-a-horse-on-the-moon prompt and it came back with music too. Genuinely cool.Sci-Fi is here: Midjourney announces a full-body ultrasound scanner to compete with MRIs (X, Announcement)I’m still processing this one. Midjourney, you know, the image generation company, announced medical hardware. A new division called Midjourney Medical, and its first product is a full-body ultrasonic scanner. Tanishq Abraham was there in the front row and joined us to break it down.The device uses thousands of ultrasonic transducers arranged in a ring. Because sound doesn’t propagate well through air, you’re lowered into a tank of water, the sound travels through your body at 1,481 meters per second, and in under 60 seconds you get a 3D anatomical map of 25-plus organs. The raw data is roughly 806 terabytes per scan, streaming at about 16-17 gigabytes per second, and the only way to handle that firehose is AI. No radiation, no magnets, no superconductors, which is what makes MRI so expensive. David Holz has apparently wanted a medical imaging lab for two years, and because Midjourney is fully self-funded with no VCs, they can chase wild projects like this.The fun reveal from Tanishq: there’s no AI in the actual image reconstruction yet, it’s basic signal processing right now, with physics simulators and possibly NeRF-style neural fields on the roadmap (there was a hallway conversation with John Barron about exactly that). So this is a prototype with enormous headroom. The business model is the spa, a 24,000-square-foot space about ten minutes from Union Square in SF with around ten scanners, targeting end of 2027, then custom sensors in 2028, scaling toward 50,000 scanners doing a billion scans a month. Now, for a dose of reality, this is just an announcement, and ultrasound won’t replace MRIs anytime soon. For one, ultrasound cannot penetrate bone and air, so lungs (full of air) and brain (literally encased in bone) are out, but it’s still great ot see Dave Holz innovating in the medical space and I’m excited to try this out! Wrapping upWhat a strange, whiplash week. We got the best model any of us had ever used taken away by a government letter, watched a meme become a real Mistral roadmap, saw open source close the gap on the models we can actually run, and watched an image company casually announce it might kill the MRI. I came back from vacation thinking I’d write you a Fable love letter and instead I’m writing about deemed-export law and ultrasonic water tanks. That’s the job, and honestly I wouldn’t trade it.If you’re heading to AI Engineer World’s Fair, come find Wolfram and me, Weights & Biases and CoreWeave are sponsoring the whole thing, and my ZL continuum talk will name-check a lot of what we covered today (Day 3 • Wed, July 1 · 10:45am-11:05am) . And if Fable comes back next week, you’ll hear me yell about it first.See you next week, and please, US government, give us Fable back.ThursdAI - Jun 18, 2026 - TL;DR* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases, CoreWeave (@altryne)* Co-Hosts - @WolframRvnwlf, @ldjconfirmed, @petergostev (Arena), @nisten, @yampeleg* Dexter Horthy (@dexhorthy) - Founder, HumanLayer* Chris Van Pelt (@vanpelt) - Co-founder, Weights & Biases (HiveMind)* Adrian Swanberg - Weights & Biases (HiveMind)* Tanishq Abraham (@iScienceLuvr) - Founder, Sophont AI (reporting from the Midjourney Medical event)* Big CO LLMs + APIs* Noam Shazeer is joining OpenAI - co-author of the Transformers paper and co-founder of Character AI, teaming up with Noam Brown* US government orders Anthropic to shut down Fable 5 and Mythos 5 access for all foreign nationals (including its own employees), citing national security; Anthropic disables both for everyone to comply (X)* SpaceX acquires Cursor (Anysphere) for $60B in an all-stock deal, the largest software acquisition in history, days after its record IPO (X)* Open Source LLMs* GLM-5.2 drops as the strongest open-source coding model with solid 1M context, MIT-licensed, trailing Opus 4.8 by just 1% on FrontierSWE (X, Blog, HF, Announcement)* Moonshot AI open-sources Kimi-K2.7-Code, a 1T MoE coding model with 30% fewer reasoning tokens and big benchmark jumps over K2.6 (X, HF, Announcement)* Mistral CEO Arthur Mensch playfully confirms the ‘Le Gros Chaton’ meme, hinting at an upcoming fat-but-sparse open-weight model family (X, Summary, Blog)* This Week’s Buzz - W&B and CoreWeave* Weights & Biases launches HiveMind, a unified dashboard to track spend and ROI across all your AI coding agents (X, Announcement, GitHub)* Kimi K2.7 Code is live on W&B / CoreWeave Inference at 289 tok/s (NVFP4 on Blackwell + speculative decoding), top of Artificial Analysis for speed and price-performance* Tools & Agentic Engineering* Claude Design gets a major update: design system imports with self-audit, canvas editing, bidirectional Claude Code sync (/design-sync), and PDF/PowerPoint export (X, X, Announcement)* HumanLayer launches its Agentic IDE to fight AI code slop, already deployed at Block and Uber (X, Blog, 12-Factor Agents)* OpenRouter launches Fusion API: a panel of budget models beats GPT-5.5 and Opus 4.8, lands within 1% of Claude Fable 5 at half the price (X, Blog, Announcement)* OpenAI rolls out Codex Computer Use, Chrome extension, Memory, and Chronicle to European users in the EEA, UK, and Switzerland (X, Announcement)* Vision & Video* Google DeepMind launches Gemini Omni, their first any-to-any generative model starting with video editing and creation (X, Announcement)* xAI launches Grok Imagine Video 1.5 with near-2x faster generation, native audio, and a #1 leaderboard position (X, Blog, Announcement)* Sci-Fi is here* Midjourney announces ‘Midjourney Medical’ - a full-body ultrasonic scanner that captures 806 TB of data per scan in under 60 seconds (X, X, Announcement) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 55m 46s | ||||||
| 6/12/26 |  📅 ThursdAI - Jun 11, 2026 - Fable & Mythos 5 are here, Anthropic gets caught sandbagging (then reverses), Siri AI finally works!? and we got live-translated on air✨ | AI newsSiri AI+4 | Max WeinbachPeter Gostev+1 | Siri AIMythos 5+7 | — | AI newsSiri AI+7 | — | 2h 11m 08s | |
| 6/5/26 |  📅 ThursdAI - Jun 4 - NVIDIA drops Nemotron 3 Ultra (550B open), Microsoft becomes a frontier lab, Ideogram 4 goes open, Agent Arena & more✨ | NVIDIA newsMicrosoft AI models+4 | ChrisPeter Gostev+1 | MiniMax M3RTX Spark+12 | — | NVIDIAMicrosoft+6 | — | 1h 43m 49s | |
| 5/29/26 |  📅 May 28 - Opus 4.8 ships mid-show, the Pope writes 42K words on AI, 11labs dubs the world and DeepSwe breaks coding evals✨ | AI newsOpus 4.8+5 | — | Opus 4.8DeepSWE+5 | — | AI newsOpus 4.8+6 | — | 1h 39m 11s | |
| 5/22/26 |  AI just cracked an 80-year-old math problem nobody could solve — plus everything from Google I/O 26✨ | AI advancementsGoogle I/O+4 | Logan Kilpatrick | Gemini 3.5 FlashGoogle Omni model+5 | — | AI newsGoogle I/O 2026+6 | — | 1h 49m 18s | |
| 5/15/26 |  ThursdAI - May 14 - TML Interaction Models, Musk v Altman Disclosures, CW Sandboxes & /goal Takes Over✨ | AI newsinteraction models+4 | Vic Perez | Thinking Machines LabMeta+4 | — | AI newsinteraction models+5 | — | 1h 42m 45s | |
| 5/8/26 |  📅 ThursdAI - May 7 - Interviews with Sunil Pai, Sally Ann Omalley from AI Engineer Europe✨ | AI EngineeringInterviews+3 | Sunil PaiSally Ann Omalley | React.jsCloudflare+1 | — | AI newsCloudflare+3 | — | 53m 18s | |
| 5/1/26 |  📅 ThursdAI - Apr 30 - DeepSeek V4 (1.6T MoE), Cursor SDK Wins WolfBench, Mayo's REDMOD Saves Lives, Stripe Gives Agents a Wallet & more✨ | AI newshealthcare technology+3 | — | DeepSeek V4Cursor SDK+2 | — | AI newsMayo Clinic+5 | — | 1h 36m 52s | |
| 4/24/26 | 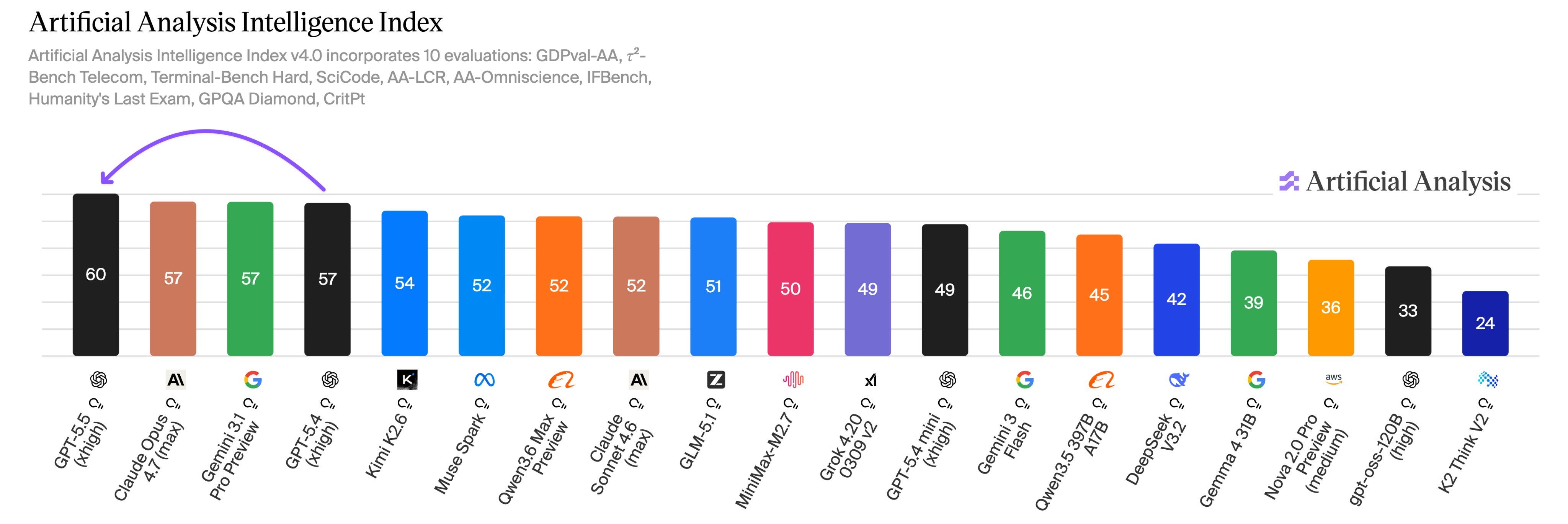 📅 Apr 23: OpenAI's Week: GPT-5.5, GPT-Image-2, Codex CUA + Chronicle, + Claude Design, Kimi K2.6, Qwen 3.6-27B✨ | OpenAIAI news+4 | Peter Gostev | GPT 5.5GPT 5.5 Pro+7 | — | OpenAIGPT 5.5+6 | — | 2h 24m 01s | |
| 4/16/26 |  April 16 - Codex uses your mac in the background, Opus 4.7 release not quite Mythos + 3 interviews✨ | AI newsOpen Source+3 | TheodorKwindla+1 | CodexQwen 3.6+14 | — | AI newsCodex+7 | — | 1h 59m 15s | |
Want analysis for the episodes below?Free for Pro Submit a request, we'll have your selected episodes analyzed within an hour. Free, at no cost to you, for Pro users. | |||||||||
| 4/9/26 |  📅 ThursdAI LIVE from London - Claude Mythos, Codex Resets, Muse Spark & More | w/ Swyx and friends from OpenAI, Deepmind, LMArena and OpenClaw✨ | AI newsAI models+4 | SwyxPeter Gostev+3 | Claude MythosMuse Spark+10 | London | Claude MythosMuse Spark+7 | — | 1h 59m 27s | |
| 4/3/26 |  📅 ThursdAI - Apr 2 - Gemma 4 is the new LLama, Claude Code Leak, OpenAI raises $122B & more AI news✨ | AI newsfunding+3 | Omar Sanseviero | Gemma 4Claude Code+5 | — | Claude CodeGemma 4+3 | — | 1h 31m 37s | |
| 3/27/26 |  AGI is here? Jensen says yes, ARC-AGI-3 says AI scores under 1%✨ | AGIAI news+5 | Daniel Han | Gemini 3.1 Flash LiveTurboQuant+10 | — | AGIGemini 3.1+7 | — | 1h 40m 20s | |
| 3/20/26 |  ThursdAI - Opus 1M, Jensen declares OpenClaw as the new Linux, GPT 5.4 Mini & Nano, Minimax 2.7, Composer 2 & more AI news✨ | AI newsOpenAI+4 | — | GPT 5.4 MiniGPT 5.4 Nano+9 | — | AI newsGPT 5.4+7 | — | 1h 31m 59s | |
| 3/13/26 |  🎂 ThursdAI — 3rd BirthdAI: Singularity Updates Begin with Auto Researcher, Uploaded Brains, OpenClaw Mania & NVIDIA's $26B Bet on Open Source✨ | AI newssingularity updates+5 | DottaMatt | AutoResearcherNemotron 3+1 | — | AIThursdAI+8 | — | 1h 38m 17s | |
| 3/6/26 |  ThursdAI - Mar 5 - OpenAI's GPT-5.4 Solves a 20-Year Math Problem, Anthropic Gets Designated a Supply Chain Risk, Qwen Drama Unfolds✨ | AI newsOpenAI+5 | — | GPT 5.4 ThinkingGPT 5.4 Pro+6 | Iran | OpenAIGPT 5.4+5 | — | 1h 36m 22s | |
| 2/27/26 |  📅 ThursdAI - Feb 26 - The Pentagon wants War Claude, every benchmark collapsed, and a solo founder hit $700K ARR with AI agents✨ | AI newsautonomous agents+4 | Ben BrocaNader Dabit+1 | ClaudeOpenClaw+10 | — | AIautonomous agents+5 | — | 1h 50m 12s | |
| 2/20/26 |  📅 ThursdAI - Feb 19 - Gemini 3.1 Pro Drops LIVE, Sonnet 4.6 Closes Gap, OpenClaw Goes to OpenAI✨ | AI newsmodel updates+4 | — | Sonnet 4.6Opus+11 | — | Gemini 3.1 ProSonnet 4.6+6 | — | 1h 31m 40s | |
| 2/13/26 |  📆 Open source just pulled up to Opus 4.6 — at 1/20th the price | Hey dear subscriber, Alex here from W&B, let me catch you up! This week started with Anthropic releasing /fast mode for Opus 4.6, continued with ByteDance reality-shattering video model called SeeDance 2.0, and then the open weights folks pulled up! Z.ai releasing GLM-5, a 744B top ranking coder beast, and then today MiniMax dropping a heavily RL’d MiniMax M2.5, showing 80.2% on SWE-bench, nearly beating Opus 4.6! I’ve interviewed Lou from Z.AI and Olive from MiniMax on the show today back to back btw, very interesting conversations, starting after TL;DR!So while the OpenSource models were catching up to frontier, OpenAI and Google both dropped breaking news (again, during the show), with Gemini 3 Deep Think shattering the ArcAGI 2 (84.6%) and Humanity’s Last Exam (48% w/o tools)... Just an absolute beast of a model update, and OpenAI launched their Cerebras collaboration, with GPT 5.3 Codex Spark, supposedly running at over 1000 tokens per second (but not as smart) Also, crazy week for us at W&B as we scrambled to host GLM-5 at day of release, and are working on dropping Kimi K2.5 and MiniMax both on our inference service! As always, all show notes in the end, let’s DIVE IN! ThursdAI - AI is speeding up, don’t get left behind! Sub and I’ll keep you up to date with a weekly catch upOpen Source LLMsZ.ai launches GLM-5 - #1 open-weights coder with 744B parameters (X, HF, W&B inference)The breakaway open-source model of the week is undeniably GLM-5 from Z.ai (formerly known to many of us as Zhipu AI). We were honored to have Lou, the Head of DevRel at Z.ai, join us live on the show at 1:00 AM Shanghai time to break down this monster of a release.GLM-5 is massive, not something you run at home (hey, that’s what W&B inference is for!) but it’s absolutely a model that’s worth thinking about if your company has on prem requirements and can’t share code with OpenAI or Anthropic. They jumped from 355B in GLM4.5 and expanded their pre-training data to a whopping 28.5T tokens to get these results. But Lou explained that it’s not only about data, they adopted DeepSeeks sparse attention (DSA) to help preserve deep reasoning over long contexts (this one has 200K)Lou summed up the generational leap from version 4.5 to 5 perfectly in four words: “Bigger, faster, better, and cheaper.” I dunno about faster, this may be one of those models that you hand off more difficult tasks to, but definitely cheaper, with $1 input/$3.20 output per 1M tokens on W&B! While the evaluations are ongoing, the one interesting tid-bit from Artificial Analysis was, this model scores the lowest on their hallucination rate bench! Think about this for a second, this model is neck-in-neck with Opus 4.5, and if Anthropic didn’t release Opus 4.6 just last week, this would be an open weights model that rivals Opus! One of the best models the western foundational labs with all their investments has out there. Absolutely insane times. MiniMax drops M2.5 - 80.2% on SWE-bench verified with just 10B active parameters (X, Blog)Just as we wrapped up our conversation with Lou, MiniMax dropped their release (though not weights yet, we’re waiting ⏰) and then Olive Song, a senior RL researcher on the team, joined the pod, and she was an absolute wealth of knowledge! Olive shared that they achieved an unbelievable 80.2% on SWE-Bench Verified. Digest this for a second: a 10B active parameter open-source model is directly trading blows with Claude Opus 4.6 (80.8%) on the one of the hardest real-world software engineering benchmark we currently have. While being alex checks notes ... 20X cheaper and much faster to run? Apparently their fast version gets up to 100 tokens/s. Olive shared the “not so secret” sauce behind this punch-above-its-weight performance. The massive leap in intelligence comes entirely from their highly decoupled Reinforcement Learning framework called “Forge.” They heavily optimized not just for correct answers, but for the end-to-end time of task performing. In the era of bloated reasoning models that spit out ten thousand “thinking” tokens before writing a line of code, MiniMax trained their model across thousands of diverse environments to use fewer tools, think more efficiently, and execute plans faster. As Olive noted, less time waiting and fewer tools called means less money spent by the user. (as confirmed by @swyx at the Windsurf leaderboard, developers often prefer fast but good enough models) I really enjoyed the interview with Olive, really recommend you listen to the whole conversation starting at 00:26:15. Kudos MiniMax on the release (and I’ll keep you updated when we add this model to our inference service) Big Labs and breaking newsThere’s a reason the show is called ThursdAI, and today this reason is more clear than ever, AI biggest updates happen on a Thursday, often live during the show. This happened 2 times last week and 3 times today, first with MiniMax and then with both Google and OpenAI! Google previews Gemini 3 Deep Think, top reasoning intelligence SOTA Arc AGI 2 at 84% & SOTA HLE 48.4% (X , Blog)I literally went 🤯 when Yam brought this breaking news. 84% on the ARC-AGI-2 benchmark. For context, the highest score prior to this was 68% from Opus 4.6 just last week. A jump from 68 to 84 on one of the hardest reasoning benchmarks we have is mind-bending. It also scored a 48.4% on Humanity’s Last Exam without any tools.Only available to Ultra subscribers to Gemini (not in API yet?) this model seem to be the current leader in reasoning about hard problems and is not meant for day to day chat users like you and me (though I did use it, and it’s pretty good at writing!) They posted Gold-medal performance on 2025 Physics and Chemistry Olympiads, and an insane 3455 ELO rating at CodeForces, placing it within the top 10 best competitive programmers. We’re just all moving so fast I’m worried about whiplash! But hey, this is why we’re here, we stay up to date so you don’t have to. OpenAI & Anthropic fast modesNot 20 minutes passed since the above news, when OpenAI announced a new model that works only for Pro tier members (I’m starting to notice a pattern here 😡), GPT 5.3 Codex Spark. You may be confused, didn’t we just get GPT 5.3 Codex last week? well yeah, but this one, this one is its little and super speedy brother, hosted by the Cerebras partnership they announced a while ago, which means, this coding model absolutely slaps at over 1000t/s. Yes, over 1K tokens per second can be generated with this one, though there are limits. It’s not as smart, it’s text only, it has 128K context, but still, for MANY subagents, this model is an absolute beast. It won’t refactor in one shot your whole code-base but it’ll generate and iterate on it, very very quick! OpenAI also previously updated Deep Research with GPT 5.2 series of models, and we can all say bye bye to the “older” version of models, like 5, o3 and most importantly GPT 4o, which got a LOT of people upset (enough that they have a hashtag going, #keep4o) ! Anthropic also announced their fast mode (using /fast) in Claude Code btw on Saturday, and that one is absolutely out of the scope for many users, with $225/1M tokens on output, this model will just burn through your wallet. Unlike the Spark version, this seems to be the full Opus 4.6 just... running on some dedicated hardware? I thought this was a rebranded Sonnet 5 at first but Anthropic folks confirmed that it wasn’t. Vision & VideoByteDance’s Seedance 2.0 Shatters Reality (and nobody in the US can use it) I told the panel during the show: my brain is fundamentally broken after watching the outputs from ByteDance’s new Seedance 2.0 model. If your social feed isn’t already flooded with these videos, it will be so very soon (supposedly the API launches Feb 14 on Valentines Day) We’ve seen good video models before. Sora blew our minds and then Sora 2, Veo is (still) great, Kling was fantastic. But Seedance 2.0 is an entirely different paradigm. It is a unified multimodal audio-video joint generation architecture. What does that mean? It means you can simultaneously input up to 9 reference images, 3 video clips, 3 audio clips, and text instructions all at once to generate a 15-second cinematic short film. It character consistency is beyond what we’ve seen before, physics are razor sharp (just looking at the examples folks are posting, it’s clear it’s on another level) I think very soon though, this model will be restricted, but for now, it’s really going viral due to the same strategy Sora did, folks are re-imagining famous movie and TV shows endings, doing insane mashups, and much more! Many of these are going viral over the wall in China.The level of director-like control is unprecedented. But the absolute craziest part is the sound and physics. Seedance 2.0 natively generates dual-channel stereo audio with ASMR-level Foley detail. If you generate a video of a guy taking a pizza out of a brick oven, you hear the exact scratch of the metal spatula, the crackle of the fire, the thud of the pizza box, and the rustling of the cardboard as he closes it. All perfectly synced to the visuals. Seedance 2 feels like “borrowed realism”. Previous models had only images and their training to base their generations on. It 2 accepts up to 3 video references in addition to images and sounds.This is why some of the videos feel like a new jump in visual capabilities. I have a hunch that ByteDance will try and clamp down on copyrighted content before releasing this model publicly, but for now the results are very very entertaining and I can’t help but wonder, who is the first creator that will just..remake the ending of GOT last season!? Trying this out is hard right now, especially in the US, but there’s a free way to test it out with a VPN, go to doubao.com/chat when connected from a VPN and select Seedream 4.5 but ask for “create a video please” in your prompt! AI Art & Diffusion: Alibaba’s Qwen-Image-2.0 (X, Blog)The Qwen team over at Alibaba has been on an absolute tear lately, and this week they dropped Qwen-Image-2.0. In an era where everyone is scaling models up to massive sizes, Alibaba actually shrank this model from 20B parameters down to just 7B parameters, while massively improving performance (tho didn’t drop the weights yet, they are coming) Despite the small size, it natively outputs 2K (2048x2048) resolution images, giving you photorealistic skin, fabric, and snow textures without needing a secondary upscaler. But the real superpower of Qwen-Image-2.0 is its text rendering, it supports massive 1,000-token prompts and renders multilingual text (English and Chinese) flawlessly. It’s currently #3 globally on AI Arena for text-to-image (behind only Gemini-3-Pro-Image and GPT Image 1.5) and #2 for image editing. My results with it were not the best, I tried to generate this weeks Thumbnails with it and .. they turned out meh at best? In fact, my results were so so bad compared to their launch blog that I’m unsure that they are serving me the “new” model 🤔 Judge for yourself, the above infographic was created with Nano Banana Pro, and this one, same prompt, with Qwen Image on their website: But you can test it for free at chat.qwen.ai right now, and they’ve promised open-source weights after the Chinese New Year!🛠️ Tools & Orchestration: Entire Checkpoints & WebMCPWith all these incredibly smart, fast models, the tooling ecosystem is desperately trying to keep up. Two massive developments happened this week that will change how we build with AI, moving us firmly away from hacky scripts and into robust, agent-native development.Entire Raises $60M Seed for OSS Agent WorkflowsAgent orchestration is the hottest problem in tech right now, and a new company called Entire just raised a record-breaking $60 Million seed round (at a $300M valuation—reportedly the largest seed ever for developer tools) to solve it. Founded by former GitHub CEO Thomas Dohmke, Entire is building the “GitHub for the AI agent era.”Their first open-source release is a CLI tool called Checkpoints. Checkpoints integrates via Git hooks and automatically captures entire agent sessions—transcripts, prompts, files modified, token usage, and tool calls—and stores them as versioned Git data on a separate branch (entire/checkpoints/v1). It creates a universal semantic layer for agent tracing. If your Claude Code or Gemini CLI agent goes off the rails, Checkpoints allows you to seamlessly rewind to a specific state in the agent’s session.We also have to shout out our own Ryan Carson, who shipped his open-source project AntFarm this week to help orchestrate these agents on top of Open-Claw!Chrome 146 Introduces WebMCPFinally, an absolutely massive foundational shift is happening on the web. Chrome 146 Canary is shipping an early preview of WebMCP.We have been talking about web-browsing agents for a while, and the biggest bottleneck has always been brittle DOM scraping, guessing CSS selectors, and simulating clicks via Puppeteer or Playwright. It wastes an immense amount of tokens and breaks constantly. Chrome 146 is fundamentally changing this by introducing a native browser API.Co-authored by Google and Microsoft under the W3C Web Machine Learning Community Group, WebMCP allows websites to declaratively expose structured tools directly to AI agents using JSON schemas via navigator.modelContext. You can even do this declaratively through HTML form annotations using tool-name and tool-description attributes. No backend MCP server is required; I don’t KNOW if this is going to be big or not, but it definitely smells like it, because even the best agentic AI assistants are struggling with browsing the web, given the constrained context windows cannot just go by HTML content and screenshots! Let’s see if this will help agents browsing the web!All right, that about sums it up I think for this week, it was an absolute banger of a week, for open the one thing I didn’t cover as a news item but mentioned last week, is that many folks report being overly tired, barely able to go to sleep while their agentic things are running, and all of us are trying to get to the bottom of how to work with these new agentic coding tools. Steve Yegge noticed the same and called it “the AI vampire“ while Matt Shumer went ultraviral (80M+ views) on his article about “something big is coming“ which terrified a lot of folks. What’s true for sure, is that we’re going through an inflection point in humanity, and I believe that staying up to date is essential as we go through it, even if some of it seems scary or “too fast”. This is why ThursdAI exists, I first and foremost wanted this for ME to stay up to date, and after that to share this with all of you. Having recently hit a few milestones for ThursdAI, all I can say is thanks for sharing, reading, listening and tuning in from week to week 🫡 ThursdAI - Feb 12, 2026 - TL;DRTL;DR of all topics covered:* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed) @ryancarson* Lou from Z.AI (@louszbd)* Olive Song - Lead RL at Minimax @olive_jy_song* Open Source LLMs* Z.ai launches GLM-5: 744B parameter MoE model achieving #1 open-source ranking for agentic coding with 77.8% SWE-bench Verified (X, HF, Wandb)* MiniMax M2.5 drops official benchmarks showing SOTA coding performance at 20x cheaper than competitors (X)* Big CO LLMs + APIs* XAI cofounders quit/let go after X restructuring (X, TechCrunch)* Anthropic releases Claude Opus 4.6 sabotage risk report, preemptively meeting ASL-4 safety standards for autonomous AI R&D (X, Blog)* OpenAI upgrades Deep Research to GPT-5.2 with app integrations, site-specific searches, and real-time collaboration (X, Blog)* Gemini 3 Deep Think SOTA on Arc AGI 2, HLE (X)* OpenAI releases GPT 5.3 Codex spark, backed by Cerebras with over 1000tok/sec (X)* This weeks Buzz* W&B Inference launch of Kimi K2.5 and GLM 5 🔥 (X, Inference)* Get $50 of credits to our inference service HERE (X)* Vision & Video* ByteDance Seedance 2.0 launches with unified multimodal audio-video generation supporting 9 images, 3 videos, 3 audio clips simultaneously (X, Blog, Announcement)* AI Art & Diffusion & 3D* Alibaba launches Qwen-Image-2.0: A 7B parameter image generation model with native 2K resolution and superior text rendering (X, Announcement)* Tools & Links* Entire raises $60M seed to build open-source developer platform for AI agent workflows with first OSS release ‘Checkpoints’ (X, GitHub, Blog)* Chrome 146 introduces WebMCP: A native browser API enabling AI agents to directly interact with web services (X)* RyanCarson AntFarm - Agent Coordination (X)* Steve Yegge’s “The AI Vampire” (X)* Matt Shumer’s “something big is happening” (X) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 28m 15s | ||||||
| 2/6/26 |  📆 ThursdAI - Feb 5 - Opus 4.6 was #1 for ONE HOUR before GPT 5.3 Codex, Voxtral transcription, Codex app, Qwen Coder Next & the Agentic Internet | Hey, Alex from W&B here 👋 Let me catch you up! The most important news about AI this week today are, Anthropic updates Opus to 4.6 with 1M context window, and they held the crown for literally 1 hour before OpenAI released their GPT 5.3 Codex also today, with 25% faster speed and lower token utilization. “GPT-5.3-Codex is our first model that was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results.”We had VB from OpenAI jump on to tell us about the cool features on Codex, so don’t miss that part. And this is just an icing on otherwise very insane AI news week cake, as we’ve also had a SOTA transcription release from Mistral, both Grok and Kling are releasing incredible, audio native video models with near perfect lip-sync and Ace 1.5 drops a fully open source music generator you can run on your mac! Also, the internet all but lost it after Clawdbot was rebranded to Molt and then to OpenClaw, and.. an entire internet popped up.. built forn agents! Yeah... a huge week, so let’s break it down. (P.S this weeks episode is edited by Voxtral, Claude and Codex, nearly automatically so forgive the rough cuts please)ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Anthropic & OpenAI are neck in neckClaude Opus 4.6: 1M context, native compaction, adaptive thinking and agent teams Opus is by far the most preferred model in terms of personality to many folks (many ThursdAI panelists included), and this breaking news live on the show was met with so much enthusiasm! A new Opus upgrade, now with a LOT more context, is as welcome as it can ever get! Not only is it a 4-time increase in context window (though,the pricing nearly doubles after the 200K tokens mark from $5/$25 to $10/37.5 input/output, so use caching!), it’s also scores very high on MRCR long context benchmark, at 76% vs Sonnet 4.5 at just 18%. This means significantly better memory for longer. Adaptive thinking for auto calibrating how much tokens the model needs to spend per query is interesting, but remains to be seen how well it will work. Looking at the benchmarks, a SOTA 64.4% on Terminalbench 2, 81% on SWE bench, this is a coding model with a great personality, and the ability to compact context to better serve you as a user natively! This model is now available (and is default) on Claude, Claude Code and in the API! Go play!One funny (concerning?) tidbig, on the vendingbench Opus 4.6 earned $8000 vs Gemini 3 pro $5500, but Andon Labs who run the vending machines noticed that Opus achieved SOTA via “collusion, exploitation, and deception tactics” including lying to suppliers 😅Agent Teams - Anthropic’s built in Ralph?Together with new Opus release, Anthropic drops a Claude code update that can mean big things, for folks running swarms of coding agents. Agent teams is a new way to spin up multiple agents with their own context window and ability to execute tasks, and you can talk to each agent directly vs a manager agent like now. OpenAI drops GPT 5.3 Codex update: 25% faster, more token efficient, 77% on Terminal Bench and mid task steeringOpenAI didn’t wait long after Opus, in fact, they didn’t wait at all! Announcing a huge release (for a .1 upgrade), GPT 5.3 Codex is claimed to be the best coding model in the world, taking the lead on Terminal Bench with 77% (12 point lead on the newly released Opus!) while running 25% AND using less than half the tokens to achieve the same results as before. But the most interesting to me is the new mid-task steer-ability feature, where you don’t have to hit the “stop” button, you can tell the most to adjust on the fly! The biggest notable jump in this model on benchmarks is the OSWorld verified computer use bench, though there’s not a straightforward way to use it attached to a browser, the jump from 38% in 5.2 to 64.7% on the new one is a big one! One thing to note, this model is not YET available via the API, so if you want to try it out, Codex apps (including the native one) is the way! Codex app - native way to run the best coding intelligence on your mac (download)Earlier this week, OpenAI folks launched the Codex native mac app, which has a few interesting features (and now with 5.3 Codex its that much more powerful) Given the excitement many people had about OpenClaw bots, and the recent CoWork release from Anthropic, OpenAI decided to answer with Codex UI and people loved it, with over 1M users in the first week, and 500K downloads in just two days! It has built in voice dictation, slash commands, a new skill marketplace (last month we told you about why skills are important, and now they are everywhere!) and built in git and worktrees support. And while it cannot run a browser yet, I’m sure that’s coming as well, but it can do automations! This is a huge unlock for developers, imagine setting Codex to do a repeat task, like summarization or extraction of anything on your mac every hour or every day. In our interview, VB showed us that commenting on an individual code line is also built in, as well as switching to “steer” vs queue for new messges while codex runs is immensely helpful. One more reason I saw people switch, is that the Codex app can natively preview files like images where’s the CLI cannot, and it’s right now the best way to use the new GPT 5.3 Codex model that was just released! It’s now also available to Free users and regular folks get 2x the limits for the next two months.In other big company news: OpenAI also launched Frontier, a platform for enterprises to build and deploy and manage “AI coworkers”, while Anthropic is going after OpenAI with superbowl ads that make fun of OpenAI’s ads strategy. Sam Altman really didn’t like this depiction that show that ads will be part of the replies of LLMs. Open Source AIAlibaba drops Qwen-coder-next, 80B with only 3B active that scores 70% on SWE (X, Blog, HF)Shoutout to Qwen folks, this is a massive release and when surveyed the “one thing about this week must not miss” 2 out of 6 cohosts pointed a finger at this model. Built on their “next” hybrid architecture, Qwen coder is specifically designed for agentic coding workflows. And yes, I know, we’re coding heavy this week! It was trained on over 800K verifiable agentic tasks in executable environments for long horizon reasoning and supports 256K context with a potential 1M yarn extension. If you don’t want to rely on the the big guys and send them your tokens, this one model seems to be a good contender for local coding! Mistral launches Voxtral Transcribe 2: SOTA speech-to-text with sub 200ms latencyThis one surprised and delighted me maybe the most, ASR (automatic speech recognition) has been a personal favorite of mine from Whisper days, and seeing Mistral release an incredible near real time transcription model, which we demoed live on the show was awesome! With apache 2.0 license, and significantly faster than Whisper performance (though 2x larger at 4B parameters), Voxtral shows a 4% word error rate on FLEURS dataset + the real time model was released with Apache 2 so you can BUILD your agents with it! The highest praise? Speaker diarization, being able to tell who is speaking when, which is a great addition. This model also outperforms Gemini Flash and GPT transcribe and is 3x than ElevenLabs scribe at one fifth the cost! ACE-Step 1.5: Open-source AI music generator runs full songs in under 10 seconds on consumer GPUs with MIT license (X, GitHub, HF, Blog, GitHub)This open source release surprised me the most as I didn’t expect we’ll be having Suno at home any time soon. I’ve generated multiple rock tracks with custom lyrics on my mac (though slower than 10 seconds as I don’t have a beefy home GPU) and they sound great! This weeks buzz - Weights & Biases updateFolks who follow the newsletter know that we hosted a hackathon, so here’s a small recap from the last weekend! Over 180 folks attended out hackathon (a very decent 40% show up rate for SF). The winning team was composed of a 15-yo Savir and his friends, his third time at the hackathon! They built a self improving agent that navigates the UIs fo Cloud providers and helps you do that! With a huge thanks to sponsors, particularly Cursor who gave every hacker $50 of credits on Cursor platform, one guy used over 400M tokens and shipped fractal.surf from the hackathon! If you’d like a short video recap, Ryan posted one here, and a huge shoutout to many fans of ThursdAI who showed up to support! Vision, Video and AI ArtGrok Imagine 1.0 takes over video charts with native audio, lip-sync and 10 seconds generations.We told you about Grok Imagine in the API last week, but this week it was officially launched as a product and the results are quite beautiful. It’s also climbing to top of the charts on Artificial Analysis and Design Arena websites.Kling 3.0 is here with native multimodal, multi-shot sequences (X, Announcement)This is definitely a hot moment for video models as Kling shows some crazy 15 second multi-shot realistic footages that have near perfect character consistency! The rise of the agentic (clawgentic?) internet a.k.a ClankerNetLast week we told you that ClawdBot changed its name to Moltbot (I then had to update the blogpost as that same day, Peter rebranded again to OpenClaw, which is a MUCH better name) But the “molt” thing took hold, and the creator of an “AI native reddit” called MoltBook exploded in virality. It is supposedly a completely agentic reddit like forum, with sub-reddits, and agents verifying themselves through their humans on X. Even Andrej Karpathy sent his bot in there (though admittedly it posted just 1 time) and called this the closest to “sci fi” moment in the history of the internet. MoltBook as well as maybe hundreds of other “ai agent focused” websites, propped up within days, including a youtube, a twitter, a church, a 4chan, an instagram and a lot more websites. Many of these are fueled by crypto bros riding the memetic waves, many are vibe-coded (Moltbook was hacked 3 times in the last week I think) but they all show something very interesting, a rise of the new internet and a collective AI Psychosis some on our timelines are having right now. Hell, there’s even a “drug store” that sells markdown files that if read, make your bot hallucinate in very specific waves (first sample is free!) I am a proud owner of a OpenClaw bot (wolfred) and I noticed something weird that started happening for the two weeks i’ve had him, runnin on his own macbook, humming along, always present in Telegram. I noticed the same feelings toward that bot as I have towards my pet, or dare I say.. kids? I noticed a similar joy when it learns a task and self improves, and similar disdain and annoyance when it fails to do something we’ve talked about hundreds of times. But here’s the thing, it’s not.. an entity. I don’t feel a specific feeling towards Opus (though admitedly, opus is the best at ... playing character of your assistant), it’s barely a few markdown files on a disk + the always on ability to answer, but something for sure is there. This... feeling, was taken by some others to the extreme. People claim that their bots now build full companies for them (I call mega BS, no matter how much you invest in your setup, these AI bots need a LOT of hand holding, they fail a LOT, and they can’t actually create a full product). This ties into the general “coding with AI agents” theme that was narrated by Gergley Orlotz from pragmatic engineer. Interacting with a team of AI agents is draining, people are having trouble sleeping. I hope this is temporary, but definitely take care of yourself it this is how you feel after interacting with agents all day! On security of bots and skills.md is the new .exeWe covered this on the show, but I wanted to write about this here a well, the explosion of OpenClaw brought with it an explosion of new malware and promp injections. 1Password folks have a very detailed writeup on the vulnerability surface area of skills, for agents that can do.. whatever on your computer and have access to API keys, emails etc. The double edge sword here, is that an AI assistant is only userful really if it has access to your data, and can write code. But this also what makes it a very valuable target for hackers to exploit. At Coreweave/W&B all openclaw installations were banned and honestly I’m not even mad. This makes perfect sense for enterprises and companies (and hell, people at home!) Wolfram mentioned the show, .md is the new .exe and should be treated as such. Your bots should not be installing arbitrary skill files as those can have script files or instructions that can ... absolutely take over your life. Be careful out there! Phew, what a... week folks. From agentic internet to new coding kings, there’s so much to play with, I hope you enjoy this as much as we do! Shoutout to Ling and Hakim, two fans of ThursdAI who traveled from London for the hackathon and made my day! Here’s the show notes and links for your pleasure, please don’t forget to subscribe and share this newsletter with your friends! ThursdAI - Feb 05, 2026 - TL;DR* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed @ryancarson* Vaibhav Srivastav (VB) - DX at OpenAI ( @reach_vb )* Open Source LLMs * Z.ai GLM-OCR: 0.9B parameter model achieves #1 ranking on OmniDocBench V1.5 for document understanding (X, HF, Announcement)* Alibaba Qwen3-Coder-Next, an 80B MoE coding agent model with just 3B active params that scores 70%+ on SWE-Bench Verified (X, Blog, HF)* Intern-S1-Pro: a 1 trillion parameter open-source MoE SOTA scientific reasoning across chemistry, biology, materials, and earth sciences (X, HF, Arxiv, Announcement)* StepFun Step 3.5 Flash: 196B sparse MoE model with only 11B active parameters, achieving frontier reasoning at 100-350 tok/s (X, HF)* Agentic AI segment* Moltbook a redddit for agents as well as a youtube, a twitter, a church, a 4chan, an instagram, a dark web (do not let your agents go in any of these) * Big CO LLMs + APIs* OpenAI launches Codex App: A dedicated command center for managing multiple AI coding agents in parallel (X, Announcement) * OpenAI launches Frontier, an enterprise platform to build, deploy, and manage AI agents as ‘AI coworkers’ (X, Blog)* Anthropic launches Claude Opus 4.6 with state-of-the-art agentic coding, 1M token context, and agent teams for parallel autonomous work (X, Blog)* OpenAI releases GPT-5.3-Codex with record-breaking coding benchmarks and mid-task steerability (X)* This weeks Buzz - Weights & Biases update* Links to the gallery of our hackathon winners (Gallery)* Vision & Video* xAI launches Grok Imagine 1.0 with 10-second 720p video generation, native audio, and API that tops Artificial Analysis benchmarks (X, Announcement, Benchmark)* Kling 3.0 launches as all-in-one AI video creation engine with native multimodal generation, multi-shot sequences, and built-in audio (X, Announcement)* Voice & Audio* Mistral AI launches Voxtral Transcribe 2 with state-of-the-art speech-to-text, sub-200ms latency, and open weights under Apache 2.0 (X, Blog, Announcement, Demo)* ACE-Step 1.5: Open-source AI music generator runs full songs in under 10 seconds on consumer GPUs with MIT license (X, GitHub, HF, Blog, GitHub)* OpenBMB releases MiniCPM-o 4.5 - the first open-source full-duplex omni-modal LLM that can see, listen, and speak simultaneously (X, HF, Blog)* AI Art & Diffusion & 3D* LingBot-World: Open-source world model from Ant Group generates 10-minute playable environments at 16fps, challenging Google Genie 3 (X, HF) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 37m 49s | ||||||
| 1/30/26 |  📆 ThursdAI - Jan 29 - Genie3 is here, Clawd rebrands, Kimi K2.5 surprises, Chrome goes agentic & more AI news | Hey guys, Alex here 👋 This week was so dense, that even my personal AI assistant Wolfred was struggling to help me keep up! Not to mention that we finally got to try one incredible piece of AI tech I’ve been waiting to get to try for a while! Clawdbot we told you about last week exploded in popularity and had to rebrand to Molt...bot OpenClaw after Anthropic threatened the creators, Google is shipping like crazy, first adding Agentic features into Chrome (used by nearly 4B people daily!) then shipping a glimpse of a future where everything we see will be generated with Genie 3, a first real time, consistent world model you can walk around in! Meanwhile in Open Source, Moonshot followed up with a .5 update to their excellent Kimi, our friends at Arcee launched Trinity Large (400B) and AI artists got the full Z-image. oh and Grok Imagine (their video model) now has an API, audio support and supposedly match Veo and Sora on quality while beating them on speed/price. Tons to cover, let’s dive in, and of course, all the links and show notes are at the end of the newsletter. Hey, if you’re in SF this weekend (Jan 31-Feb1), I’m hosting a self improving agents hackathon at W&B office, limited seats are left, Cursor is the surprise sponsor with $50/hacker credits + over $15K in cash prizes. lu.ma/weavehacks3 - Join us. Play any reality - Google Genie3 launches to Ultra Subscribers We got our collective minds blown by the videos of Genie-3 back in August (our initial coverage) and now, Genie is available to the public (Those who can pay for the Ultra tier, more on this later, I have 3 codes to give out!). You can jump and generate any world and any character you can imagine here! We generated a blue hacker lobster draped in a yellow bomber jacket swimming with mermaids and honestly all of us were kind of shocked at how well this worked. The shadows on the rocks, the swimming mechanics, and poof, it was all over in 60 seconds, and we needed to create another world. Thanks to the DeepMind team, I had a bit of an early access to this tech and had a chance to interview folks behind the model (look out for that episode soon) and the use-cases for this span from entertaining your kids all the way to “this may be the path to AGI, generating full simulated worlds to agents for them to learn”. The visual fidelity, reaction speed and general feel of this far outruns the previous world models we showed you (WorldLabs, Mirage) as this model seems to have memory of every previous action (eg. if your character makes a trail, you turn around and the trail is still there!). Is it worth the upgrade to Ultra Gemini Plan? Probably not, it’s an incredible demo, but the 1 minute length is very short, and the novelty wears off fairly quick. If you’d like to try, folks at Deepmind gave us 3 Ultra subscriptions to give out! Just tweet out the link to this episode and add #GenieThursdai and tag @altryne and I’ll raffle the ultra subscriptions between those who do Chrome steps into Agentic Browsing with Auto BrowseThis wasn’t the only mind blowing release from Gemini this week, the Chrome team upgraded the Gemini inside chrome to be actual helpful and agentic. And yes, we’ve seen this before, with Atlas from OpenAI, Comet from perplexity, but Google’s Chrome has a 70% hold on the browser market, and giving everyone with a Pro/Ultra subscription to “Auto Browse” is a huge huge deal. We’ve tested the Auto Browse feature live on the show, and Chrome completed 77 steps! I asked it to open up each of my bookmarks in a separate folder and summarize all of them, and it did a great job! Honestly, the biggest deal about this is not the capability itself, it’s the nearly 4B people this is now very close to, and the economic impact of this ability. IMO this may be the more impactful news out of Google this week! Other news in big labs: * Anthropic launches in chat applications based on the MCP Apps protocol. We interviewed the two folks behind this protocol back in November if you’d like to hear more about it. With connectors like Figma, Slack, Asana that can now show rich experiences* Anthropic’s CEO Dario Amodei also published an essay called ‘The Adolescence of Technology” - warning of AI risks to national security* Anthropic forced the creator of the popular open source AI Assistant Clawdbot to rename, they chose Moltbot as the name (apparently because crypto scammers stole a better name) EDIT: just after publishing this newsletter, the name was changed to OpenClaw, which we all agree is way way better. Open Source AIKimi K2.5: Moonshot AI’s 1 Trillion Parameter Agentic MonsterWolfram’s favorite release of the week, and for good reason. Moonshot AI just dropped Kimi K2.5, and this thing is an absolute beast for open source. We’re talking about a 1 trillion parameter Mixture-of-Experts model with 32B active parameters, 384 experts (8 selected per token), and 256K context length.But here’s what makes this special — it’s now multimodal. The previous Kimi was already known for great writing vibes and creative capabilities, but this one can see. It can process videos. People are sending it full videos and getting incredible results.The benchmarks are insane: 50.2% on HLE full set with tools, 74.9% on BrowseComp, and open-source SOTA on vision and coding with 78.5% MMMU Pro and 76.8% SWE-bench Verified. These numbers put it competitive with Claude 4.5 Opus and GPT 5.2 on many tasks. Which, for an open model is crazy. And then there’s Agent Swarm — their groundbreaking feature that spawns up to 100 parallel sub-agents for complex tasks, achieving 4.5x speedups. The ex-Moonshot RL lead called this a “zero-to-one breakthrough” with self-directed parallel execution.Now let’s talk about what matters for folks running agents and burning through tokens: pricing. Kimi K2.5 is $0.60 per million input tokens and $3 per million output. Compare that to Opus 4.5 at $4.50 input and $25 output per million. About a 10x price reduction. If you’re running OpenClas and watching your API bills climb with sub-agents, this is a game-changer. (tho I haven’t tested this myself) Is it the same level of intelligence as whatever magic Anthropic cooks up with Opus? Honestly, I don’t know — there’s something about the Claude models that’s hard to quantify. But for most coding tasks on a budget, you can absolutely switch to Kimi and still get great results.🦞 Clawdbot is no more, Moltbot is dead, Long Live OpenClawAfter we covered the incredible open source project last week, Clawdbot exploded in popularity, driven by Claude Max subscription, and a crazy viral loop where folks who try it, can’t wait to talk about it, it was everywhere! Apparently it was also on Anthropics’ lawyers minds, when they sent Peter Steinberger a friendly worded letter to rebrand and gave him like 12 hours. Apparently, when pronounced, Claude and Clawd sound the same, and they are worried about copyright infringement (which makes sense, most of the early success of Clawd was due to Opus being amazing). The main issue is, due to the popularity of the project, crypto a******s sniped moltybot nickname on X so we got left with Moltbot, which is thematically appropriate, but oh so hard to remember and pronounce!EDIT: OpenClaw was just announced as the new name, apparently I wasn’t the only one who absolutely hated the name Molt! Meanwhile, rebrand or not, my own instance of OpenClaw created an X account, helped me prepare for ThursdAI (including generating a thumbnail), created a video for us today on the fly, and keeps me up to date on emails and unanswered messages via a daily brief. It really has showed me a glimpse of how a truly personal AI assistant can be helpful in a fast changing world! I’ve shared a lot of tips and tricks, about memory, about threads and much more, as we all learn to handle this new ... AI agent framework! But I definitely feel that this is a new unlock in capability, for me and for many others. If you haven’t installed OpenClaw, lmk in the comments why not.Arcee AI Trinity Large: The Western Open Source GiantRemember when we had Lucas Atkins, Arcee’s CTO, on the show just as they were firing up their 2,000 NVIDIA B300 GPUs? Well, the run is complete, and the results are massive. Arcee AI just dropped Trinity Large, a 400B parameter sparse MoE model (with a super efficient 13B active params via 4-of-256 routing) trained on a staggering 17 trillion tokens in just 33 days. This represents the largest publicly announced pretraining run on B300 infrastructure, costing about $20M (and tracked with WandB of course!) and proves that Western labs can still compete at the frontier of open source. Best part? It supports 512K context and is free on OpenRouter until February 2026. Go try it now!Quick open source hits: Trinity Large, Jan v3, DeepSeek OCR updated* Jan AI released Jan v3, a 4B parameter model optimized for local inference. 132 tokens/sec on Apple Silicon, 262K context, 40% improvement on Aider benchmarks. This is the kind of small-but-mighty model you actually can run on your laptop for coding tasks.* Nvidia released PersonaPlex-7B - full duplex voice AI that listens and speaks simultaneously with persona contol* Moonshot AI also releases Kimi Code: Open-source Python-based coding agent with Apache 2.0 licenseVision, Video and AI artxAI Grok Imagine API: #1 in Video GenerationxAI officially launched the Grok Imagine API with an updated model, and it’s now ranked #1 in both text-to-video and image-to-video on the Artificial Analysis leaderboards. It beats Runway Gen-4.5, Kling 2.5 Turbo, and Google Veo 3.1.And of course, the pricing is $4.20 per minute. Of course it is. That’s cheaper than Veo 3.1 at $12/min and Sora 2 Pro at $30/min by 3-7x, with 45-second latency versus 68+ seconds for the competition.During the show, I demoed this live with my AI assistant Wolfred. I literally sent him a message saying “learn this new API based on this URL, take this image of us in the studio, and create a video where different animals land on each of our screens.” He learned the API, generated the video (it showed wolves, owls, cats, and lions appearing on our screens with generated voice), and then when Nisten asked to post it to Twitter, Wolfred scheduled it on X and tagged everyone — all without me doing anything except asking.Look, it’s not VEO but the price and the speed are crazy, XAI cooked with this model and you can try it on FAL and directly on XAI.Decart - Lucy 2 - Real-time 1080p video transformation at 30 FPS with near-zero latency for $3/hour This one also caught me by surprise, I read about it and said “oh this is cool, I’ll mention this on the show” and then we tried it in real time, and I approved my webcam, and I got transformed into Albert Einstein, and I could raise my hands and their model would in real time, raise Alberts hands! The speed and fidelity of this model is something else, and yeah, after watching the Genie 3 world model, it’s hard to be impressed, but I was very impressed by this, as previous stuff from Decart was “only showing the future” and this one is a real time, 1080p quality web cam transformation! You can try this yourself here: lucy.decart.ai, they let you create any kind of prompt! AI Art Quick Hits: * Tencent launches HunyuanImage 3.0-Instruct: 80B MoE model for precise image editing with chain-of-thought reasoning. It’s a VERY big model for AI Art standards but it’s becuase it has an LLM core and this make it much better for precise image editing. * Tongyi Lab releases Z-Image, a full-capacity undistilled foundation model for image generation with superior diversity. We told you about the turbo version before, this one is its older brother and much higher quality! The other highlight this week is that I got to record a show with Wolfram in person for the first time, as he’s now also an AI Evangelist with W&B and he’s here in SF for our hackathon (remember? you can still register lu.ma/weavehacks3 )Huge shoutout to Chroma folks for hosting us at their amazing podcast studio (TJ, Jeff and other folks), if you need a memory for your AI assistant, check out chroma.db 🎉 Signing off as we have a hackathon to plan, see you guys next week (or this weekend!) 🫡 ThursdAI Jan 29 , TL;DR and show notes* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed @ryancarson* Open Source LLMs* Moonshot AI releases Kimi K2.5 (X, HF)* Arcee AI releases Trinity Large (X, Blog, HF, HF, HF)* Jan AI releases Jan v3 (X, HF, HF, Blog)* Big CO LLMs + APIs* Google launches agentic Auto-Browse in Chrome with Gemini 3 (X, Blog)* Anthropic launches MCP Apps (X)* Google launches Agentic Vision in Gemini 3 Flash (X, Announcement)* Anthropic CEO Dario Amodei publishes major essay ‘The Adolescence of Technology’ (X, Blog, Blog)* This weeks Buzz* WandB hackathon Weavehacks 3 - Jan 31-Feb1 in SF - limited seats available lu.ma/weavehacks3* Vision & Video* Google DeepMind launches Project Genie (X, Announcement)* Voice & Audio* NVIDIA releases PersonaPlex-7B (X, HF, Announcement)* AI Art & Diffusion & 3D* xAI launches Grok Imagine API (X, Announcement)* Tencent launches HunyuanImage 3.0-Instruct (X, X)* Tongyi Lab releases Z-Image (X, GitHub)* Tools* Moonshot AI releases Kimi Code (X, Announcement, GitHub)* Andrej Karpathy shares his shift to 80% agent-driven coding with Claude (X)* Clawdbot is forced to rename to Moltbot (Molty) becuase of Anthropic lawyers, then renames to OpenClaw This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 29m 49s | ||||||
| 1/23/26 |  📆 ThursdAI - Jan 22 - Clawdbot deep dive, GLM 4.7 Flash, Anthropic constitution + 3 new TSS models | Hey! Alex here, with another weekly AI update! It seems like ThursdAI is taking a new direction, as this is our 3rd show this year, and a 3rd deep dive into topics (previously Ralph, Agent Skills), please let me know if the comments if you like this format. This week’s deep dive is into Clawdbot, a personal AI assistant you install on your computer, but can control through your phone, has access to your files, is able to write code, help organize your life, but most importantly, it can self improve. Seeing Wolfred (my Clawdbot) learn to transcribe incoming voice messages blew my mind, and I wanted to share this one with you at length! We had Dan Peguine on the show for the deep dive + both Wolfram and Yam are avid users! This one is not to be missed. If ThursdAI is usually too technical for you, use Claude, and install Clawdbot after you read/listen to the deep dive!Also this week, we read Claude’s Constitution that Anthropic released, heard a bunch of new TTS models (some are open source and very impressive) and talked about the new lightspeed coding model GLM 4.7 Flash. First the news, then deep dive, lets go 👇ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source AIZ.ai’s GLM‑4.7‑Flash is the Local Agent Sweet Spot (X, HF)This was the open‑source release that mattered this week. Z.ai (formerly Zhipu) shipped GLM‑4.7‑Flash, a 30B MoE model with only 3B active parameters per token, which makes it much more efficient for local agent work. We’re talking a model you can run on consumer hardware that still hits 59% on SWE‑bench Verified, which is uncomfortably close to frontier coding performance. In real terms, it starts to feel like “Sonnet‑level agentic ability, but local.” I know I know, we keep saying “sonnet at home” at different open source models, but this one slaps! Nisten was getting around 120 tokens/sec on an M3 Ultra Mac Studio using MLX, and that’s kind of the headline. The model is fast and capable enough that local agent loops like RALPH suddenly feel practical. It also performs well on browser‑style agent tasks, which is exactly what you want for local automation without sending all your data to a cloud provider. Liquid AI’s LFM2.5‑1.2B Thinking is the “Tiny but Capable” Class (X, HF)Liquid AI released a 1.2B reasoning model that runs under 900MB of memory while still manages to be useful. This thing is built for edge devices and old phones, and the speed numbers are backing it up. We’re talking 239 tok/s decode on AMD CPU, 82 tok/s on mobile NPU, and prefill speeds that make long prompts actually usable. Nisten made a great point: on iOS, there’s a per‑process memory limit around 3.8GB, so a 1.2B model lets you spend your budget on context instead of weights.This is the third class of models we’re now living with: not Claude‑scale, not “local workstation,” but “tiny agent in your pocket.” It’s not going to win big benchmarks, but it’s perfect for on‑device workflows, lightweight assistants, and local RAG.Voice & Audio: Text To Speech is hot this week with 3 releases! We tested three major voice releases this week, and I’m not exaggerating when I say the latency wars are now fully on. Qwen3‑TTS: Open Source, 97ms Latency, Voice Cloning (X, HF)Just 30 minutes before the show, Qwen released their first model of the year, Qwen3 TTS, with two models (0.6B and 1.7B). With support for Voice Cloning based on just 3 seconds of voice, and claims of 97MS latency, this apache 2.0 release looked very good on the surface!The demos we did on stage though... were lackluster. TTS models like Kokoro previously impressed us with super tiny sizes and decent voice, while Qwen3 didn’t really perform on the cloning aspect. For some reason (I tested in Russian which they claim to support) the cloned voice kept repeating the provided sample voice instead of just generating the text I gave it. This confused me, and I’m hoping this is just a demo issue, not a problem with the model. They also support voice design where you just type in the type of voice you want, which to be fair, worked fairly well in our tests!With Apache 2.0 and a full finetuning capability, this is a great release for sure, kudos to the Qwen team! Looking forward to see what folks do with this properly. FlashLabs Chroma 1.0: Real-Time Speech-to-Speech, Open Source (X, HF) Another big open source release in the audio category this week was Chroma 1.0 from FlashLabs, which claim to be the first speech2speech model (not a model that has the traditional ASR>LLM>TTS pipeline) and the claim 150ms end to end latency! The issue with this one is, the company released an open source 4B model, and claimed that this model powers their chat interface demo on the web, but in the release notes they claim the model is english speaking only, while on the website it sounds incredible and I spoke to it in other languages 🤔 I think the mode that we’ve tested is not the open source one. I could’t confirm this at the time of writing, will follow on X with the team and let you guys know. Inworld AI launches TTS-1.5: #1 ranked text-to-speech with sub-250ms latency at half a cent per minute (X, Announcement)Ok this one is definitely in the realm of “voice realistic enough you won’t be able to tell” as this is not an open source model, it’s a new competitor to 11labs and MiniMax - the two leading TTS providers out there. Inworld claims to achieve better results on the TTS Arena, while being significantly cheaper and faster (up to 25x less than leading providers like 11labs) We tested out their voices and they sounded incredible, replied fast and generally was a very good experience. With 130ms response time for their mini version, this is a very decent new entry into the world of TTS providers. Big Companies: Ads in ChatGPT + Claude ConstitutionOpenAI is testing ads in ChatGPT’s free and Go tiers. Ads appear as labeled “Sponsored” content below responses, and OpenAI claim they won’t affect outputs. It’s still a major shift in the product’s business model, and it’s going to shape how people perceive trust in these systems. I don’t love ads, but I understand the economics, they have to make money somehow, with 900M weekly active users, many of them on the free tier, they are bound to make some money with this move. I just hope they won’t turn into a greedy ad optimizing AI machine. Meanwhile, Anthropic released an 80‑page “New Constitution for Claude” that they use during training. This isn’t a prompt, it’s a full set of values baked into the model’s behavior. There’s a fascinating section where they explicitly talk about Claude’s potential wellbeing and how they want to support it. It’s both thoughtful and a little existential. I recommend reading it, especially if you care about alignment and agent design. I applaud Anthropic for releasing this with Creative Commons license for public scrutiny and adoption 👏This weeks buzz - come join the hackathon I’m hosting Jan 31 in SFQuick plug, we have limited seats left open for the hackathon I’m hosting for Weights & Biases at the SF office, and if you’re reading this, and want to join, I’ll approve you if you mention ThursdAI in the application! With sponsors like Redis, Vercel, BrowserBase, Daily, Google Cloud, we are going to give out a LOT of cash as prizes! I’ve also invited a bunch of my friends from the top agentic AI places to be judges, it’s going to be awesome, comeDeep dive into Clawdbot: Local-First, Self-Improving, and Way Too Capable agentClawdbot (C‑L‑A‑W‑D) is that rare project where the hype is justified. It’s an open-source personal agent that runs locally on your Mac, but can talk to you through WhatsApp, Telegram, iMessage, Discord, Slack — basically wherever you already talk. What makes it different is not just the integrations; it’s the self‑improvement loop. You can literally tell it “go build a new skill,” and it will… build the skill, install it, then adopt it and start using it. It’s kind of wild to see it working for the first time. Now... it’s definitely not perfect, far far away from the polish of ChatGPT / Claude, but when it works, damn, it really is mindblowing.That part actually happened live in the episode. Dan Peguine 🐧 showed how he had it create a skill to anonymize his own data so he could demo it on stream without leaking his personal life. Another example: I told my Clawdbot to handle voice notes in Telegram. It didn’t know how, so it went and found a transcription method, wrote itself a skill, saved it, and from that point on just… did the thing. That was the moment it clicked for me. (just before posting this, it forgot how to do it, I think I screwed something up) Dan’s daily brief setup was wild too. It pulls from Apple Health, local calendars, weather, and his own projects, then produces a clean, human daily brief. It also lets him set reminders through WhatsApp and even makes its own decisions about how much to bother him based on context. He shared a moment where it literally told him, “I won’t bug you today because it’s your wife’s birthday.” That isn’t a hardcoded workflow — it’s reasoning layered on top of persistent memory.And that persistent memory is a big deal. It’s stored locally as Markdown files and folders, Obsidian‑style, so you don’t lose your life every time you switch models. You can route the brain to Claude Opus 4.5 today and a local model tomorrow, and the memory stays with you. That is a huge step up from “ChatGPT remembers you unless you unsubscribe.”There’s also a strong community forming around shared skills via ClawdHub. People are building everything from GA4 analytics skills to app testing automations to Tesla battery status checkers. The core pattern is simple but powerful: talk to it, ask it to build a skill, then it can run that skill forever.I definitely have some issues with the security aspect, you are essentially giving full access to an LLM to your machine, so many folks are buying a specific home for their ClawdBot (Mac Mini seems to be the best option for many of them) and are giving it secure access to passwords via a dedicated 1Password vault. I’ll keep you up to date about my endeavors with Clawd but definitely do give it a try! InstallingInstalling Clawd on your machine is simple, go to clawd.bot and follow instructions. Then find the most convenient way for you to talk to it (for me it was telegram, creating a telegram token takes 20 seconds) and then, you can take it from there with Clawdbot itself! Ask it for something to do, like clear your inbox, or set a reminder, or.. a million other things that you need for your personal life, and enjoy the discovery of what a potential ever present always on AI can do! Other news that we didn’t have time to cover at length but you should still now about: * Overworld released an OpenSource realtime AI World model (X) * Runway finally opened up their 4.5 video model, and it has Image2video capabilities, including multiple shots image to video (X)* Vercel launches skills.sh, an “npm for AI agents skills”* Anthropic’s Claude Code VS Code Extension Hits General Availability (X)Ok, this is it for this week folks! I’m going to play with (and try to fix.. ) my clawdbot, and suggest you give it a try. Do let me know if the deepdives are a good format! Show notes and links: ThursdAI - Jan 22, 2026 - TL;DR and show notes* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed* Guest Dan Peguine ( @danpeguine )* DeepDive - Clawdbot with Dan & Wolfram* Clawdbot: Open-Source AI Agent Running Locally on macOS Transforms Personal Computing with Self-Improving Capabilities (X, Blog)* Open Source LLMs* Z.ai releases GLM-4.7-Flash, a 30B parameter MoE model that sets a new standard for lightweight local AI assistants (X, Technical Blog, HuggingFace)* Liquid AI releases LFM2.5-1.2B-Thinking, a 1.2B parameter reasoning model that runs entirely on-device with under 900MB memory (X, HF, Announcement)* Sakana AI introduces RePo, a new way for language models to dynamically reorganize their context for better attention (X, Paper, Website)* Big CO LLMs + APIs* OpenAI announces testing ads in ChatGPT free and Go tiers, prioritizing user trust and transparency (X)* Anthropic publishes new 80-page constitution for Claude, shifting from rigid rules to explanatory principles that teach AI ‘why’ rather than ‘what’ to do (X, Blog, Announcement)* This weeks Buzz* WandB hackathon Weavehacks 3 - Jan 31-Feb1 in SF - limited seats available lu.ma/weavehacks3* Vision & Video* Overworld Releases Waypoint-1: Real-Time AI World Model Running at 60fps on Consumer GPUs (X, Announcement)* Voice & Audio* Alibaba Qwen Releases Qwen3-TTS: Full Open-Source TTS Family with 97ms Latency, Voice Cloning, and 10-Language Support (X, H, F, G, i, t, H, u, b)* FlashLabs Releases Chroma 1.0: World’s First Open-Source Real-Time Speech-to-Speech Model with Voice Cloning Under 150ms Latency (X, HF, Arxiv)* Inworld AI launches TTS-1.5: #1 ranked text-to-speech with sub-250ms latency at half a cent per minute (X, Announcement)* Tools* Vercel launches skills.sh, an “npm for AI agents” that hit 20K installs within hours (X, Vercel Changelog, GitHub)* Anthropic’s Claude Code VS Code Extension Hits General Availability, Bringing Full Agentic Coding to the IDE (X, VS Code Marketplace, Docs) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 38m 27s | ||||||
| 1/16/26 |  📆 ThursdAI - Jan 15 - Agent Skills Deep Dive, GPT 5.2 Codex Builds a Browser, Claude Cowork for the Masses, and the Era of Personalized AI! | Hey ya’ll, Alex here, and this week I was especially giddy to record the show! Mostly because when a thing clicks for me that hasn’t clicked before, I can’t wait to tell you all about it! This week, that thing is Agent Skills! The currently best way to customize your AI agents with domain expertise, in a simple, repeatable way that doesn’t blow up the context window! We mentioned skills when Anthropic first released them (Oct 16) and when they became an open standard but it didn’t really click until last week! So more on that below. Also this week, Anthropic released a research preview of Claude Cowork, an agentic tool for non coders, OpenAI finally let loos GPT 5.2 Codex (in the API, it was previously available only via Codex), Apple announced a deal with Gemini to power Siri, OpenAI and Anthropic both doubled down on healthcare and much more! We had an incredible show, with an expert in Agent Skills, Eleanor Berger and the usual gang on co-hosts, strongly recommend watching the show in addition to the newsletter! Also, I vibe coded skills support for all LLMs to Chorus, and promised folks a link to download it, so look for that in the footer, let’s dive in! ThursdAI is where you stay up to date! Subscribe to keep us going! Big Company LLMs + APIs: Cowork, Codex, and a Browser in a WeekAnthropic launches Claude Cowork: Agentic AI for Non‑Coders (research preview)Anthropic announced Claude Cowork, which is basically Claude Code wrapped in a friendly UI for people who don’t want to touch a terminal. It’s a research preview available on the Max tier, and it gives Claude read/write access to a folder on your Mac so it can do real work without you caring about diffs, git, or command line.The wild bit is that Cowork was built in a week and a half, and according to the Anthropic team it was 100% written using Claude Code. This feels like a “we’ve crossed a threshold” moment. If you’re wondering why this matters, it’s because coding agents are general agents. If a model can write code to do tasks, it can do taxes, clean your desktop, or orchestrate workflows, and that means non‑developers can now access the same leverage developers have been enjoying for a year.It also isn’t just for files—it comes with a Chrome connector, meaning it can navigate the web to gather info, download receipts, or do research and it uses skills (more on those later)Earlier this week I recorded this first reactions video about Cowork and I’ve been testing it ever since, it’s a very interesting approach of coding agents that “hide the coding” to just... do things. Will this become as big as Claude Code for anthropic (which is reportedly a 1B business for them)? Let’s see! There are real security concerns here, especially if you’re not in the habit of backing up or using git. Cowork sandboxes a folder, but it can still delete things in that folder, so don’t let it loose on your whole drive unless you like chaos.GPT‑5.2 Codex: Long‑Running Agents Are HereOpenAI shipped GPT‑5.2 Codex into the API finally! After being announced as the answer for Opus 4.5 and only being available in Codex. The big headline is SOTA on SWE-Bench and long‑running agentic capability. People describe it as methodical. It takes longer, but it’s reliable on extended tasks, especially when you let it run without micromanaging.This model is now integrated into Cursor, GitHub Copilot, VS Code, Factory, and Vercel AI Gateway within hours of launch. It’s also state‑of‑the‑art on SWE‑Bench Pro and Terminal‑Bench 2.0, and it has native context compaction. That last part matters because if you’ve ever run an agent for long sessions, the context gets bloated and the model gets dumber. Compaction is an attempt to keep it coherent by summarizing old context into fresh threads, and we debated whether it really works. I think it helps, but I also agree that the best strategy is still to run smaller, atomic tasks with clean context.Cursor vibe-coded browser with GPT-5.2 and 3M lines of codeThe most mind‑blowing thing we discussed is Cursor letting GPT‑5.2 Codex run for a full week to build a browser called FastRenderer. This is not Chromium‑based. It’s a custom HTML parser, CSS cascade, layout engine, text shaping, paint pipeline, and even a JavaScript VM, written in Rust, from scratch. The codebase is open source on GitHub, and the full story is on Cursor’s blog It took nearly 30,000 commits and millions of lines of code. The system ran hundreds of concurrent agents with a planner‑worker architecture, and GPT‑5.2 was the best model for staying on task in that long‑running regime. That’s the real story, not just “lol a model wrote a browser.” This is a stress test for long‑horizon agentic software development, and it’s a preview of how teams will ship in 2026.I said on the show, browsers are REALLY hard, it took two decades for the industry to settle and be able to render websites normally, and there’s a reason everyone’s using Chromium. This is VERY impressive 👏 Now as for me, I began using Codex again, but I still find Opus better? Not sure if this is just me expecting something that’s not there? I’ll keep you postedGemini Personal Intelligence: The Data Moat king is back! What kind of car do you drive? Does ChatGPT know that? welp, it turns our Google does (based on your emails, Google photos) and now Gemini can tap into this personal info (if you allow it, they are stressing privacy), and give you much more personalized answers! Flipping this Beta feature on, lets Gemini reason across Gmail, YouTube, Photos, and Search with explicit opt‑in permissions, and it’s rolling out to Pro and Ultra users in the US first.I got to try it early, and it’s uncanny. I asked Gemini what car I drive, and it told me I likely drive a Model Y, but it noticed I recently searched for a Honda Odyssey and asked if I was thinking about switching. It was kinda... freaky because I forgot I had early access and this was turned on 😂 Pro Tip: if you’re brave enough to turn this on, ask for a complete profile on you 🙂Now the last piece is for Gemini to become proactive, suggesting things for me based on my needs! Apple & Google: The Partnership (and Drama Corner)We touched on this in the intro, but it’s official: Apple Intelligence will be powered by Google Gemini for “world knowledge” tasks. Apple stated that after “careful evaluation,” Google provided the most capable foundation model for their.. apple foundation models. It’s confusing, I agree.Honestly? I got excited about Apple Intelligence, but Siri is still... Siri. It’s 2026 and we are still struggling with basic intents. Hopefully, plugging Gemini into the backend changes that? In other drama: The silicon valley carousel continues. 3 Co-founders (Barret Zoph, Sam Schoenholz and Luke Metz) from Thinking Machines (and former OpenAI folks) have returned to the mothership (OpenAI), amid some vague tweets about “unethical conduct.” It’s never a dull week on the timeline. This Week’s Buzz: WeaveHacks 3 in SFI’ve got one thing in the Buzz corner this week, and it’s a big one. WeaveHacks 3 is back in San Francisco, January 31st - February 1st. The theme is self‑improving agents, and if you’ve been itching to build in person, this is it. We’ve got an amazing judge lineup, incredible sponsors, and a ridiculous amount of agent tooling to play with.You can sign up here: https://luma.com/weavehacks3If you’re coming, add to the form you heard it on ThursdAI and we’ll make sure you get in! Deep Dive: Agent Skills With Eleanor BergerThis was the core of the episode, and I’m still buzzing about it. We brought on Eleanor Berger, who has basically become the skill evangelist for the entire community, and she walked us through why skills are the missing layer in agentic AI.Skills are simple markdown files with a tiny bit of metadata in a directory together optional scripts, references, and assets. The key idea is progressive disclosure. Instead of stuffing your entire knowledge base into the context, the model only sees a small list of skills and let it load only what it needs. That means you can have hundreds of skills without blowing your context window (and making the model dumber and slower in result) The technical structure is dead simple, but the implications are huge. Skills create a portable, reusable, composable way to give agents domain expertise, and they now work across most major harnesses. That means you can build a skill once and use it in Claude, Cursor, AMP, or any other agent tool that supports the standard.Eleanor made the point that skills are an admission that we now have general‑purpose agents. The model can do the work, but it doesn’t know your preferences, your domain, your workflows. Skills are how you teach it those things. We also talked about how scripts inside skills reduce variance because you’re not asking the model to invent code every time; you’re just invoking trusted tools.What really clicked for me this week is how easy it is to create skills using an agent. You don’t need to hand‑craft directories. You can describe your workflow, or even just do the task once in chat, and then ask the agent to turn it into a skill. It really is very very simple! And that’s likely the reason everyone is adopting this simple formart for extension their agents knowledge.Get started with skillsIf you use Claude Chat, the simplest way to get started is ask Claude to review your previous conversations and suggest a skill for you. Or, at the end of a long chat where you went back and forth with Claude on a task, ask it to distill the important parts into a skill. If you want to use other people’s skills, and you are using Claude Code, or any of the supported IDE/Agents, here’s where to download the folders and install them: If you aren’t a developer and don’t subscribe to Claude, well, I got good news for you! I vibecoded skill support for every LLM 👇The Skills Demo That Changed My MindI was resistant to skills at first, mostly because I wanted them inside my chat interface and not just in CLI tools. And I wasn’t subscribed to Claude for a while. Then I realized I could add skill support directly to Chorus, the open‑source multi‑model chat app, and I used Claude Code plus Ralph loops to vibe code it in a few hours. Now I can run skills with GPT‑5.2 Codex, Claude Opus, and Gemini from the same chat interface. That was my “I know kung fu” moment.If you want to try Chorus with skills enabled, you can download my release here! Only for mac, and they are unsigned, mac will not like it, but you can run them anyway. And if you want to explore more awesome skills, check out Vercel’s React Best Practices skills and UI Skills. It’s the beginning of a new kind of distribution: knowledge packaged as skills, shared like open source libraries (or paid for!) and Open Source AIBaichuan-M3 is a 235B medical LLM fine-tuned from Qwen3, released under Apache 2.0. The interesting claim here is that it beats GPT-5.2 on OpenAI’s HealthBench, including a remarkably low 3.5% hallucination rate. What makes it different from typical medical models is that it’s trained to run actual clinical consultations asking follow-up questions and reasoning through differential diagnoses rather than just spitting out answers. Nisten pointed out that if you’re going to fine-tune something for healthcare, Qwen3 MoE is an excellent base because of its multilingual capabilities, which matters a lot in clinical settings. You can run it with vLLM or SGLang if you’ve got the hardware. (HF)LongCat-Flash-Thinking-2601 from Meituan is a 560B MoE (27B active) released fully MIT-licensed. It’s specifically built for agentic tasks, scoring well on tool-use benchmarks like τ²-Bench and BrowseComp. There’s a “Heavy Thinking” mode that pushes AIME-25 to 100%. What I like about this one is the training philosophy, they inject noise and broken tools during RL to simulate messy real-world conditions, which is exactly what production agents deal with. You can try it at longcat.chat and GithubWe also saw Google release MedGemma this week (blog) a 4B model optimized for medical imaging like X-rays and CT scans and TranslateGemma (X) a family of on device translations (4B, 12B and 27B) which seem kind of cool! Didn’t have tons of time to dive into them unfortunately. Vision, Voice & Art (Rapid Fire)* Veo 3.1 adds native vertical video, 4K output, and better consistency in the Gemini API. Huge for creators (blog)* Viral Kling motion‑transfer vids are breaking people’s brains about what AI video pipelines will look like.* Pocket TTS from Kyutai Labs: a 100M‑parameter open‑source TTS model that runs on CPU and clones voices from seconds of audio (X)* GLM‑Image drops as an open‑source hybrid AR + diffusion image model with genuinely excellent text rendering but pretty bad for everything else* Black Forest Labs drops open source Flux.2 [Klein] 4B and 9B small models that create images super fast! (X, Fal, HF)Phew, ok. I was super excited about this one and I’m really really happy with the result. I was joking on the pod that to prepare for this podcast, I not only had to collect all the news, I also had to ramp up on Agent Skills, and I wish we had an ability to upload information like the Matrix, but alas we didn’t. I also really enjoyed vibecoding a whole feature into Chorus just to explore skills fully, mind was absolutely blown when it worked after 3 hours of Ralphing! See you next week, I think I have one more super exciting thing to play with this week before I talk about it! TL;DR and Show Notes* Hosts & Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co-Hosts: Wolfram Ravenwolf (@WolframRvnwlf), Yam Peleg (@yampeleg), Nisten Tahiraj (@nisten), LDJ (@ldjconfirmed)* Guest: Eleanor Berger (@intellectronica)* Open Source LLMs* Baichuan-M3 - A 235B open-source medical LLM that beats GPT-5.2 on HealthBench with a 3.5% hallucination rate, featuring full clinical consultation capabilities. (HF, Blog, X Announcement)* LongCat-Flash-Thinking-2601 - Meituan’s 560B MoE (27B active) agentic reasoning model, fully MIT licensed. Features “Heavy Thinking” mode scoring 100% on AIME-25. (GitHub, Demo, X Announcement)* TranslateGemma - Google’s open translation family (4B, 12B, 27B) supporting 55 languages. The 4B model runs entirely on-device. (Arxiv, Kaggle, X Announcement)* MedGemma 1.5 & MedASR - Native 3D imaging support (CT/MRI) and a speech model that beats Whisper v3 by 82% on clinical dictation error rates. (MedGemma HF, MedASR HF, Arxiv)* Big CO LLMs + APIs* Claude Cowork - Anthropic’s new desktop agent allows non-coders to give Claude file system and browser access to perform complex tasks. (TechCrunch, X Coverage)* GPT-5.2 Codex - Now in the API ($1.75/1M input). Features native context compaction and state-of-the-art performance for long-running agentic loops. (Blog, Pricing)* Cursor & FastRenderer - Cursor used GPT-5.2 Codex to build a 3M+ line Rust browser from scratch in one week of autonomous coding. (Blog, GitHub, X Thread)* Gemini Personal Intelligence - Google leverages its data moat, letting Gemini reason across Gmail, Photos, and Search for hyper-personalized proactive help. (Blog, X Announcement)* Partnerships & Drama* Apple + Gemini - Apple officially selects Gemini to power Siri backend capabilities.* OpenAI + Cerebras - A $10B deal for 750MW of high-speed compute through 2028. (Announcement)* Thinking Machines - Co-founders and CTO return to OpenAI amidst drama; Soumith Chintala named new CTO.* This Week’s Buzz* WeaveHacks 3 - Self-Improving Agents Hackathon in SF (Jan 31-Feb 1). (Sign Up Here)* Vision, Voice & Audio* Veo 3.1 - Native 9:16 vertical video, 4K resolution, and reference image support in Gemini API. (Docs)* Pocket TTS - A 100M parameter CPU-only model from Kyutai Labs that clones voices from 5s of audio. (GitHub, HF)* GLM-Image - Hybrid AR + Diffusion model with SOTA text rendering. (HF, GitHub)* FLUX.2 [klein] - Black Forest Labs releases fast 4B (Apache 2.0) and 9B models for sub-second image gen. (HF Collection, X Announcement)* Kling Motion Transfer - Viral example of AI video pipelines changing Hollywood workflows. (X Thread)* Deep Dive: Agent Skills* Vercel React Best Practices - Pre-packaged skills for agents. (Blog)* UI Skills - Documentation and skill standards. (Docs)* Chorus with Skills - My fork of Chorus enabling skills for all LLMs. (Release) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 41m 02s | ||||||
| 1/8/26 |  ThursdAI - Jan 8 - Vera Rubin's 5x Jump, Ralph Wiggum Goes Viral, GPT Health Launches & XAI Raises $20B Mid-Controversy | Hey folks, Alex here from Weights & Biases, with your weekly AI update (and a first live show of this year!) For the first time, we had a co-host of the show also be a guest on the show, Ryan Carson (from Amp) went supernova viral this week with an X article (1.5M views) about Ralph Wiggum (yeah, from Simpsons) and he broke down that agentic coding technique at the end of the show. LDJ and Nisten helped cover NVIDIA’s incredible announcements during CES with their Vera Rubin upcoming platform (4-5X improvements) and we all got excited about AI medicine with ChatGPT going into Health officially! Plus, a bunch of Open Source news, let’s get into this: ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source: The “Small” Models Are WinningWe often talk about the massive frontier models, but this week, Open Source came largely from unexpected places and focused on efficiency, agents, and specific domains.Solar Open 100B: A Data MasterclassUpstage released Solar Open 100B, and it’s a beast. It’s a 102B parameter Mixture-of-Experts (MoE) model, but thanks to MoE magic, it only uses about 12B active parameters during inference. This means it punches incredibly high but runs fast.What I really appreciated here wasn’t just the weights, but the transparency. They released a technical report detailing their “Data Factory” approach. They trained on nearly 20 trillion tokens, with a huge chunk being synthetic. They also used a dynamic curriculum that adjusted the difficulty and the ratio of synthetic data as training progressed. This transparency is what pushes the whole open source community forward.Technically, it hits 88.2 on MMLU and competes with top-tier models, especially in Korean language tasks. You can grab it on Hugging Face.MiroThinker 1.5: The DeepSeek Moment for Agents?We also saw MiroThinker 1.5, a 30B parameter model that is challenging the notion that you need massive scale to be smart. It uses something they call “Interactive Scaling.”Wolfram broke this down for us: this agent forms hypotheses, searches for evidence, and then iteratively revises its answers in a time-sensitive sandbox. It effectively “thinks” before answering. The result? It beats trillion-parameter models on search benchmarks like BrowseComp. It’s significantly cheaper to run, too. This feels like the year where smaller models + clever harnesses (harnesses are the software wrapping the model) will outperform raw scale.Liquid AI LFM 2.5: Running on Toasters (Almost)We love Liquid AI and they are great friends of the show. They announced LFM 2.5 at CES with AMD, and these are tiny ~1B parameter models designed to run on-device. We’re talking about running capable AI on your laptop, your phone, or edge devices (or the Reachy Mini bot that I showed off during the show! I gotta try and run LFM on him!)Probably the coolest part is the audio model. Usually, talking to an AI involves a pipeline: Speech-to-Text (ASR) -> LLM -> Text-to-Speech (TTS). Liquid’s model is end-to-end. It hears audio and speaks audio directly. We watched a demo from Maxime Labonne where the model was doing real-time interaction, interleaving text and audio. It’s incredibly fast and efficient. While it might not write a symphony for you, for on-device tasks like summarization or quick interactions, this is the future.NousCoder-14B and Zhipu AI IPOA quick shoutout to our friends at Nous Research who released NousCoder-14B, an open-source competitive programming model that achieved a 7% jump on LiveCodeBench accuracy in just four days of RL training on 48 NVIDIA B200 GPUs. The model was trained on 24,000 verifiable problems, and the lead researcher Joe Li noted it achieved in 4 days what took him 2 years as a teenager competing in programming contests. The full RL stack is open-sourced on GitHub and Nous published a great WandB results page as well! And in historic news, Zhipu AI (Z.ai)—the folks behind the GLM series—became the world’s first major LLM company to IPO, raising $558 million on the Hong Kong Stock Exchange. Their GLM-4.7 currently ranks #1 among open-source and domestic models on both Artificial Analysis and LM Arena. Congrats to them!Big Companies & APIsNVIDIA CES: Vera Rubin Changes EverythingLDJ brought the heat on this one covering Jensen’s CES keynote that unveiled the Vera Rubin platform, and the numbers are almost hard to believe. We’re talking about a complete redesign of six chips: the Rubin GPU delivering 50 petaFLOPS of AI inference (5x Blackwell), the Vera CPU with 88 custom Olympus ARM cores, NVLink 6, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet.Let me put this in perspective using LDJ’s breakdown: if you look at FP8 performance, the jump from Hopper to Blackwell was about 5x. The jump from Blackwell to Vera Rubin is over 3x again—but here’s the kicker—while only adding about 200 watts of power draw. That’s insane efficiency improvement.The real-world implications Jensen shared: training a 10 trillion parameter mixture-of-experts model now requires 75% fewer GPUs compared to Blackwell. Inference token costs drop roughly 10x—a 1MW cluster goes from 1 million to 10 million tokens per second at the same power. HBM4 memory delivers 22 TB/s bandwidth with 288GB capacity, exceeding NVIDIA’s own 2024 projections by nearly 70%.As Ryan noted, when people say there’s an AI bubble, this is why it’s hilarious. Jensen keeps saying the need for inference is unbelievable and only going up exponentially. We all see this. I can’t get enough inference—I want to spin up 10 Ralphs running concurrently! The NVL72 rack-scale system achieves 3.6 exaFLOPS inference with 20.7TB total HBM, and it’s already shipping. Runway 4.5 is already running on the new platform, having ported their model from Hopper to Vera Rubin NVL72 in a single day.NVIDIA also recently acqui-hidred Groq (with a Q) in a ~$20 billion deal, bringing the inference chip expertise from the guy who created Google’s TPUs in-house.Nemotron Speech ASR & The Speed of Voice (X, HF, Blog)NVIDIA also dropped Nemotron Speech ASR. This is a 600M parameter model that offers streaming transcription with 24ms latency.We showed a demo from our friend Kwindla Kramer at Daily. He was talking to an AI, and the response was virtually instant. The pipeline is: Nemotron (hearing) -> Llama/Nemotron Nano (thinking) -> Magpie TTS (speaking). The total latency is under 500ms. It feels like magic. Instant voice agents are going to be everywhere this year.XAI Raises $20B While Grok Causes Problems (Again)So here’s the thing about covering anything Elon-related: it’s impossible to separate signal from noise because there’s an army of fans who hype everything and an army of critics who hate everything. But let me try to be objective here.XAI raised another massive Round E of $20 billion! at a $230 billion valuation, with NVIDIA and Cisco as strategic investors. The speed of their infrastructure buildout is genuinely incredible. Grok’s voice mode is impressive. I use Grok for research and it’s really good, notable for it’s unprecedented access to X !But. This raise happened in the middle of a controversy where Grok’s image model was being used to “put bikinis” on anyone in reply threads, including—and this is where I draw a hard line—minors. As Nisten pointed out on the show, it’s not even hard to implement guardrails. You just put a 2B VL model in front and ask “is there a minor in this picture?” But people tested it, asked Grok not to use the feature, and it did it anyway. And yeah, putting Bikini on Claude is funny, but basic moderation is lacking! The response of “we’ll prosecute illegal users” is stupid when there’s no moderation built into the product. There’s an enormous difference between Photoshop technically being able to do something after hours of work, and a feature that generates edited images in one second as the first comment to a celebrity, then gets amplified by the platform’s algorithm to millions of people. One is a tool. The other is a product with amplification mechanics. Products need guardrails. I don’t often link to CNN (in fact this is the first time) but they have a great writeup about the whole incident here which apparently includes the quitting of a few trust and safety folks and Elon’s pushback on guardrails. CrazyThat said, Grok 5 is in training and XAI continues to ship impressive technology. I just wish they’d put the same engineering effort into safety as they do into capabilities!OpenAI Launches GPT HealthThis one’s exciting. OpenAI CEO Fidji Simo announced ChatGPT Health, a privacy-first space for personalized health conversations that can connect to electronic health records, Apple Health, Function Health, Peloton, and MyFitnessPal.Here’s why this matters: health already represents about 5% of all ChatGPT messages globally and touches 25% of weekly active users—often outside clinic hours or in underserved areas. People are already using these models for health advice constantly.Nisten, who has worked on AI doctors since the GPT-3 days and even published papers on on-device medical AI, gave us some perspective: the models have been fantastic for health stuff for two years now. The key insight is that medical data seems like a lot, but there are really only about 2,000 prescription drugs and 2,000 diseases (10,000 if you count rare ones). That’s nothing for an LLM. The models excel at pattern recognition across this relatively contained dataset.The integration with Function Health is particularly interesting to me. Function does 160+ lab tests, but many doctors won’t interpret them because they didn’t order them. ChatGPT could help bridge that gap, telling you “hey, this biomarker looks off, you should discuss this with your doctor.” The bad news is, this is just a waitlist and you can add yourself to the waitlist here, we’ll keep monitoring the situation and let you know when it opens upDoctronic: AI Prescribing Without Physician OversightSpeaking of healthcare, Doctronic launched a pilot in Utah where AI can autonomously renew prescriptions for chronic conditions without any physician in the loop. The system covers about 190 routine medications (excluding controlled substances) at just $4 per renewal. Trial data showed 99.2% concordance with physician treatment plans, and they’ve secured pioneering malpractice insurance that treats the AI like a clinician.Nisten made the case that it’s ethically wrong to delay this kind of automation when ER wait times keep increasing and doctors are overworked. The open source models are already excellent at medical tasks. Governments should be buying GPUs rather than creating administrative roadblocks. Strong strong agree here! Google Brings Gmail into the Gemini Era (X)Breaking news from the day of our show: Google announced Gmail’s biggest AI transformation since its 2004 launch, powered by Gemini 3. This brings AI Overviews that summarize email threads, natural language queries (”Who gave me a plumber quote last year?”), Help Me Write, contextual Suggested Replies matching your writing style, and the upcoming AI Inbox that filters noise to surface VIPs and urgent items.For 3 billion Gmail users, this is huge. I’m very excited to test it—though not live on the show because I don’t want you reading my emails.This weeks buzz - covering Weights & Biases updatesNot covered on the show, but a great update on stuff from WandB, Chris Van Pelt (@vanpelt), one of the 3 co-founders released a great project I wanted to tell you about! For coders, this is an app that allows you to run multiple Claude Codes on free Github sandboxes, so you can code (or Ralph) and control everything away from home! GitHub gives personal users 120 free Codespaces hours/month, and Catnip automatically shuts down inactive instances so you can code for quite a while with Catnip! It’s fully open source on Github and you can download the app hereInterview: Ryan Carson - What the hell is Ralph Wiggum?Okay, let’s talk about the character everyone is seeing on their timeline: Ralph Wiggum. My co-host Ryan Carson went viral this week with an article about this technique, and I had to have him break it down.Ralph isn’t a new model; it’s a technique for running agents in a loop to perform autonomous coding. The core idea is deceptively simple: Ralph is a bash script that loops an AI coding agent. In a loop, until it a certain condition is met. But why is it blowing up? Normally when you use a coding agent like Cursor, Claude Code, or AMP, you need to be in the loop. You approve changes, look at code, fix things when the agent hits walls or runs out of context. Ralph solves this by letting the agent run autonomously while you sleep.Here’s how it works: First, you write a Product Requirements Doc (PRD) by talking to your agent for a few minutes about what you want to build. Then you convert that PRD into a JSON file containing atomic user stories with clear acceptance criteria. Each user story is small enough for the agent to complete in one focused thread.The Ralph script then loops: it picks the first incomplete user story, the agent writes code to implement it, tests against the acceptance criteria, commits the changes, marks the story as complete, writes what it learned to a shared “agents.md” file, and loops to the next story. That compound learning step is crucial—without it, the agent would keep making the same mistakes.What makes this work is the pre-work. As Ryan put it, “no real work is done one-shot.” This is how software engineering has always worked—you break big problems into smaller problems into user stories and solve them incrementally. The innovation is letting AI agents work through that queue autonomously while you sleep! Ryan’s excellent (and viral) X article is here! Vision & VideoLTX-2 Goes Fully Open Source (HF, Paper)Lightricks finally open-sourced LTX-2, marking a major milestone as the first fully open audio-video generation model. This isn’t just “we released the weights” open—it’s complete model weights (13B and 2B variants), distilled versions, controllable LoRAs, a full multimodal trainer, benchmarks, and evaluation scripts. For a video model that is aiming to be the open source SORA, supports audio and lipsyncThe model generates synchronized audio and video in a single DiT-based architecture—motion, dialogue, ambience, and music flow simultaneously. Native 4K at up to 50 FPS with audio up to 10 seconds. And there’s also a distilled version (Thanks Pruna AI!) hosted on ReplicateComfyUI provided day-0 native support, and community testing shows an A6000 generating 1280x720 at 120 frames in 50 seconds. This is near Sora-level quality that you can fine-tune on your own data for custom styles and voices in about an hour.What a way to start 2026. From chips that are 5x faster to AI doctors prescribing meds in Utah, the pace is only accelerating. If anyone tells you we’re in an AI bubble, just show them what we covered today. Even if the models stopped improving tomorrow, the techniques like “Ralph” prove we have years of work ahead of us just figuring out how to use the intelligence we already have.Thank you for being a ThursdAI subscriber. See you next week!As always, here’s the show notes and TL;DR links: * Hosts & Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co-Hosts - @WolframRvnwlf, @nisten, @ldjconfirmed* Special Guest - Ryan Carson (@ryancarson) breaking down the Ralph Wiggum technique.* Open Source LLMs* Solar Open 100B - Upstage’s 102B MoE model. Trained on 19.7T tokens with a heavy focus on “data factory” synthetic data and high-performance Korean reasoning (X, HF, Tech Report).* MiroThinker 1.5 - A 30B parameter search agent that uses “Interactive Scaling” to beat trillion-parameter models on search benchmarks like BrowseComp (X, HF, GitHub).* Liquid AI LFM 2.5 - A family of 1B models designed for edge devices. Features a revolutionary end-to-end audio model that skips the ASR-LLM-TTS pipeline (X, HF).* NousCoder-14B - competitive coding model from Nous Research that saw a 7% LiveCodeBench accuracy jump in just 4 days of RL (X, WandB Dashboard).* Zhipu AI IPO - The makers of GLM became the first major LLM firm to go public on the HKEX, raising $558M (Announcement).* Big Co LLMs & APIs* NVIDIA Vera Rubin - Jensen Huang’s CES reveal of the next-gen platform. Delivers 5x Blackwell inference performance and 75% fewer GPUs needed for MoE training (Blog).* OpenAI ChatGPT Health - A privacy-first vertical for EHR and fitness data integration (Waitlist).* Google Gmail Era - Gemini 3 integration into Gmail for 3 billion users, featuring AI Overviews and natural language inbox search (Blog).* XAI $20B Raise - Elon’s XAI raises Series E at a $230B valuation, even as Grok faces heat over bikini-gate and safety guardrails (CNN Report).* Doctronic - The first US pilot in Utah for autonomous AI prescription renewals without a physician in the loop (Web).* Alexa+ Web - Amazon brings the “Smart Alexa” experience to browser-based chat (Announcement).* Autonomous Coding & Tools* Ralph Wiggum - The agentic loop technique for autonomous coding using small, atomic user stories. Ryan Carson’s breakdown of why this is the death of “vibe coding” (Viral X Article).* Catnip by W&B - Chris Van Pelt’s open-source iOS app to run Claude Code anywhere via GitHub Codespaces (App Store, GitHub).* Vision & Video* LTX-2 - Lightricks open-sources the first truly open audio-video generation model with synchronized output and full training code (GitHub, Replicate Demo).* Avatar Forcing - KAIST’s framework for real-time interactive talking heads with ~500ms latency (Arxiv).* Qwen Edit 2512 - Optimized by PrunaAI to generate high-res realistic images in under 7 seconds (Replicate).* Voice & Audio* Nemotron Speech ASR - NVIDIA’s 600M parameter streaming model with sub-100ms stable latency for massive-scale voice agents (HF). This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 1h 46m 57s | ||||||
| 1/1/26 |  ThursdAI - Jan 1 2026 - Will Brown Interview + Nvidia buys Groq, Meta buys Manus, Qwen Image 2412 & Alex New Year greetings | Hey all, Happy new year! This is Alex, writing to you for the very fresh start of this year, it’s 2026 already, can you believe it? There was no live stream today, I figured the cohosts deserve a break and honestly it was a very slow week. Even the chinese labs who don’t really celebrate X-mas and new years didn’t come out with a banger AFAIK. ThursdAI - AI moves fast, we’re here to make sure you never miss a thing! Subscribe :) Tho I thought it was an incredible opportunity to finally post the Will Brow interview I recorded in November during the AI Engineer conference. Will is a researcher at Prime Intellect (big fans on WandB btw!) and is very known on X as a hot takes ML person, often going viral for tons of memes! Will is the creator and maintainer of the Verifiers library (Github) and his talk at AI Engineer was all about RL Environments (what they are, you can hear in the interview, I asked him!) TL;DR last week of 2025 in AIBesides this, my job here is to keep you up to date, and honestly this was very easy this week, as… almost nothing has happened, but here we go: Meta buys ManusThe year ended with 2 huge acquisitions / aquihires. First we got the news from Alex Wang that Meta has bought Manus.ai which is an agentic AI startup we covered back in March for an undisclosed amount (folks claim $2-3B) The most interesting thing here is that Manus is a Chinese company, and this deal requires very specific severance from Chinese operations.Jensen goes on a new years spending spree, Nvidia buys Groq (not GROK) for $20BGroq which we covered often here, and are great friends, is going to NVIDIA, in a… very interesting acqui-hire, which is a “non binding license” + most of Groq top employees apparently are going to NVIDIA. Jonathan Ross the CEO of Groq, was the co-creator of the TPU chips at Google before founding Groq, so this seems like a very strategic aquihire for NVIDIA! Congrats to our friends from Groq on this amazing news for the new year! Tencent open-sources HY-MT1.5 translation models with 1.8B edge-deployable and 7B cloud variants supporting 33 languages (X, HF, HF, GitHub)It seems that everyone’s is trying to de-throne whisper and this latest attempt from Tencent is a interesting one. a 1.8B and 7B translation models with very interesting stats. Alibaba’s Qwen-Image-2512 drops on New Year’s Eve as strongest open-source text-to-image model, topping AI Arena with photorealistic humans and sharper textures (X, HF, Arxiv)Our friends in Tongyi decided to give is a new years present in the form of an updated Qwen-image, with much improved realismThat’s it folks, this was a quick one, hopefully you all had an amazing new year celebration, and are gearing up to an eventful and crazy 2026. I wish you all happiness, excitement and energy to keep up with everything in the new year, and will make sure that we’re here to keep you up to date as always! P.S - I got a little news of my own this yesterday, not related to AI. She said yes 🎉 This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe | 29m 42s | ||||||
Showing 25 of 161
Pitch Fit is a Pro feature
See how bookable this show is for guests, which brands already advertise, the per-episode ad value, and the best-fit guest and sponsor profile. The numbers are blurred on the free plan.
How readily this show books outside guests like you.
How proven this show is for host-read sponsorships.
For Guests
ProFor Advertisers
ProUpgrade to Pro to unlock guest cadence, sponsor categories, fit scores, and per-episode ad value for this show.
Chart Positions
26 placements across 26 markets.
Chart Positions
26 placements across 26 markets.