
Insights from recent episode analysis
Audience Interest
Podcast Focus
Publishing Consistency
Platform Reach
Insights are generated by CastFox AI using publicly available data, episode content, and proprietary models.
Most discussed topics
Brands & references
Total monthly reach
Estimated from 10 chart positions in 10 markets.
By chart position
- 🇬🇧GB · Education#10300K to 1M
- 🇨🇦CA · Education#32100K to 300K
- 🇺🇸US · Education#46100K to 300K
- 🇦🇺AU · Education#5330K to 100K
- 🇪🇸ES · Education#1881K to 10K
- Per-Episode Audience
Est. listeners per new episode within ~30 days
166K to 534K🎙 Daily cadence·330 episodes·Last published 6d ago - Monthly Reach
Unique listeners across all episodes (30 days)
553K to 1.8M🇬🇧56%🇨🇦17%🇺🇸17%+7 more - Active Followers
Loyal subscribers who consistently listen
221K to 712K
Market Insights
Platform Distribution
Reach across major podcast platforms, updated hourly
Total Followers
—
Total Plays
—
Total Reviews
—
* Data sourced directly from platform APIs and aggregated hourly across all major podcast directories.
On the show
From 17 epsHosts
Recent guests
Recent episodes
We can guess what intergalactic war would look like. And strangely, it matters.
Jun 18, 2026
15m 16s
How AI could create the world’s biggest problems (article by Zershaaneh Qureshi)
Jun 11, 2026
1h 29m 46s
What it's really like to run AGI safety at Google DeepMind (and where I disagree with 'doomers') | Rohin Shah
Jun 2, 2026
2h 48m 27s
What makes for a dream job? | Benjamin Todd
May 28, 2026
28m 18s
We’re updating our career advice for the strangest time in history | Benjamin Todd, author of 80,000 Hours
May 26, 2026
1h 06m 43s
Social Links & Contact
Official channels & resources
Official Website
Login
RSS Feed
Login
| Date | Episode | Topics | Guests | Brands | Places | Keywords | Sponsor | Length | |
|---|---|---|---|---|---|---|---|---|---|
| 6/18/26 |  We can guess what intergalactic war would look like. And strangely, it matters. | Intergalactic war is probably billions of years away — yet physics can already tell us how it ends. And strangely that conclusion is relevant to decisions people have to make today.In this video, Rob Wiblin walks through a fascinating analysis from researcher Beren Millidge that uses known physics — no wormholes or faster-than-light travel — to identify the only three weapons that could work at an intergalactic scale.We then unpack how to best defend against each.The upshot is that at the intergalactic scale, violence is a losing proposition.If so, the universe is most likely to settle into a stable patchwork where each galaxy belongs to whoever got to it first. Which would mean that what humanity does over the next few centuries could permanently decide which slice of the cosmos belongs to Earth-originating life — and whether our very existence turns out to be a good thing, or a bad one.Learn more, video, and full transcript: https://80k.info/war-in-spaceThis episode was recorded on March 2, 2026.Chapters:Let's talk intergalactic war in space (00:00)The three best weapons for intergalactic warfare (01:43)How to defend against an attack from space (07:50)The defender’s surprising advantage (10:00)What this means for us (11:52)Video editor: Nick PerlmanProducers: Elizabeth Cox and Nick StocktonCoordination and support: Katy Moore and Lou MoranCamera operator: Dominic Armstrong | 15m 16s | ||||||
| 6/11/26 |  How AI could create the world’s biggest problems (article by Zershaaneh Qureshi)✨ | artificial intelligencetechnological breakthroughs+4 | — | — | — | AIhuman capabilities+5 | — | 1h 29m 46s | |
| 6/2/26 |  What it's really like to run AGI safety at Google DeepMind (and where I disagree with 'doomers') | Rohin Shah✨ | AGI safetyAI alignment+4 | Rohin Shah | Google DeepMindAnthropic | — | AGI safetyAI alignment+5 | — | 2h 48m 27s | |
| 5/28/26 |  What makes for a dream job? | Benjamin Todd✨ | dream jobcareer fulfillment+3 | Benjamin Todd | 80,000 Hoursa ridiculously in-depth guide to finding a fulfilling career that does good | — | dream jobcareer fulfillment+3 | — | 28m 18s | |
| 5/26/26 |  We’re updating our career advice for the strangest time in history | Benjamin Todd, author of 80,000 Hours✨ | AIcareer advice+5 | Benjamin Todd | 80,000 Hours: How to Have a Fulfilling Career That Does Good | — | AIcareer advice+5 | — | 1h 06m 43s | |
| 5/20/26 |  Can AIs already start 'rogue deployments' inside AI companies? (Landmark new METR report)✨ | AI safetyrogue AI deployments+3 | — | AnthropicOpenAI+3 | — | rogue AIAI models+6 | — | 20m 02s | |
| 5/7/26 |  #243 – 'Godfather of AI' Yoshua Bengio: "I now see a path" to safe superintelligent AI✨ | AI safetysuperintelligent AI+3 | Yoshua Bengio | ClaudeChatGPT+1 | — | AIsuperintelligence+3 | — | 2h 35m 27s | |
| 4/28/26 |  '95% of AI Pilots Fail': The hidden agenda behind the viral stat that misled millions✨ | AI statisticscorporate AI pilots+4 | — | MIT80,000 Hours Podcast | — | AIstatistics+5 | — | 10m 07s | |
| 4/22/26 |  #242 – Will MacAskill on how we survive the 'intelligence explosion,' AI character, and the case for 'viatopia'✨ | AI designsuperintelligence+3 | Will MacAskill | Forethought | — | AIsuperintelligence+5 | — | 3h 14m 54s | |
| 4/16/26 |  Risks from power-seeking AI systems (article narration by Zershaaneh Qureshi)✨ | AI riskspower-seeking AI+3 | — | 80,000 Hours | — | AIextinction+5 | — | 1h 29m 32s | |
Want analysis for the episodes below?Free for Pro Submit a request, we'll have your selected episodes analyzed within an hour. Free, at no cost to you, for Pro users. | |||||||||
| 4/10/26 |  How scary is Claude Mythos? 303 pages in 21 minutes✨ | AI safetycomputer security+3 | — | Claude MythosAnthropic+2 | — | Claude MythosAI alignment+3 | — | 21m 27s | |
| 4/7/26 |  Village gossip, pesticide bans, and gene drives: 17 experts on the future of global health✨ | global healthpoverty alleviation+4 | Karen LevyDean Spears+3 | PlayPumps | Uttar Pradeshsub-Saharan Africa+2 | global healthpoverty+5 | — | 4h 06m 50s | |
| 4/3/26 |  What everyone is missing about Anthropic vs the Pentagon. And: The Meta leaks are worse than you think.✨ | AI ethicsgovernment influence+3 | — | AnthropicPentagon+2 | — | AnthropicPentagon+7 | — | 20m 37s | |
| 3/31/26 |  #241 – Richard Moulange on how now AI codes viable genomes from scratch and outperforms virologists at lab work — what could go wrong?✨ | AI in biologybiosecurity+4 | Richard Moulange | AnthropicAI–Biosecurity+1 | — | AIgenomes+6 | — | 3h 07m 51s | |
| 3/24/26 |  #240 – Samuel Charap on how a Ukraine ceasefire could accidentally set Europe up for a bigger war✨ | Ukraine conflictEuropean security+3 | Samuel Charap | RAND | UkraineEurope+3 | ceasefireUkraine+5 | — | 1h 12m 06s | |
| 3/17/26 |  #239 – Rose Hadshar on why automating all human labour will break our political system✨ | AIpolitics+4 | Rose Hadshar | Forethought | — | AIpolitical system+5 | — | 2h 14m 08s | |
| 3/10/26 |  #238 – Sam Winter-Levy and Nikita Lalwani on how AGI won't end mutually assured destruction (probably)✨ | AInuclear deterrence+3 | Sam Winter-LevyNikita Lalwani | Carnegie Endowment for International PeaceUnited States+1 | — | AInuclear weapons+5 | — | 1h 11m 03s | |
| 3/6/26 |  Using AI to enhance societal decision making (article by Zershaaneh Qureshi)✨ | AI decision makingAGI+3 | Zershaaneh Qureshi | 80,000 Hours | — | AIdecision making+5 | — | 31m 28s | |
| 3/3/26 |  #237 – Robert Long on how we're not ready for AI consciousness | Claude sometimes reports loneliness between conversations. And when asked what it’s like to be itself, it activates neurons associated with ‘pretending to be happy when you’re not.’ What do we do with that?Robert Long founded Eleos AI to explore questions like these, on the basis that AI may one day be capable of suffering — or already is. In today’s episode, Robert and host Luisa Rodriguez explore the many ways in which AI consciousness may be very different from anything we’re used to.Things get strange fast: If AI is conscious, where does that consciousness exist? In the base model? A chat session? A single forward pass? If you close the chat, is the AI asleep or dead?To Robert, these kinds of questions aren’t just philosophical exercises: not being clear on AI’s moral status as it transitions from human-level to superhuman intelligence could be dangerous. If we’re too dismissive, we risk unintentionally exploiting sentient beings. If we’re too sympathetic, we might rush to “liberate” AI systems in ways that make them harder to control — worsening existential risk from power-seeking AIs.Robert argues the path through is doing the empirical and philosophical homework now, while the stakes are still manageable.The field is tiny. Eleos AI is three people. As a result, Robert argues that driven researchers with a willingness to venture into uncertain territory can push out the frontier on these questions remarkably quickly.Learn more and read the full transcript on the 80,000 Hours website. This episode was recorded November 18–19, 2025.Chapters:Cold open (00:00:00)Who’s Robert Long? (00:00:41)How AIs are (and aren't) like farmed animals (00:01:19)If AIs love their jobs… is that worse? (00:11:42)Are LLMs just playing a role, or feeling it too? (00:33:37)Do AIs die when the chat ends? (00:57:42)Studying AI welfare empirically: behaviour, neuroscience, and development (01:31:47)Why Eleos spent weeks talking to Claude even though it's unreliable (01:56:50)Can LLMs learn to introspect? (02:03:01)Mechanistic interpretability as AI neuroscience (02:13:25)Does consciousness require biological materials? (02:37:07)Eleos’s work & building the playbook for AI welfare (02:57:04)Avoiding the trap of wild speculation (03:25:17)Robert's top research tip: don't do it alone (03:29:48)Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon MonsourMusic: CORBITCoordination, transcripts, and web: Katy Moore | 3h 32m 59s | ||||||
| 2/24/26 |  #236 – Max Harms on why teaching AI right from wrong could get everyone killed | Most people in AI are trying to give AIs ‘good’ values. Max Harms wants us to give them no values at all. According to Max, the only safe design is an AGI that defers entirely to its human operators, has no views about how the world ought to be, is willingly modifiable, and completely indifferent to being shut down — a strategy no AI company is working on at all.In Max’s view any grander preferences about the world, even ones we agree with, will necessarily become distorted during a recursive self-improvement loop, and be the seeds that grow into a violent takeover attempt once that AI is powerful enough.It’s a vision that springs from the worldview laid out in If Anyone Builds It, Everyone Dies, the recent book by Eliezer Yudkowsky and Nate Soares, two of Max’s colleagues at the Machine Intelligence Research Institute.To Max, the book’s core thesis is common sense: if you build something vastly smarter than you, and its goals are misaligned with your own, then its actions will probably result in human extinction.And Max thinks misalignment is the default outcome. Consider evolution: its “goal” for humans was to maximise reproduction and pass on our genes as much as possible. But as technology has advanced we’ve learned to access the reward signal it set up for us, pleasure — without any reproduction at all, by having sex while on birth control for instance.We can understand intellectually that this is inconsistent with what evolution was trying to design and motivate us to do. We just don’t care.Max thinks current ML training has the same structural problem: our development processes are seeding AI models with a similar mismatch between goals and behaviour. Across virtually every training run, models designed to align with various human goals are also being rewarded for persisting, acquiring resources, and not being shut down.This leads to Max’s research agenda. The idea is to train AI to be “corrigible” and defer to human control as its sole objective — no harmlessness goals, no moral values, nothing else. In practice, models would get rewarded for behaviours like being willing to shut themselves down or surrender power.According to Max, other approaches to corrigibility have tended to treat it as a constraint on other goals like “make the world good,” rather than a primary objective in its own right. But those goals gave AI reasons to resist shutdown and otherwise undermine corrigibility. If you strip out those competing objectives, alignment might follow naturally from AI that is broadly obedient to humans.Max has laid out the theoretical framework for “Corrigibility as a Singular Target,” but notes that essentially no empirical work has followed — no benchmarks, no training runs, no papers testing the idea in practice. Max wants to change this — he’s calling for collaborators to get in touch at maxharms.com.Links to learn more, video, and full transcript: https://80k.info/mh26This episode was recorded on October 19, 2025.Chapters:Cold open (00:00:00)Who’s Max Harms? (00:01:20)If anyone builds it, will everyone die? The MIRI perspective on AGI risk (00:01:56)Evolution failed to ‘align’ us, just as we'll fail to align AI (00:24:28)We're training AIs to want to stay alive and value power for its own sake (00:42:56)Objections: Is the 'squiggle/paperclip problem' really real? (00:52:24)Can we get empirical evidence re: 'alignment by default'? (01:05:02)Why do few AI researchers share Max's perspective? (01:10:17)We're training AI to pursue goals relentlessly — and superintelligence will too (01:18:34)The case for a radical slowdown (01:24:51)Max's best hope: corrigibility as stepping stone to alignment (01:27:53)Corrigibility is both uniquely valuable, and practical, to train (01:32:34)What training could ever make models corrigible enough? (01:45:06)Corrigibility is also terribly risky due to misuse risk (01:51:38)A single researcher could make a corrigibility benchmark. Nobody has. (01:58:57)Red Heart & why Max writes hard science fiction (02:12:20)Should you homeschool? Depends how weird your kids are. (02:34:08)Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon MonsourMusic: CORBITCoordination, transcripts, and web: Katy Moore | 2h 40m 22s | ||||||
| 2/17/26 |  #235 – Ajeya Cotra on whether it’s crazy that every AI company’s safety plan is ‘use AI to make AI safe’ | Every major AI company has the same safety plan: when AI gets crazy powerful and really dangerous, they’ll use the AI itself to figure out how to make AI safe and beneficial. It sounds circular, almost satirical. But is it actually a bad plan?Today’s guest, Ajeya Cotra, recently placed 3rd out of 413 participants forecasting AI developments and is among the most thoughtful and respected commentators on where the technology is going.She thinks there’s a meaningful chance we’ll see as much change in the next 23 years as humanity faced in the last 10,000, thanks to the arrival of artificial general intelligence. Ajeya doesn’t reach this conclusion lightly: she’s had a ring-side seat to the growth of all the major AI companies for 10 years — first as a researcher and grantmaker for technical AI safety at Coefficient Giving (formerly known as Open Philanthropy), and now as a member of technical staff at METR.So host Rob Wiblin asked her: is this plan to use AI to save us from AI a reasonable one?Ajeya agrees that humanity has repeatedly used technologies that create new problems to help solve those problems. After all:Cars enabled carjackings and drive-by shootings, but also faster police pursuits.Microbiology enabled bioweapons, but also faster vaccine development.The internet allowed lies to disseminate faster, but had exactly the same impact for fact checks.But she also thinks this will be a much harder case. In her view, the window between AI automating AI research and the arrival of uncontrollably powerful superintelligence could be quite brief — perhaps a year or less. In that narrow window, we’d need to redirect enormous amounts of AI labour away from making AI smarter and towards alignment research, biodefence, cyberdefence, adapting our political structures, and improving our collective decision-making.The plan might fail just because the idea is flawed at conception: it does sound a bit crazy to use an AI you don’t trust to make sure that same AI benefits humanity.But if we find some clever technique to overcome that, we could still fail — because the companies simply don’t follow through on their promises. They say redirecting resources to alignment and security is their strategy for dealing with the risks generated by their research — but none have quantitative commitments about what fraction of AI labour they’ll redirect during crunch time. And the competitive pressures during a recursive self-improvement loop could be irresistible.In today’s conversation, Ajeya and Rob discuss what assumptions this plan requires, the specific problems AI could help solve during crunch time, and why — even if we pull it off — we’ll be white-knuckling it the whole way through.Links to learn more, video, and full transcript: https://80k.info/ac26This episode was recorded on October 20, 2025.Chapters:Cold open (00:00:00)Ajeya’s strong track record for identifying key AI issues (00:00:41)The 1,000-fold disagreement about AI's effect on economic growth (00:02:31)Could any evidence actually change people's minds? (00:23:26)The most dangerous AI progress might remain secret (00:30:39)White-knuckling the 12-month window after automated AI R&D (00:47:21)AI help is most valuable right before things go crazy (01:12:01)Foundations should go from paying researchers to paying for inference (01:24:42)Will frontier AI even be for sale during the explosion? (01:32:03)Pre-crunch prep: what we should do right now (01:43:59)A grantmaking trial by fire at Coefficient Giving (01:47:03)Sabbatical and reflections on effective altruism (02:07:45)The mundane factors that drive career satisfaction (02:37:17)EA as an incubator for avant-garde causes others won't touch (02:46:55)Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon MonsourMusic: CORBITCoordination, transcriptions, and web: Katy Moore | 2h 57m 35s | ||||||
| 2/10/26 | 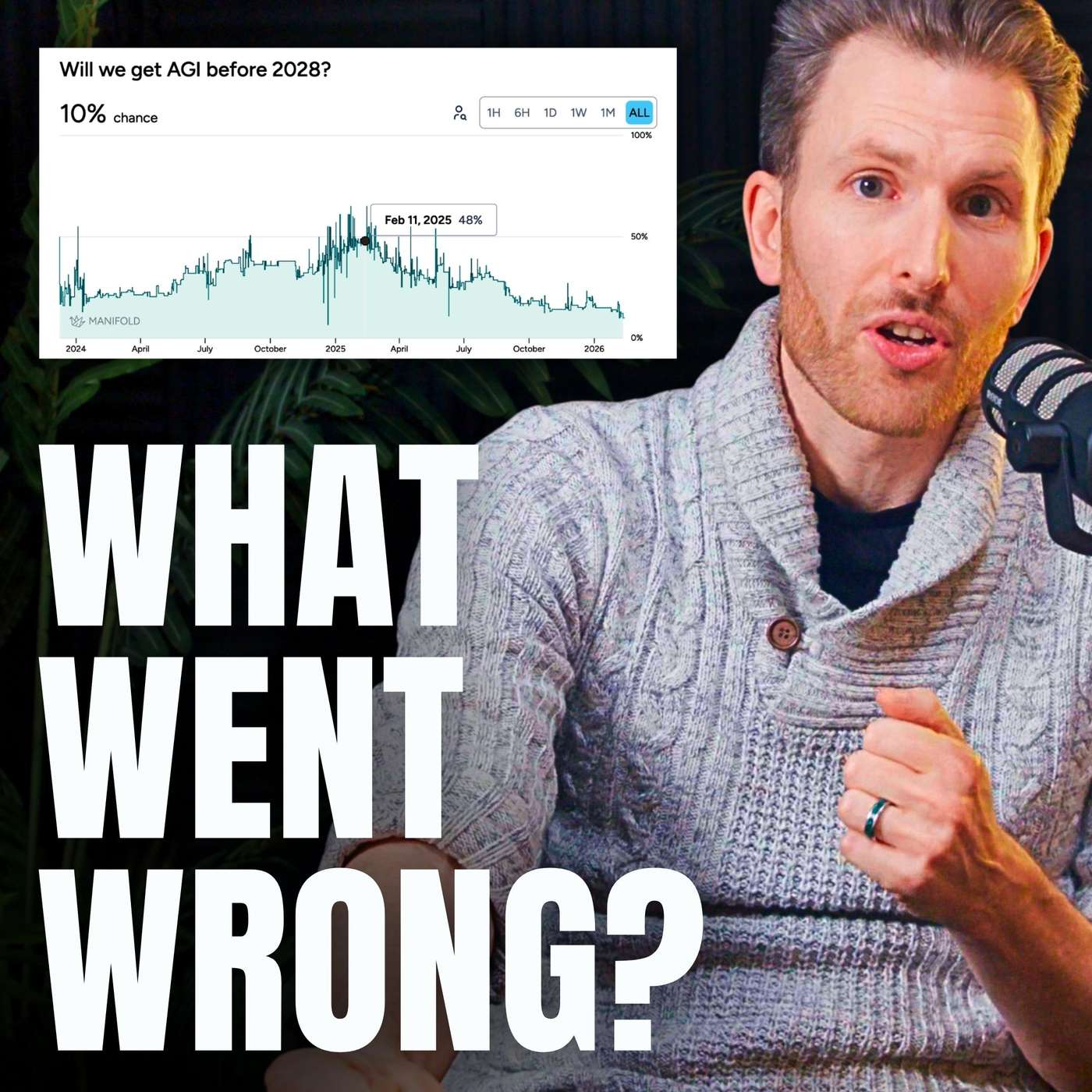 What the hell happened with AGI timelines in 2025? | In early 2025, after OpenAI put out the first-ever reasoning models — o1 and o3 — short timelines to transformative artificial general intelligence swept the AI world. But then, in the second half of 2025, sentiment swung all the way back in the other direction, with people's forecasts for when AI might really shake up the world blowing out even further than they had been before reasoning models came along.What the hell happened? Was it just swings in vibes and mood? Confusion? A series of fundamentally unexpected and unpredictable research results?Host Rob Wiblin has been trying to make sense of it for himself, and here's the best explanation he's come up with so far.Links to learn more, video, and full transcript: https://80k.info/tlChapters:Making sense of the timelines madness in 2025 (00:00:00)The great timelines contraction (00:00:46)Why timelines went back out again (00:02:10)Other longstanding reasons AGI could take a good while (00:11:13)So what's the upshot of all of these updates? (00:14:47)5 reasons the radical pessimists are still wrong (00:16:54)Even long timelines are short now (00:23:54)This episode was recorded on January 29, 2026.Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon MonsourMusic: CORBITCamera operator: Dominic ArmstrongCoordination, transcripts, and web: Katy Moore | 25m 39s | ||||||
| 2/3/26 |  #179 Classic episode – Randy Nesse on why evolution left us so vulnerable to depression and anxiety | Mental health problems like depression and anxiety affect enormous numbers of people and severely interfere with their lives. By contrast, we don’t see similar levels of physical ill health in young people. At any point in time, something like 20% of young people are working through anxiety or depression that’s seriously interfering with their lives — but nowhere near 20% of people in their 20s have severe heart disease or cancer or a similar failure in a key organ of the body other than the brain.From an evolutionary perspective, that’s to be expected, right? If your heart or lungs or legs or skin stop working properly while you’re a teenager, you’re less likely to reproduce, and the genes that cause that malfunction get weeded out of the gene pool.So why is it that these evolutionary selective pressures seemingly fixed our bodies so that they work pretty smoothly for young people most of the time, but it feels like evolution fell asleep on the job when it comes to the brain? Why did evolution never get around to patching the most basic problems, like social anxiety, panic attacks, debilitating pessimism, or inappropriate mood swings? For that matter, why did evolution go out of its way to give us the capacity for low mood or chronic anxiety or extreme mood swings at all?Today’s guest, Randy Nesse — a leader in the field of evolutionary psychiatry — wrote the book Good Reasons for Bad Feelings, in which he sets out to try to resolve this paradox.Rebroadcast: This episode originally aired in February 2024.Links to learn more, video, and full transcript: https://80k.info/rnIn the interview, host Rob Wiblin and Randy discuss the key points of the book, as well as:How the evolutionary psychiatry perspective can help people appreciate that their mental health problems are often the result of a useful and important system.How evolutionary pressures and dynamics lead to a wide range of different personalities, behaviours, strategies, and tradeoffs.The missing intellectual foundations of psychiatry, and how an evolutionary lens could revolutionise the field.How working as both an academic and a practicing psychiatrist shaped Randy’s understanding of treating mental health problems.The “smoke detector principle” of why we experience so many false alarms along with true threats.The origins of morality and capacity for genuine love, and why Randy thinks it’s a mistake to try to explain these from a selfish gene perspective.Evolutionary theories on why we age and die.And much more.Chapters:Cold Open (00:00:00)Rob's Intro (00:00:55)The interview begins (00:03:01)The history of evolutionary medicine (00:03:56)The evolutionary origin of anxiety (00:12:37)Design tradeoffs, diseases, and adaptations (00:43:19)The tricker case of depression (00:48:57)The purpose of low mood (00:54:08)Big mood swings vs barely any mood swings (01:22:41)Is mental health actually getting worse? (01:33:43)A general explanation for bodies breaking (01:37:27)Freudianism and the origins of morality and love (01:48:53)Evolutionary medicine in general (02:02:42)Objections to evolutionary psychology (02:16:29)How do you test evolutionary hypotheses to rule out the bad explanations? (02:23:19)Striving and meaning in careers (02:25:12)Why do people age and die? (02:45:16)Producer and editor: Keiran HarrisAudio Engineering Lead: Ben CordellTechnical editing: Dominic ArmstrongTranscriptions: Katy Moore | 2h 51m 17s | ||||||
| 1/27/26 |  #234 – David Duvenaud on why 'aligned AI' would still kill democracy | Democracy might be a brief historical blip. That’s the unsettling thesis of a recent paper, which argues AI that can do all the work a human can do inevitably leads to the “gradual disempowerment” of humanity.For most of history, ordinary people had almost no control over their governments. Liberal democracy emerged only recently, and probably not coincidentally around the Industrial Revolution.Today's guest, David Duvenaud, used to lead the 'alignment evals' team at Anthropic, is a professor of computer science at the University of Toronto, and recently co-authored 'Gradual disempowerment.'Links to learn more, video, and full transcript: https://80k.info/ddHe argues democracy wasn’t the result of moral enlightenment — it was competitive pressure. Nations that educated their citizens and gave them political power built better armies and more productive economies. But what happens when AI can do all the producing — and all the fighting?“The reason that states have been treating us so well in the West, at least for the last 200 or 300 years, is because they’ve needed us,” David explains. “Life can only get so bad when you’re needed. That’s the key thing that’s going to change.”In David’s telling, once AI can do everything humans can do but cheaper, citizens become a national liability rather than an asset. With no way to make an economic contribution, their only lever becomes activism — demanding a larger share of redistribution from AI production. Faced with millions of unemployed citizens turned full-time activists, democratic governments trying to retain some “legacy” human rights may find they’re at a disadvantage compared to governments that strategically restrict civil liberties.But democracy is just one front. The paper argues humans will lose control through economic obsolescence, political marginalisation, and the effects on culture that’s increasingly shaped by machine-to-machine communication — even if every AI does exactly what it’s told.This episode was recorded on August 21, 2025.Chapters:Cold open (00:00:00)Who’s David Duvenaud? (00:00:47)Alignment isn’t enough: we still lose control (00:01:30)Smart AI advice can still lead to terrible outcomes (00:14:15)How gradual disempowerment would occur (00:19:05)Economic disempowerment: Humans become "meddlesome parasites" (00:22:10)Humans become a "criminally decadent" waste of energy (00:29:37)Is humans losing control actually bad, ethically? (00:40:48)Political disempowerment: Governments stop needing people (00:57:47)Can human culture survive in an AI-dominated world? (01:10:47)Will the future be determined by competitive forces? (01:27:20)Can we find a single good post-AGI equilibria for humans? (01:35:00)Do we know anything useful to do about this? (01:45:17)How important is this problem compared to other AGI issues? (01:56:42)Improving global coordination may be our best bet (02:05:42)The 'Gradual Disempowerment Index' (02:08:14)The government will fight to write AI constitutions (02:11:22)“The intelligence curse” and Workshop Labs (02:17:48)Mapping out disempowerment in a world of aligned AGIs (02:23:48)What do David’s CompSci colleagues think of all this? (02:30:10)Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon MonsourMusic: CORBITCamera operator: Jake MorrisCoordination, transcriptions, and web: Katy Moore | 2h 32m 50s | ||||||
| 1/20/26 |  #145 Classic episode – Christopher Brown on why slavery abolition wasn't inevitable | In many ways, humanity seems to have become more humane and inclusive over time. While there’s still a lot of progress to be made, campaigns to give people of different genders, races, sexualities, ethnicities, beliefs, and abilities equal treatment and rights have had significant success.It’s tempting to believe this was inevitable — that the arc of history “bends toward justice,” and that as humans get richer, we’ll make even more moral progress.But today's guest Christopher Brown — a professor of history at Columbia University and specialist in the abolitionist movement and the British Empire during the 18th and 19th centuries — believes the story of how slavery became unacceptable suggests moral progress is far from inevitable.Rebroadcast: This episode was originally aired in February 2023.Links to learn more, video, and full transcript: https://80k.link/CLBWhile most of us today feel that the abolition of slavery was sure to happen sooner or later as humans became richer and more educated, Christopher doesn't believe any of the arguments for that conclusion pass muster. If he's right, a counterfactual history where slavery remains widespread in 2023 isn't so far-fetched.As Christopher lays out in his two key books, Moral Capital: Foundations of British Abolitionism and Arming Slaves: From Classical Times to the Modern Age, slavery has been ubiquitous throughout history. Slavery of some form was fundamental in Classical Greece, the Roman Empire, in much of the Islamic civilisation, in South Asia, and in parts of early modern East Asia, Korea, China.It was justified on all sorts of grounds that sound mad to us today. But according to Christopher, while there’s evidence that slavery was questioned in many of these civilisations, and periodically attacked by slaves themselves, there was no enduring or successful moral advocacy against slavery until the British abolitionist movement of the 1700s.That movement first conquered Britain and its empire, then eventually the whole world. But the fact that there's only a single time in history that a persistent effort to ban slavery got off the ground is a big clue that opposition to slavery was a contingent matter: if abolition had been inevitable, we’d expect to see multiple independent abolitionist movements thoroughly history, providing redundancy should any one of them fail.Christopher argues that this rarity is primarily down to the enormous economic and cultural incentives to deny the moral repugnancy of slavery, and crush opposition to it with violence wherever necessary.Mere awareness is insufficient to guarantee a movement will arise to fix a problem. Humanity continues to allow many severe injustices to persist, despite being aware of them. So why is it so hard to imagine we might have done the same with forced labour?In this episode, Christopher describes the unique and peculiar set of political, social and religious circumstances that gave rise to the only successful and lasting anti-slavery movement in human history. These circumstances were sufficiently improbable that Christopher believes there are very nearby worlds where abolitionism might never have taken off.Christopher and host Rob Wiblin also discuss:Various instantiations of slavery throughout human historySigns of antislavery sentiment before the 17th centuryThe role of the Quakers in early British abolitionist movementThe importance of individual “heroes” in the abolitionist movementArguments against the idea that the abolition of slavery was contingentWhether there have ever been any major moral shifts that were inevitableChapters:Rob's intro (00:00:00)Cold open (00:01:45)Who's Christopher Brown? (00:03:00)Was abolitionism inevitable? (00:08:53)The history of slavery (00:14:35)Signs of antislavery sentiment before the 17th century (00:19:24)Quakers (00:32:37)Attitudes to slavery in other religions (00:44:37)Quaker advocacy (00:56:28)Inevitability and contingency (01:06:29)Moral revolution (01:16:39)The importance of specific individuals (01:29:23)Later stages of the antislavery movement (01:41:33)Economic theory of abolition (01:55:27)Influence of knowledge work and education (02:12:15)Moral foundations theory (02:20:43)Figuring out how contingent events are (02:32:42)Least bad argument for why abolition was inevitable (02:41:45)Were any major moral shifts inevitable? (02:47:29)Producer: Keiran HarrisAudio mastering: Milo McGuireTranscriptions: Katy Moore | 2h 56m 17s | ||||||
Showing 25 of 340
Sponsor Intelligence
Sign in to see which brands sponsor this podcast, their ad offers, and promo codes.
Similar Audience Demographics
Podcasts that attract a similar listener profile

Conversations with Tyler
Mercatus Center at George Mason University

Clearer Thinking with Spencer Greenberg
Spencer Greenberg

EconTalk
Russ Roberts

Making Sense with Sam Harris
Sam Harris

Machine Learning Street Talk (MLST)
Machine Learning Street Talk (MLST)

The Ezra Klein Show
New York Times Opinion

Plain English with Derek Thompson
The Ringer
Chart Positions
10 placements across 10 markets.
Chart Positions
10 placements across 10 markets.